
Kernel-Level Exception Handling
A Linux system consists of the kernel and an assorted collection of user applications. The user applications communicate with the kernel through system calls. System calls are entry points into the Linux kernel which allow the application to use services provided by the kernel. These services are often executed on input data provided by the user application. These input data can, on occasion, constitute a problem.
Linux is a multiuser operating system; i.e., it supports multiple concurrent users. It doesn't know anything about these users or the programs they use. An erroneous or malicious application might pass an invalid argument to a system call. If the kernel then tries to use the invalid argument, unpredictable behavior can occur. For that reason, the kernel must be “paranoid” about the arguments of system calls and must carefully check each argument to ensure that it neither endangers system stability nor harms other users. This is easy for some classes of arguments; file descriptors must be open, ioctl commands must be allowed for the specified device, etc.
One class of arguments contains pointers to the location of input data in the address space of the application or to a buffer that is going to receive the data of the system call. As an example, the system call write comes to mind. One of its arguments is a pointer to a location in the application which address space that contains the data to be written. The kernel must confirm that the address is truly a part of the address space of the process and does not overlap the address range reserved for the kernel. In the case of a system call which writes data into the user address space (for example, read), the kernel additionally has to check that the destination address is actually writable.
In kernel versions up to 2.1.2, each user memory access had to be guarded by a call to the function verify_area. This function checks that an address range is valid for a certain operation (read or write). The verify_area approach has four problems:
It is slow, because the kernel has to look up the virtual memory area covering the address range in question. Virtual memory areas (VMA) are the data structures that the kernel uses to keep track of the memory mapped into each process. Searching for a certain VMA is a time-consuming process, even with an efficient algorithm. (Linux uses Adelson-Velskii-Landis trees to optimize VMA retrieval.)
It is normally not required, because most programs provide valid pointers to the kernel. Despite this, the kernel has to spend precious time for each user memory access to guard against the rare, “buggy” application.
It is error prone. A programmer can easily forget the verify_area call before a user memory access, since the address verification and the actual user memory access are separate functions.
It is not always reliable, because in new, multi-threaded applications the memory mapping can change between a verify_area operation and the actual user memory access.
In particular, point 4 required that a new solution be found for verifying addresses. With the advent of real multi-threaded programs for Linux, it was no longer just a cosmetic problem.
A new solution for the problem of address verification had to meet the following criteria:
Run as quickly as possible for the normal case of valid addresses.
Provide an easy-to-use programming interface for kernel programmers.
Be stable and correct for all cases.
Instead of implementing the address test in software, points 1 and 3 of the requirements best met by giving the virtual memory hardware (present in all Linux-capable hardware) the real work. Point 2 resulted in a merge of the access check and the actual memory access into a single access function.
The implementation relies on the MMU (memory management unit) to do the right thing. Whenever the software tries to access an invalid address, the MMU delivers a page-fault exception. This is true not only for user applications, but also for the kernel. If the kernel tries to perform an invalid memory access, a special handler intercepts the resulting exception and fixes the access. Because the handler is only invoked for problematic cases, the normal memory access has almost zero added overhead. Some experimental implementations of the new user memory access scheme have been done by Linus in kernel versions 2.1.2 to 2.1.6. They proved that this scheme works in the real world, but has a rather clumsy API inside the kernel. For Linux 2.1.7 Richard Henderson implemented the current, much-improved version introduced in this article. It is now available for most of the architectures supported by Linux. I use the x86 implementation as an example; the code for the other supported architectures is very similar.
In this new version, only the macros and functions in the machine-specific header file uacess.h are allowed to access the user address space. There are functions and macros to handle zero-terminated strings, to clear memory areas, and to copy single values to and from the kernel. One of the macros is get_user, which is called with two arguments: val and addr. It copies a single data value from the user space address addr to the variable val. On success, it returns the value 0, on failure -EFAULT (“bad address”). Its source code in the file uacess.h is somewhat hard to understand and even harder to explain.
Instead, I will track down a usage example from the function rs_ioctl in drivers/char/serial.c. The line of source code in the kernel is:
error = get_user(arg, (unsigned int *) arg);
Looks innocent, doesn't it? Well, Listing 1 shows what the C compiler makes of this code. Let's do a line-by-line walk-through, beginning with the register assignments. On output, register ECX contains the value read from the user address space, and register EDX contains the error code of the access operation. Register EBX holds the address of the value to be read. Line 01 initializes the error code with -EFAULT. In line 02, the resultant value is set to 0.
In lines 03 to 07, the kernel does the checking which ensures that the address in register EBX does not overlap with kernel memory. First, it checks if the access is from inside the kernel. This situation can occur when the kernel itself invokes a system call (for example, in the NFS client implementation). In this case, access is always granted. If the access is from outside the kernel, it checks that the given address range does not overlap the range reserved for the kernel.
In Linux, the kernel address space is mapped into the address space of every process. The kernel memory starts at address 0xC0000000. If a user program were allowed to pass a pointer to an address in kernel memory as an argument to a system call, the access by the kernel would not cause a page-fault exception. This in turn would allow the user program to overwrite kernel data. In our example (integer access = 4 bytes), the highest possible address a user process is allowed to access is 0xC0000000 - 4 = 0xBFFFFFFFC = -1073741828. Every address larger than this touches kernel memory and is therefore invalid. If memory addresses are invalid, execution continues at label .L2395 in line 21.
Now that the preliminaries are over, we prepare to access the data pointed to by EBX. Assuming that the access will be successful, we set register EDX to 0 (line 09). In line 10 the actual access takes place. Note that the address of the instruction that might fault is tagged with the local label 1. The following code in the lines 13 to 15 unconditionally set the error code to --EFAULT, the resultant value to 0, and jumps back to local label 2 in line 16. This looks like an infinite loop—it isn't.
Another important decision that Linus made at the beginning of the 2.1 development cycle was to completely abandon the a.out executable file format for kernel development in favor of the more modern ELF. Normally, ELF is only associated with easily shared library support for user applications. However, that's only one of its nice features. Another one is that ELF binaries (both object files and executables) can have an arbitrary number of named sections.
The .section .fixup, "ax" command in line 12 instructs the assembler to place the following code in the ELF section named .fixup. In line 16, we switch back to the previous code section; normally this is .text. This means that the assembler moves the code from lines 13 to 15 in the generated object file out of the normal execution path. Lines 17 to 20 accomplish a similar task by instructing the assembler to place two long values into the ELF section called __ex_table. These two values are initialized to the address of the instruction that might fault (label 1 backward, 1b) and the address of the fixup code (label 3 backward, 3b).
With the help of the command objdump, which is one of the GNU utilities, we can examine the internal structure of the linked kernel. See Listing 2. Internal Kernel Structure.
Listing 3. Code Left in Normal Execution Path
As expected, there are two sections named .fixup and __ex_table. objdump also shows us the code which remains in the normal path of execution. Looking at Listing 3, we can see that the whole user memory access is reduced to just 12 machine instructions. The code originally bracketed with the .section directives is now in the section .fixup:
c01a16bf <.fixup+17b3> movl $0xfffffff2,%edx c01a16c4 <.fixup+17b8> xorl %ecx,%ecx c01a16c6 <.fixup+17ba> jmp c018fafd <rs_ioctl+359>
The ELF section __ex_table contains pairs of addresses bracketed by <>: the faulting instruction address and the matching fixup code address. In our example, we expect the pair <c018fafb,c01a16bf>. Using the command:
objdump --section=__ex_table --full-contents\
vmlinux
and a small program to swap bytes from internal representation to a
human-readable form gives us this output:
c018f292 c01a1699 c018f51d c01a16a5 c018f5a5 c01a16ad c018fad0 c01a16b5 c018fafb c01a16bf c018fc5b c01a16cb c018fd02 c01a16d5 c018fd72 c01a16e1 c018ff5a c01a16e9 c018ff7b c01a16f3Now we have all the pieces we need to assemble the final picture. When the kernel accesses an invalid address in user space, the MMU generates a page-fault exception. This exception is handled by the page-fault handler do_page_fault in the C file arch/i386/mm/fault.c. do_page_fault first obtains the unaccessible address from the CPU control register CR2. It then looks for a VMA in the current process mappings that contains the invalid address. If such a VMA exists, the address is within the virtual address space of the current process. The fault probably occurred, because the page was not swapped in or was write protected. In this case, the Linux memory manager takes appropriate action. However, we are more interested in the case in which the address is not valid—there is no VMA that contains the address. In this case, the kernel jumps to the bad_area label.
At this point, the kernel calls the function search_exception_table to look for an address at which the execution can safely continue (fixup). Since every faulting instruction has an associated fixup handler, this function uses the value in regs->eip as a search key.
Loadable kernel modules in Linux complicate matters. After insertion at runtime, they are effectively part of the running kernel and can access user memory just as any other part of the kernel. For that reason, they have to be integrated into the exception-handling process. Kernel modules must provide their own exception tables. On insertion, the exception table of a module gets registered with the kernel. Then search_exception_table can look through all of the registered tables, performing a binary search for the faulting instruction.
To access the start and the end of an exception table, we use a feature of the linker which resolves a symbol name consisting of the name of a section prepended with __start__ or __stop__ to the start or end address of the section in question. This feature allows us to access the exception table from C code. If search_exception_table finds the address of the faulting instruction, it returns the address of the matching fixup code. do_page_fault then sets its own return address to the fixup code and returns. In this way, the exception handler gets executed. The exception handler sets the value we tried to get to 0 and the return value of the get_user macro to -EFAULT. Then it jumps back to the address immediately after the failed user memory access. It is the task of the surrounding code to report the failure back to the user application.
The new user access scheme implemented in the 2.1 development kernels of Linux provides an efficient and easy-to-use way to copy data from and to the kernel address space. The added overhead for the average, error-free case is close to zero. Because access and test for accessibility are atomic, the original problem with multi-threaded applications is resolved. This solution meets all four of our requirements.
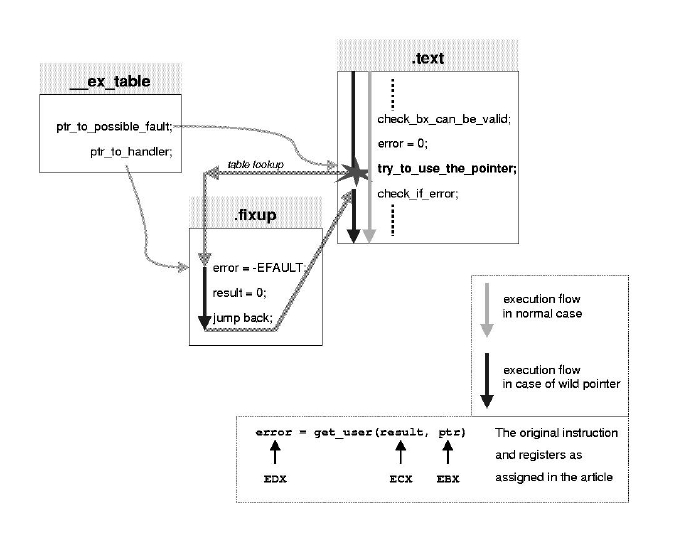
Figure 1. Execution Flow Chart
The name Jöerg Pommnitz can be found throughout the Linux kernel code. He recently changed jobs and moved without giving us his direction.

