
Pluggable Authentication Modules for Linux
Have you ever wondered how much work it would be to modify login to work the way you want it to? Perhaps you want it to refer to shadowed passwords or you don't want to let users log in during certain times of the day. Perhaps your policy is to ensure that root cannot log in anywhere other than at the console; maybe, root should never log in when the system is connected to the network. You might implement MD5-secured passwords, or passwords secured with RIPEMD-160 or SHA? Perhaps you have decided passwords are insufficiently secure for your needs, and instead you would like a user to insert their identity card in a slot to log in. Further, you would like to integrate your system into a network security environment like Kerberos; the primary login of a user would need to activate their identity with respect to the Kerberos server. The variations and combinations are endless. There is no perfect solution. There never will be.
Given sufficient incentive to implement a new user-authentication scheme, the traditional solution has been to amend, or rewrite, all of the system-access applications (login, su, passwd, ftp, xdm, ... )--this takes time and resources. An annoying by-product of such an upgrade is that modifying one application requires you to simultaneously upgrade other applications to maintain a consistent entry policy for your system. Unless you write the applications yourself, it is not easy to simply insert the code and be sure you have filled all the holes.
The revision of a system's security policy also suffers from the following potential weakness: people who write appealing user interfaces are not always paranoid enough to write secure software. This point relates to both access-oriented (login, etc.) and information-security (e-mail encryption, etc.) software.
Current thinking on computer-related security is to separate the security policy from the service offered by an application. This allows the author of a security-dependant application to use an application programming interface (API) to take care of the security-related issues and concentrate their efforts on writing a good (robust but user friendly) application.
An API is typically defined by a document describing a set of functions that an application programmer can rely on. For example, libc is an implementation of a number of APIs. Collaborative organizations, such as ANSI, POSIX or X/Open, produce a document defining the API and then vendors (or enthusiasts in the case of Linux) implement it. Security-related APIs exist for tasks like user authentication and data encryption.
Prompted by a comment on the linux-security e-mail list, Ted Ts'o asked the following question: “Has anyone thought of implementing PAM?”, and thus, he launched the Linux-PAM project. Marc Ewing (of Red Hat Software) quickly coded a framework for most of the library in January 1996. Since then I have been maintaining the Linux-PAM distribution. Thanks to the combined efforts of a number of people (I've included a “mostly” complete list at the end of this article), I'm proud to say Linux-PAM is now a reality. Better still, people are using it.
The document defining PAM is a request-for-comments paper (RFC) that was written by Vipin Samar and Roland J. Schemers III of SunSoft, Inc. Specifically, it is OSF-RFC 86.0, October 1995, “Unified Login with Pluggable Authentication Modules (PAM)”. The Linux-PAM URL at the end of this article contains a pointer to this document.
The PAM-API breaks the business of authentication into four independent management groups. These four groups are:
Authentication/credential acquisition
Account management
Session management
Authentication token (password) updating
Typically, a login application would need to use each of these groups when granting a candidate user access to a system. Applications like passwd only require access to the last of these groups.
The novelty and power of the PAM-API resides in the leading “P” for pluggability. It may surprise the reader to note that this is the part of PAM that is irrelevant from the point of the login- application writer. Instead, it introduces a role for the system administrator in the process of choosing an authentication scheme for login.
Veteran Linux users will remember all the hype that surrounded the move to ELF from the older a.out system binary. A desirable feature of this transition was the introduction of a library function, dlopen(3). This function call provides a reliable method for a running program to dynamically load some code for the purpose of execution. Its sibling function, dlclose(3), is used to unload, or discard, such code when it is no longer required. Implementations of PAM utilize these functions to dynamically bind an application program to locally specified authentication modules. That is, the pluggability of PAM is dynamic and thus at the discretion of the local system administrator.
With a PAM-based login application, the system administrator can completely change the authentication scheme the application uses without modifying or recompiling it. In principle, this can even be done without rebooting the computer. However, before a new authentication scheme is fully deployed, the best approach is to isolate a computer from any network and test it under controlled conditions to ensure the new arrangement is robust.
In the remainder of this article, I will give a brief overview of how to write and use a PAM-based application. Potential authors and interested administrators should see the Linux-PAM URL (at the end) for more complete details. The intention of this article is to provide only a taste of what you can do with Linux-PAM. In particular, I will not address the issue of how to write an authentication module. For those details you should consult the full documentation available from the Linux-PAM URL.
Let us consider a generic login-type application. We will see which responsibilities are delegated to the PAM-API and which responsibilities are retained by the application. Finally, we will cover how a local administrator can configure the application to suit local taste.
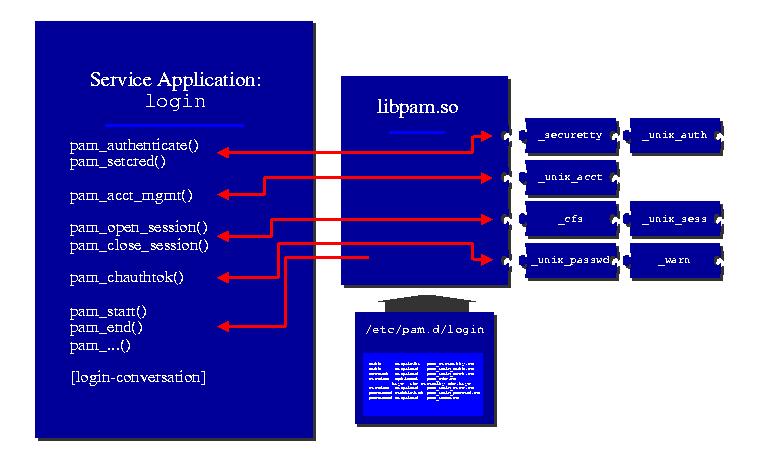
Figure 1 is a graphic protraying the three components to a working PAM-based application. On the left is the application which is linked to the libpam.so shared library. In the middle we have the PAM library which parses the configuration file(s) and uses the entries listed there to load the configured selection of authentication modules (PAMs). Additionally, the application supplies a conversation function which provides a means for the modules to talk directly with the user.
In Listing 1 the skeleton of a login-type application is shown. It can be compared with the sample application given in the OSF-RFC defining PAM. The differences reflect enhancements to PAM since the RFC was written. Note, the listing is not very secure; it pays little attention to possible errors returned by the framework and is intended only to orient the reader.
The application initializes the library with a call to pam_start(), which silently parses the configuration file and loads those authentication modules that are appropriate to this application. It then enters a loop that attempts to authenticate applicant users. This process is repeated until a user is correctly authenticated, or the loaded authentication modules indicate that their patience has been exhausted.
Once a user has been authenticated, the pam_acct_mgmt() function is used to establish if the user is permitted to log in at this time. Modules of account-management type can be used to restrict users from logging in at certain times of the day/week or for enforcing password expiration. This latter case is intercepted, and the user is prevented from gaining access to the system until they have successfully updated their password with the pam_chauthtok() function.
The user's login session is surrounded with two sets of function calls. The outer function calls, pam_open_session() and pam_close_session(), mark the beginning and end of the PAM-authenticated session. Session initialization and termination typically include tasks such as making a system resource available (mounting the user's home directory) and establishing an audit trail. The inner function calls, pam_setcred(), first establish and finally release the PAM-configurable identity of the user. These can include credentials like access-tickets and supplementary group memberships.
Following logout, the user's PAM-configurable credentials are deleted, and the session is closed with a call to the pam_close_session() function.
Finally, with a call to pam_end(), the login application breaks its connection to the PAM library. The PAMs are unloaded, and the dynamically allocated memory is scrubbed and returned to the system.
This simple application demonstrates most of the functionality provided by the PAM paradigm. The conversation mechanism flexibly leaves the mode of direct interaction with the user entirely at the discretion of the application. In this way, it is possible for modules to be used simultaneously with graphically-based programs (xdm etc.) and their text based equivalents (login etc.).
Having obtained a PAM-based application, it is necessary to attach authentication modules to it. At the time of this writing there is an old way and a new way of doing this. The old way corresponds to the method advocated in the RFC and is based on a the contents of a single PAM configuration file: /etc/pam.conf. The new method is to break up the entries for the separate services into independent configuration files that are each located in the /etc/pam.d/ directory. The name of the file containing the configuration for a given application is the service name (in lower-case letters).
The function of the configuration file(s) is to provide a mapping from the application's service name to a selection of modules that provide authentication services to the raw application. In the case of the source program of Listing 1, the service name is simply “login”. (This is the first argument of the pam_start() function call.)
Along with similar entries for each of the PAM-aware services present on your system, the old configuration file (/etc/pam.conf) might contain entries of the following form:
...
# Here is the module configuration for login as it
# might appear in "/etc/pam.conf"
#
login auth requisite pam_securetty.so
login auth required pam_unix_auth.so
login account required pam_unix_acct.so
login session optional pam_cfs.so \
keys=/etc/security/cfs.keys
login session required pam_unix_sess.so
login password sufficient pam_unix_passwd.so
login password required pam_warn.so
#
...
The first four fields are: service-name, module-type, control-flag and module-filename. The fifth and greater fields are for optional arguments that are specific to the individual authentication modules.
The second field in the configuration file is the module-type, it indicates which of the four PAM management services the corresponding module will provide to the application. Our sample configuration file refers to all four groups:
auth: identifies the PAMs that are invoked when the application calls pam_authenticate() and pam_setcred().
account: maps to the pam_acct_mgmt() function.
session: indicates the mapping for the pam_open_session() and pam_close_session() calls.
password: group refers to the pam_chauthtok() function.
Generally, you only need to supply mappings for the functions that are needed by a specific application. For example, the standard password changing application, passwd, only requires a password group entry; any other entries are ignored.
The third field indicates what action is to be taken based on the success or failure of the corresponding module. Choices for tokens to fill this field are:
requisite: Failure instantly returns control to the application indicating the nature of the first module failure.
required: All these modules are required to succeed for libpam to return success to the application.
sufficient: Given that all preceding modules have succeeded, the success of this module leads to an immediate and successful return to the application (failure of this module is ignored).
optional: The success or failure of this module is generally not recorded.
The fourth field contains the name of the loadable module, pam_*.so. For the sake of readability, the full pathname of each module is not given. Before Linux-PAM-0.56 was released, there was no support for a default authentication-module directory. If you have an earlier version of Linux-PAM installed, you will have to specify the full path for each of the modules. Your distribution most likely placed these modules exclusively in one of the following directories: /lib/security/ or /usr/lib/security/.
The equivalent functionality for our login application can be obtained with the new configuration arrangement via an independent login configuration file:
#%PAM-1.0
#(The above "magic" header is optional)
# The modules for login as they might appear in
# "/etc/pam.d/login" this configuration is
# accepted by Linux-PAM-0.56 and higher.
#
auth requisite pam_securetty.so
auth required pam_unix_auth.so
account required pam_unix_acct.so
session optional pam_cfs.so \
keys=/etc/security/cfs.keys
session required pam_unix_sess.so
password sufficient pam_unix_passwd.so
password required pam_warn.so
# end of file.
The newer configuration file is distinct from the old in that it is missing a service-name field. This field is not needed, as the name of the service-specific configuration file is by definition the service-name of the application.
It should be noted that the content of an /etc/pam.d/ directory takes precedence over the contents of any /etc/pam.conf file.
Note that the example contains more than a single module mapping for the auth, session and password management groups. This feature is referred to as stacking and enables a single application to make use of more than one module at a time. The order in which the modules are stacked is the same as the order in which they are invoked.
The two stacked auth modules are used to pam_authenticate() the user. The first module (pam_securetty.so) checks to see if the user is root and prevents root from logging in from an insecure terminal. The value requisite for control-flag is used to force immediate authentication failure if the securetty module fails. If this occurs, no more of the auth modules are executed. This has the benefit of preventing root from mistakenly typing a password over an insecure terminal line. Another popular module that can be used to prevent log in attempts like this is pam_listfile.so. It can be configured to perform many types of access control based on a list of tokens in a specified file.
When a non-superuser, joe for example, is successfully evaluated by the securetty module, control is passed to the next module in the stack, pam_unix_auth.so. This module performs standard Unix authentication. It prompts for a password and checks it against that stored in the local system. Providing your libc can handle it, it works on both shadowed and non-shadowed systems. An enhanced alternative to pam_unix_...so is the pam_pwdb.so module. This module makes use of the password database library, libpwdb.so, and can do things like MD5 passwords and offer RADIUS support. The important point is that the system administrator is the one deciding which authentication policy to implement by simply plugging in the corresponding module.
The auth module also supplies a binding for the pam_setcred() function. It is linked to the authentication process because the method by which a user is authenticated is strongly tied to the user's identity. Kerberos, for example, requires a network-based authentication and yields a ticket (the user's credential) with which they can obtain network services, such as remote login and print requests.
The account module line in our configuration file is used to check that the user is permitted to login. This is different from establishing whether the user is who they say they are. Account management deals with enforcing the expiration of passwords and preventing logins during system time. Our login example uses the standard pam_unix_acct.so module to enforce shadow password aging. Here, it is used (in conjunction with the password module type) to force the renewal of a user's password.
For experiments in this area, the administrator might like to try pam_time.so. This module can be configured to permit or deny access to users based on their terminal line, the time they are logging in and what they intend to do.
Next, we come to the session modules. The first in the stack, pam_cfs.so does not currently exist. (Because of ITAR export restrictions, I will not be writing it.) However, I have included it to illustrate the PAM session concept. At the start (and end) of the user's session on the system, this module would mount/unmount the user's cryptographically-secured home-directory, obtaining the user's home-directory/key-mapping information from the cfs.keys file. With PAM, someone could make a single module available, and that module could be used in any PAM aware application. The use of the value optional for control-flag ensures that the user can log in even when no such directory is available.
The second module, pam_unix_sess.so, logs a message with syslog(3) to announce the user's entry to and exit from the system.
Finally, we come to the password management group. Here, the stacked modules are invoked when users change their authentication token(s). Traditionally, this change could be for updating their password, but it has the potential to be extended to refreshing a smart card or a yearly update of an employee's retinal scan. In the case of the login example, we simply request a replacement for the user's Unix password. Because the pam_unix_passwd.so module is marked as sufficient, a warning is logged by the pam_warn.so module only in the case that the user fails to successfully enter a new password.
In addition to configuring specific service names, there is also a default mapping, given the service name other. It can be used to ease the integration of new services by providing a default selection of modules appropriate to the local security policy. Instead, it can be used to deny access to any application that does not have a specific pam.conf entry. This is the recommended usage, for example, we can make use of the pam_deny.so (always deny access) and pam_warn (syslog(3) an informative warning) modules as follows:
#%PAM-1.0 #(The above "magic" header is optional) # The modules for defaulting services as defined # in "/etc/pam.d/other" this configuration is # accepted by Linux-PAM-0.56 and higher. # auth required pam_deny.so auth required pam_warn.so account required pam_deny.so session required pam_deny.so password required pam_warn.so password required pam_deny.so # end of file.
This configuration always denies user access to an application. As before, the pam_warn.so is used to send a warning message to syslog(3) for administrative action. This configuration can be used to make sure that only specific services are available on your system. Note, if you write an application that uses PAM and this configuration file is not sufficient to block service from it, your application is not using PAM in the correct manner.
Thanks to the people at Red Hat, many applications are available that have been modified to support the PAM approach to user authentication. In this area, however, more work needs to be done. Indeed, some important applications are still without support. Most notably, the application ssh should be ported. Work is currently underway to provide a flexible X-based conversation function, and it is my feeling that this will lead immediately to a number of more friendly uses for PAM integration, such as popular games.
Most of the current Linux-PAM development is focused on the production of more powerful and varied modules. At last count more than twenty were written and the number is increasing—reflecting the variety of authentication schemes people use within the Linux community. You can be sure that with access to the corresponding hardware, someone out there will write an authentication module for a retinal scanner.
Recent work on the central PAM library, libpam.so, is directed at testing the security of our implementation. Due to a simple design that is well documented in the OSF-RFC and a friendly dialogue with those maintaining the Sun implementation, this is not proving to be an arduous task. In the six months it has been available, only one or two significant security problems have come to light. Currently, Linux-PAM is in beta-test (although the folks at Red Hat are doing an admirable job of offering production-level support for it). In particular, libpam.so.1.00 may even be available by the time you read this article.
Before getting to version 1.00, libpam will also have support for pluggable password-mapping, a method for chaining a number of different passwords together in a secure fashion. This concept (in a non-pluggable form) is discussed in the RFC, however, the X/Open group have since revised it, and we will implement their eventual specification in the coming months.
Further ahead, after releasing version 1.0, we will be modifying the syntax of the PAM configuration file. Current ideas relate to enhancing the control-flag field to be a great deal more flexible. Other changes are likely to be suggested and adopted as the number of administrators using PAM increases.
Finally, is Linux-PAM the only implementation of PAM? Is Linux alone? The answers to these questions are yes and no. At the time of this writing, the Linux implementation of PAM is the only fully functional version of PAM publicly available. This has been the case for at least half a year. However, a partial implementation of PAM is internally present (no /etc/pam.conf file) in Sun's Solaris 2.5. Rumors indicate that Solaris 2.6 will contain a complete, configurable implementation which should be available this year. The Sun implementation for PAM has been contributed to the X/Open group so look for it in other Unix variants in the coming years. If being cross-platform compliant is important to you, you should consult your vendor for more information. Alternatively, all of the source for Linux-PAM is freely available, so if your need is urgent, just read Linux as a synonym for free and try Linux-PAM on your other platforms now.


{kind=link}