
Money Management in Linux
Have you ever wondered where all your money goes? Do you get a nice big check on payday, but when it comes time to pay the bills, your wallet is looking rather thin? It seems there is never any money left over to save for the future. There comes a time in every person's life when it becomes obvious that they need to take control of their finances.
When I began dating the woman who is now my wife, I noticed that my money began disappearing just a little bit faster than before. As our relationship grew, so did the rate my money disappeared... This trend continued until it climaxed in the two weeks surrounding our wedding, when all the bills came due. I have never seen money disappear so fast.
Little did I know that this was only the tip of the iceberg. It seems that as life goes on my money gets stretched thinner and thinner. Now I find myself in the midst of purchasing a house, making car payments, buying dog food, and wondering how I am ever going to support my computer habit.
Needless to say, my wife and I needed a way to keep track of where our money was coming from and going to—and we needed a way to plan for our future expenses.
There are many excellent personal finance programs available at little or no cost. Unfortunately, none of the ones I found could be conveniently run under Linux. So in August of 1994 I said to myself, “How hard could it be? I will just whip up a quick little check book balancing program that runs under Unix.”
Well, as with most “little” projects, it turned out to be a bit more work than I expected. This little program turned into CBB. CBB is copyrighted under the GNU General Public License, so it is completely free. It is my humble contribution to the world of free software—a small payment for all the wonderful software others have so kindly made available for free.
CBB is a personal check book balancing utility for Unix and X11. It was primarily developed under Linux, but runs equally well under most flavors of Unix. CBB is written entirely in Perl and Tcl/Tk, so it is portable and extensible. It is a program for anyone who would like to track their income and expenses, balance their checkbook, and manage their money. Any other use (such as lining for a cat's litter box) is not supported or recommended.
CBB is an open, extensible program written entirely in scripts. It utilizes a simple ASCII data file format. In addition, CBB provides a simple interface for users to add their own reports and graphs without modifying any of the CBB source code. In the future, I plan to create a simple interface to other external modules so that other people may provide plug-ins to increase CBB's functionality.
CBB (if you haven't guessed already) stands for the Check Book Balancer. This name illustrates the extreme amount of creativeness that is inherent in us computer nerds. My wife, who is not a computer nerd, suggested “In Cheque—Putting the balance in your budget.”
Ability to create, edit and delete transactions. Automatically calculates the running balance.
Many input accelerators to reduce data entry work. For instance, the + and - keys will increment and decrement the value in the date and check number fields. Transactions will be automatically completed by typing the first few characters of the description and pressing <TAB>. The rest of the transaction will be filled in from a matching transaction.
Each transaction is assigned a category such as “entertainment” or “food”.
Ability to split the amount of a transaction across multiple categories.
Able to undo the last transaction insert, edit, or delete.
Handles multiple accounts.
Handles transfers between accounts.
Performs account balancing: i.e., the ability to enter a statement's starting and ending balances, select uncleared transactions, verify that start balance + transactions = end balance, and clear all selected transactions.
Contains a simple interface for external “user written” reports and graphs. Currently “ships” with three reports and one graph.
Ability to import from and export to the Quicken export file format. This feature has not been extensively tested, but should provide the ability to move back and forth freely between Quicken and CBB.
Able to handle recurring transactions. One of the contributed scripts adds this functionality.
Support for the international date format, i.e., 30.01.68 (DD.MM.YY).
An “auto save” function for the ASCII format data files. (This can save you when someone logs you out without asking.)
The current X-Windows selection can be pasted into any entry field. Likewise a selected piece of text in CBB can be pasted into other X-Windows applications.
Extensive reference manual is available in LaTeX, dvi, PostScript, or on-line locally in HTML format. The manual is also available at www.me.umn.edu/home/clolson/cbb/cbb-man/cbb-man.html.
Before installing CBB, you should make sure you have Perl version 4.036 or later, and Tk version 4.0 or later installed on your system.
Installing CBB is very straightforward:
Unzip and untar the distribution file, and change to the newly created cbb-0.?? directory.
Type make install.
You will be prompted for 4 items:
The location of your Perl binary.
The location of your wish4.0 binary.
Where to install the CBB executable scripts.
Where to install all the associated CBB files.
CBB attempts to present you with reasonable defaults for all of these items.
When you have finished answering these four questions, CBB will be installed.
So, you want to go for a little test drive? Want to see how, or if, this thing works? Want to send me a 21 inch monitor or the DOS drivers for my ancient Sony PAS16-SCSI CD-ROM drive? Well, read on...
The following procedure will lead you through the process of creating a new account, importing some data, editing transactions, and balancing your account.
First, here is the “one-paragraph” version of the tutorial. To use CBB, first create the directory where you would like to keep your accounts. Then, change to this directory, run CBB, and create the accounts. You may import the default account categories at any time. Finally, load the desired account (if it is not already loaded) and create, delete, and edit transactions to your heart's content, while printing reports, viewing graphs, and so on. When your bank statement arrives in the mail, balance the account.
For a more detailed tutorial, read on...
After installing CBB, the first thing you need to do is create an account.
Run CBB by typing cbb.
Select Make New Account ... from the File menu.
Enter an account name (e.g., my-demo.cbb) and an account description (e.g., My Demo Account).

Figure 1. Making Account
Click on the Create Account button. Your new account will be created and added to the master account list at the bottom of the main window. The name of the account will also be added to the category list (e.g.. [my-demo]). This name is used to specify transfers between accounts.
You will be warned about not having a categories file. This is perfectly normal at this point. An empty categories file will be created for you.
If you want to use the default categories, pull down the Functions menu and select Categories -> Add Default Categories to create the default categories.
Once you have created an account, it is time to enter a few transactions. You can import some sample data to save your fingers from the brutalities of typing. The CBB distribution comes with some sample data for this tutorial. Otherwise, feel free to skip this section and enter your own transactions.
Select Import QIF File ... from the File menu.
You will be presented with a file selection dialog box. Navigate to the CBB distribution directory. Beneath the distribution directory is a demo directory. Go to the demo directory and find the file named demo.qif. Double click on this file to select it and import it.
Figure 2. Choosing the Demo Import File
Now that you have some data to play with (Figure 3), try editing a transaction. Then try creating new transactions. Try playing around with “splits” to specify more than one category for a transaction. Play around with CBB until you get the hang of it.
Now let's pretend you just received your bank statement in the mail and you want to reconcile your new CBB account. Let's also pretend that you didn't mess things up too badly while editing transactions...
Find the Balance button near the bottom right-hand corner of the CBB window and click on it. This will bring up a list of all “uncleared” transactions.
Enter a statement ending balance of $1740.00. (Leave the statement beginning balance as $0.00.)
Select the first four transactions as well as the sixth transaction. (Pretend these were the ones that showed up on your statement.) As you select transactions, watch the “Debits = n, Credits = m, Difference = i” line.
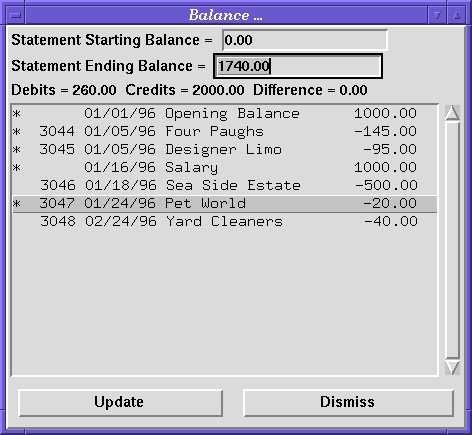
Figure 4. Reconciled Account
When the starting balance - withdrawals + deposits = ending balance, click on the Update button to mark all the selected transactions as cleared.
Congratulations: your account should be balanced.
When your next statement arrives and you run the balance routine again, you will only be presented with “uncleared” transactions to select. This is a good way to spot old checks that never were cashed, such as the mortgage payment that was “lost in the mail”. Note: By balancing your checkbook in this manner, two good things happen. First, when your brother finally cashes that check for $100.00—many months after you wrote it—your bank balance doesn't suddenly drop $100.00 from where you think it should be. Once that transaction was entered, the amount was subtracted from your bank balance. Second, it is easy to spot these situations—you can call up your brother and pester him to cash the check.
Now that you have entered a bit of data, you may want to “understand” your data at a deeper level. CBB comes with several reports and graphs which can help you get a better idea of where and how your money is being spent. Feel free to generate and look at a few reports and graphs at this point.
Wow! You've been slaving away for the last 10 minutes perfecting your demo account. Great job! That is about all there is to it. CBB isn't rocket science. It just boils down to “plus and minus”. Since this is not real data, you probably don't care to save it. However, if this had been an actual account, you most definitely would want to save your hard work.
If you want to save the changes you have made to an account, you must tell CBB to write the changes to a file. If you forget to save your work before you quit, CBB will remind you to do this. If you do something awful, like reboot your machine or log out without saving, you are not completely out of luck. CBB periodically saves a backup copy of your account with a file name such as #account.cbb#. Just rename this file to account.cbb and you will be back on track.
If you have made it this far, chances are you will be interested in some more information. I have a section devoted to CBB on my web page. Here you can find the complete CBB manual on-line, the readme file, the CBB FAQ, and several screen shots. You can even try running a live demo of CBB.
The URL for my home page is www.me.umn.edu/home/clolson/main.html.
It wouldn't be fair to end this article without mentioning two other free personal finance packages I am aware of. The first is Xfinans, another personal account manager. You can find out more about Xfinans at www.iesd.auc.dk/~lupus/xfinans.html. The second package is called Xinvest, a neat investment tracking application. Look for the source code at ftp://ftp.x.org/contrib/applications/.
Curt Olson works as a Unix systems administrator for the University of Minnesota, Department of Mechanical Engineering. He has been fascinated by computers from the time he first saw one:? Please enter your name: Curtis Olson Hello Curtis. I am thinking of a number between 1 and 100...“Ooohhh, I still get goose bumps thinking about how it remembered my name. Now, if only I could remember its name...”
