
Calibre
I've got e-books—a lot of e-books. I was one of those geeks who, when he found Projects Gutenberg and Perseus, was convinced the Rapture would happen tomorrow because life had reached its highest pinnacle on the celestial plains.
If the rapture didn't happen, nuclear war might. So I wanted to make sure I'd have all the books I could get my hands on. When Fictionwise and Tor started giving books away, I was there too. When non-DRM-encumbered books became available through Smashwords, I started picking them up as I could afford them. Ditto for Doctorow's stuff and other e-books by friends of mine—and let's not even mention the hundreds of NASA, Navy and Army manuals I use for research.
Fast-forward 13 years since discovering Project Perseus, and I have more e-books than I really know how to deal with. More than an embarrassment of riches, it was a bloody mess and high time to do something about it.
Generation one of my library organization project went the way any competent, non-database-designing sysadmin would do it: with a sensible directory structure. After many hours, I wound up with a system that was excellent for nonfiction, but crap for fiction. After all, the best you can do with a good directory tree is break out by genre, author and series. That's adequate for reference materials, but not great for the inevitable “hmmm...what do I want to read next?”
A good library needs good metadata, and directory structures have squat. E-book management software that ships with many readers attempt to do this, but they tend to have proprietary ties to devices and operating systems. They're usually not Linux-friendly, and they're also not very friendly to collection longevity. DRM? Proprietary formats? Thank you, no.
What I needed was something like iTunes or Amarok, but with a decent interface, designed for books. Fortunately, I wasn't the only person with this problem.
Enter Calibre, the Python-based, data-fetching, universally device-compatible e-book management and conversion program. The product specs are ambitious, and the implementation is, though occasionally bumpy, pretty darn spectacular.
Unlike most proprietary, device-specific management programs, Calibre converts all major formats into one another (I do not know how it handles DRM, as at the time of this writing the DMCA overthrow has just come down—happy day!—so any such features are as yet undocumented), and allows medium-grained metadata control over all of them. For fine-grained metadata control, you need more specialized tools, or you need to edit the files directly with a compatible editor. For example, Sigil does this quite splendidly for EPUB. For households with multiple species of e-readers, this is a must.
Calibre also can autopopulate your library's metadata, pulling it down from a number of different on-line databases by title, author and ISBN.
It allows rating, so you can keep track of how much you liked your book.
It has a very handsome cover art browser.
It can store Open Document Format files as e-books and create metadata for them. This gives it the nice unintended utility as a version control system for authors.
It comes with a native e-book reader that allows limited annotations and can view a number of the supported formats. For those formats that Calibre does not support reading directly, it will launch your operating system's default viewer with the click of a button.
It also nests multiple formats of the same book under the same entry in the database and directory structure, so when you convert, say, a PDF to Kindle format for your Kindle, you don't have duplicate titles popping up in your book list.
It syncs to more than 20 different makes and models of e-book reader and also allows you to access most readers (even the unsupported ones) in mass storage mode, so you're future-proofed if you change reader platforms later on.
So, what are we waiting for?
Calibre can be found at an uncommonly well-designed Web site: www.calibre-ebook.com. Click the download button, select Linux from the following screen (you'll notice that it also runs on Mac and Windows—a plus for those of us with multiplatform networks), and read the following screen first.
Calibre is picky about the dependencies; the glibc and Python versions are particularly important. Recent distributions are all in compliance, but older distros might require some updating to work properly (you also may need to compile them yourself—a fairly trivial undertaking—of course, your mileage may vary).
Assuming you're in compliance, copy the code from the code window into your root terminal (you must run the install as root; otherwise, it tends to fail with nasty comments about your intelligence, heritage and recreational proclivities), and press Enter. If all goes well, a new item should appear in your window manager's start menu. If it didn't, you most likely missed a dependency.
Calibre's project manager Kovid Goyal deserves a big pat on the back (and tips in the tip jar). Not only is the program organized well, the Web site easily navigable, and the installation relatively painless, but the documentation is very comprehensive as well.
When you open Calibre, you're presented with the main interface screen (Figure 1).
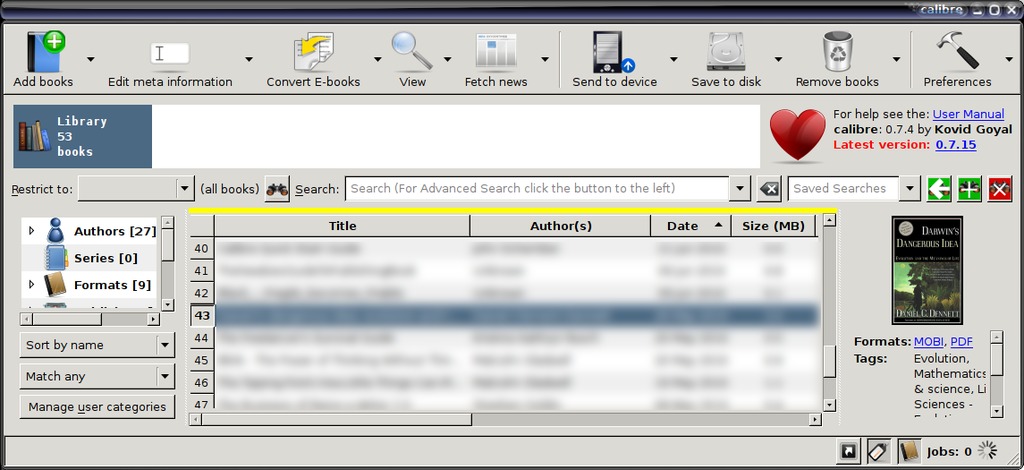
Figure 1. Calibre Interface
You'll notice the unique interface concept. There is no standard menu bar—just a toolbar with a few basic buttons and drop-downs under the buttons to allow you access to finer-grained controls on each of those tools.
Starting at the top left is the button that starts it all: Add Books. The list box attached to it gives you the option to add a single book, add a directory or a nested directory structure, or to add an empty entry into the database that you can populate later. This last option is useful if you're also adding your physical books to the collection—it can serve as a placeholder with instructions on where the book is shelved.
Moving along to the right is the metadata tool. This is the heart and soul of your database. The metadata are all your obvious tags: ISBN, Author, Series name, Publisher, Copyright date, Publication date for that edition and so on. It also includes the cover art, the listing of the different formats in which you have the book, a comments field and a tags field. Fetching metadata from the remote server populates the fields for you, not including the cover art, and it puts the back-of-book copy in the comments field and the genre in the tags field. Downloading the cover art pulls the cover art linked to that ISBN from the ISBN or Google Book servers. If you get art for an edition you didn't intend, you always can replace it by hand.
Pushing the metadata button brings up the metadata edit screen for the individual book you have selected (Figure 2). Using the drop-down list, you can act upon the metadata of multiple selected books in a variety of ways using batch functions—most handy.
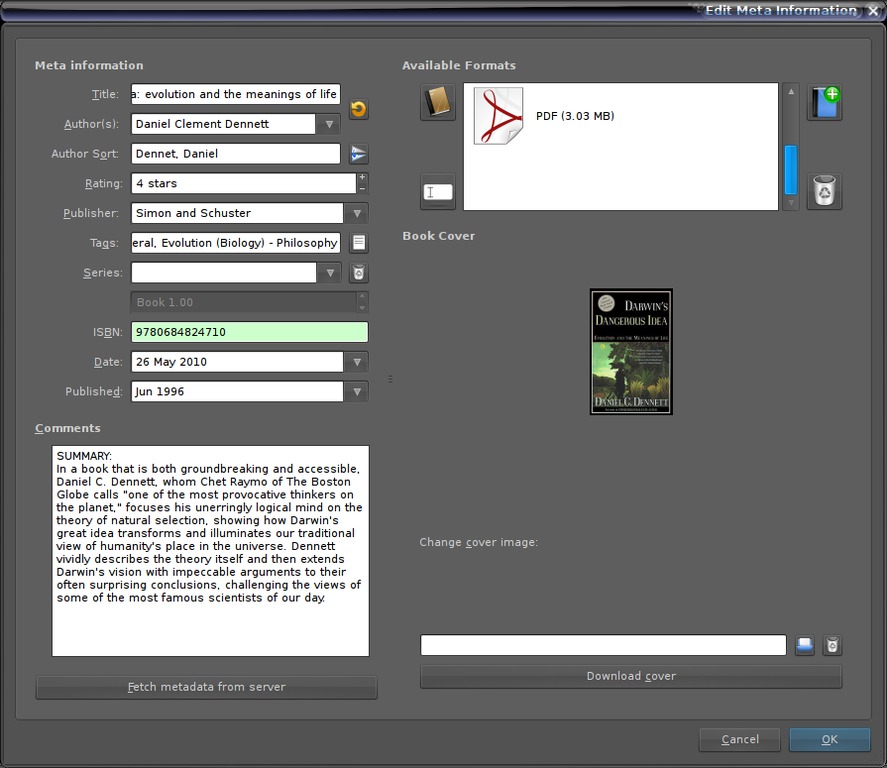
Figure 2. Editing Metadata
The third button is the conversion tool, which lets you translate one format into another—very handy for devices like the Kindle, which reads only one kind of proprietary file format. You can translate EPUBS, properly formatted PDFs (some formatting conventions, like headers and footers, can cause major headaches), OpenOffice.org documents and so on, into Kindle AZWs for easy viewing on your Kindle. In many cases, the default settings are quite adequate, but for the occasions when they're not, the tool gives you direct access to the document's structure and several of the XML wild cards. This is the one section of the program that, at the time of this writing, is not well documented, so you'll need to experiment if you're getting wonky results from the default conversion.
The drop-down list also gives you the option of creating a device-exportable library catalog—handy for those who like to compare book lists with their friends or who, like me, are simply nuts for library catalogs. (Don't laugh, there are more of us than you think, and we live on the Internet with vast botnets at our beck and call. Taunt us at your own risk.)
Next is the View button, which is fairly self-explanatory. Clicking it opens the default viewer for the highest-priority format in which the book is available. Clicking on the list box gives you the further option to view a specific format rather than just using the one Calibre picks for you by the numbers.
Next up, there's a button curiously entitled Fetch News. This is actually a very sophisticated RSS reader, and it comes preloaded with more than a thousand news feeds in various languages. If your e-reader doesn't have Wi-Fi or 3G, and you want to batch-spool up your morning news or blogs, this is the tool for you. It can pull down anything with an RSS feed, so you always can have the latest installment of Doctorow's current novel added to your library as soon as it's released.
Clicking the button brings up the scheduling window if you don't have anything scheduled yet (here you set the download schedule) or it grabs all queued downloads if you have them scheduled. Using the drop-down menu lets you fetch the news and customize the feeds by creating “recipes” for your specific news-reading needs (basically, a list of RSS feeds and the way you want them to appear in your customized electronic newspaper).
The next button along is your device controller. It syncs your selected reading list with your e-reading device. The drop-down menu lets you select the particular driver (if autodetection is not working properly) and tweak other sync settings.
If your device isn't recognized, due to driver problems, kernel issues or the device being so new there isn't a driver for it yet, fear not. The next button is Save To Disk, which will save the selected books to any location in your file tree that you please, including a USB mass storage device, such as your e-reader's internal Flash memory. When using this option, you'll usually need to reboot the device so that it rescans its file tree and updates its database accordingly.
Next is the Remove Books button, which also is self-explanatory. The drop-down gives you the option to remove singles, multiples, specific formats contained within the selected titles only, cover art only, or to remove the selected books from the attached device, but not from the library.
Finally, there's the Preferences button, which brings up the granddaddy of all dialogs (Figure 3). This is the beating heart of the operation, offering lower-level access to the database, debug functions, conversion defaults and a bunch of other stuff. Most interesting, perhaps, is the Calibre server setup, which allows Calibre to operate like a remote library system for other computers on your network (or on the Internet, if you often experience the sudden need for one of your e-books while at the office). Pretty much everything in here, sophisticated though it is, is self-explanatory.
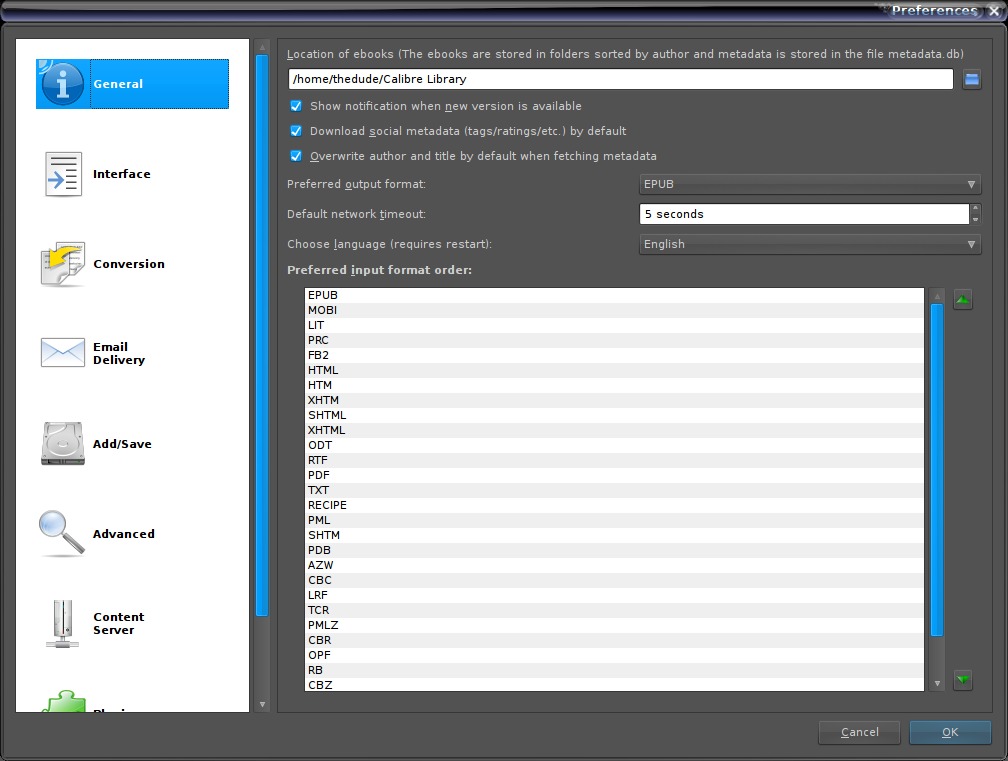
Figure 3. Preferences Screen
Below the button bar, there's a field listing the available collections. Calibre can support multiple libraries, and this is where you switch between them. Below that, there's a search bar. It doesn't search within the books, alas, but it does search the metadata quite effectively.
Moving down again, is the library itself. In the left pane, you'll find the available hierarchies—Authors, Publishers, Tags, formats and ratings. It offers all of these as pre-sorted searches, and clicking on them will modify the list you see in the center pane.
The center pane is your library itself. All the metadata is listed in easy-to-read rows of alternating colors. You can organize them alphabetically by any of the available fields simply by clicking on the column title, just as you can do with any spreadsheet or other list-driven program.
The rightmost pane shows you the cover art and a quick rundown on the book currently highlighted. File types, comments and so on all appear here.
Finally, along the bottom of the screen are three buttons that control the layout of the program. Toggling these three buttons turns on and off different panes on the screen. The one that's turned off in my default layout is the graphical bookshelf (Figure 4).
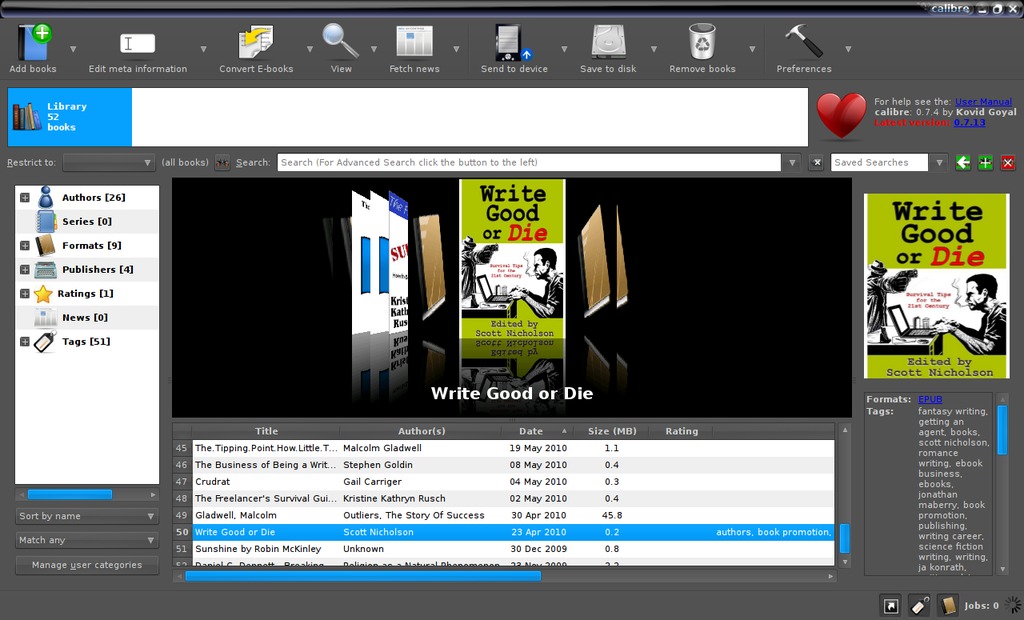
Figure 4. Graphical Bookshelf Browser
This handy interface allows you to flip through the list as it appears (search-restricted and all), like you'd flip through books on a bookshelf. Clicking left shuffles to items farther up the list, clicking right shuffles to items farther down the list.
If you're anything like me, you probably have some kind of e-book library already, so you'll want to start off by importing what you've got. Because Calibre's library import feature does some destructive rewriting, it's worth creating a backup copy of your library, just in case.
After importing, you're going to have books in your list—maybe a lot of books. And, because most e-book metadata tends to be poor, the books in your list are probably haphazard and not well organized.
Organizing them can be a laborious process, but there are a few ways to make the job less irritating—bulk-editing the metadata is chief among them, as mentioned earlier. For example, if you had 20 titles by the same author, you could select all of them, right-click on one of them, and select Bulk Edit Metadata from the pop-up menu. In the resulting screen, you can set the author, genre tags, publisher tag and most (but not all) other data fields to help with your sort. You also can check a little box that says Swap Author and Title fields. This one is particularly useful, as many poorly tagged e-books are tagged with these fields the wrong way around.
Once the organization is done to your satisfaction, you're good to go.
As shining as the program is in most respects, it comes up short in a couple areas.
The first, and most annoying, is one that is only partly the responsibility of the development team. The USB stack under the most recent versions of the Linux kernel has been occasionally glitchy. As a result, several recent distributions, including one of the ones I run, have had trouble syncing to external devices. The device would show up as a mass storage device, but attempting to access the device's internal database resulted in crashes, nasty core dumps, segfaults and the occasional exploding computer.
In the most recent kernel versions, this seems no longer to be a problem, but if you encounter it and can't upgrade your kernel or distro, you can usually fall back to mass storage mode and hand-sync your books through the Save To Disk button.
My other gripe is that there's only one comment field. The ability to deeply annotate books or keep reviews on books simply isn't there. This will cramp the style of research junkies and avid bookworms alike. Hopefully, this will be remedied in future versions (it's not like there is any shortage of potential metadata fields).
Calibre is the best-of-breed solution currently on offer for any platform, and it is well worth the download if you've got an e-book collection numbering more than a dozen, or if you've been trying to figure out some way to manage things on your Sony, Nook or Kindle without having to boot the Windows image. Enjoy!
Dan Sawyer is the founder of ArtisticWhispers Productions (www.artisticwhispers.com), a small audio/video studio in the San Francisco Bay Area. He has been an enthusiastic advocate for free and open-source software since the late 1990s. He currently is podcasting his science-fiction thriller Antithesis and his short story anthology Sculpting God. He also hosts “The Polyschizmatic Reprobates Hour”, a cultural commentary podcast. Author contact information is available at www.jdsawyer.net.
