
The Large Hadron Collider
What is at the heart of the Large Hadron Collider (LHC) experiments? It should not surprise you that open-source software is one of the things that powers the most complex scientific human endeavor ever attempted. I hope to give you a glimpse into how scientific computing embraces open-source software and the open-source philosophy in one of the LHC experiments.
The LHC near Geneva, Switzerland, is nearly 100 meters underground and provides the highest-energy subatomic particle beams ever produced. The goal of the LHC is to give physicists a window into the universe immediately after the big bang. However, when physicists calculated the level of computing power needed to peer through that window, it became clear that it would not be possible to do it with only the computers that could fit under one roof.
Even with the promise of Moore's Law, it was apparent that the experiments would have to include a grid technology and decentralize the computing. Part of the decentralization plans included adoption of a tiered model of computing that creates large data storage and analysis centers around the world.
The Compact Muon Solenoid (CMS) experiment is one of the large collider experiments located at the LHC. The primary computing resource for CMS is located at the LHC laboratory and is called the Tier-0. The function of Tier-0 is to record data as it comes off the detector, archive it and transfer it to the Tier-1 facilities around the globe. Ideally, every participating CMS nation has one Tier-1 facility. In the United States, the Tier-1 is located at Fermi National Laboratory (FNAL) in Batavia, Illinois. Each Tier-1 facility is charged with additional archival storage, as well as physics reconstruction and analysis and transferring data to the Tier-2 centers. The Tier-2 centers serve as an analysis resource funded by CMS for physicists. Individuals and universities are free to construct Tier-3 sites, which are not paid for through CMS.
Currently, there are eight CMS Tier-2 centers in the US. Their locations at universities allow CMS to utilize the computing expertise at those institutions and contribute to the educational opportunities for their students. I work as a system administrator at the CMS Tier-2 facility at the University of Nebraska-Lincoln.
By most standards, the Tier-2 centers are large computing resources. Currently, the capabilities of the Tier-2 at Nebraska include approximately 300 servers with 1,500 CPU cores dedicated to computing along with more than 800 terabytes of disk storage. We have network connectivity to the Tier-1 at FNAL of 10 gigabits per second.
LHC? CMS? ATLAS? I'm Confused.
It is easy to lose track of the entities in the high-energy physics world. The Large Hadron Collider (LHC) is the accelerator that provides the beams of high-energy particles, which are protons. It is located at CERN (Conseil Européen pour la Recherche Nucléaire). CERN is the laboratory, and the LHC is the machine. The Compact Muon Solenoid (CMS) is a large particle detector designed to record what particles are created by the collision of the beams of protons (a muon is an elementary particle similar to the electron). CMS is only one of the experiments at CERN. CMS also is used to refer to the large collaboration of scientists that analyze the data recorded from the CMS detector. Most American physicists participating in CMS are in an organization called USCMS. Other experiments at the LHC include ATLAS, ALICE, LHCb, TOTEM and LHCf. These experiments use their own analysis software but share some grid infrastructures with CMS.
One of the technically more difficult obstacles for CMS computing is managing the data. Data movement is managed using a custom framework called PhEDEx (Physics Experiment Data Export). PhEDEx does not actually move data but serves as a mechanism to initiate transfers between sites. PhEDEx agents running at each site interface with database servers located at CERN to determine what data are needed at that site. X509 proxy certificates are used to authenticate transfers between gridftp doors at the source and destination sites. The Tier-2 at Nebraska has 12 gridftp doors and has sustained transfer rates up to 800 megabytes per second.
It should be noted that the word data can mean a few different things to a physicist. It can refer to the digitized readouts of a detector, Monte Carlo simulation of outputs, or the bits and bytes stored on hard drives and tapes.
The network demands made by the Nebraska Tier-2 site have generated interesting research in computer network engineering. Nebraska was the first university to demonstrate large data movement over a dynamically allocated IP path. When Nebraska's Tier-2 is pulling a large amount of data from the Tier-1 at FNAL, a separate IP path automatically is constructed to prevent traffic from adversely affecting the university's general Internet usage.
Since data transfer and management is such a crucial element for the success of CMS, developing the underlying system has been ongoing for years. The transfer volume of Monte Carlo samples and real physics data already has surpassed 54 petabytes worldwide. Nebraska alone has downloaded 900 terabytes during the past calendar year. All this data movement has been done via commodity servers running open-source software.
Once the decision was made to decentralize the analysis resources, a crucial question needed to be answered. How does a physicist in Europe run a job using data stored at Nebraska? In 2004, the computing model for CMS was finalized and embraced the emerging grid technology. At that time, the technical implementation was left flexible to allow for sites to adopt any grid middleware that might emerge. Analysis sites in Europe adopted the World LHC Computing Grid (WLCG) software stack to facilitate analysis. Sites in the US chose the Open Science Grid (OSG) to provide the software to deploy jobs remotely. The two solutions are interoperable.
The OSG's (www.opensciencegrid.org) mission is to help in the sharing of computing resources. Virtual Organizations (VOs) can participate in the OSG by providing computing resources and utilizing the extra computing resources provided by other VOs. During the past year, the OSG has provided 280 million hours of computing time to participating VOs. Figure 1 shows the breakdown of those hours by VO during the past year. (The Internet search for the meaning of the VO acronyms is an exercise left to the reader.) Forty million of those hours were provided to VOs not associated with particle physics. Participation in the OSG allows Nebraska to share any idle CPU cycles with other scientists. Furthermore, the CMS operational model for all US Tier-2 sites is that 20% of our average computing is set aside for use by non-CMS VOs. This gives non-CMS VOs an incentive to join the OSG. Non-CMS VO participation increases support and development of the OSG software that allows CMS to benefit from improvements made by other users. The OSG's model should serve as an example for similar collaborative efforts.
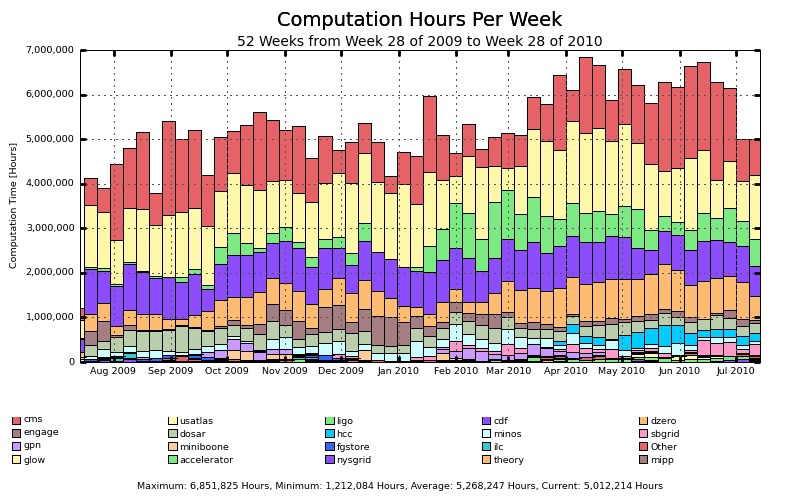
Figure 1. A week-by-week accounting of Open Science Grid usage by user VO for the past year.
OSG provides centralized packaging and support for open-source grid middleware. The OSG also gives administrators easy installation of certificate authority credentials. Certification and authentication management is one of the OSG's most useful toolsets. Further, the OSG monitors sites and manages a ticketing system to alert administrators of problems. Full accounting of site utilization is made available by OSG so that funding agencies and top-level management have the tools they need to argue for further expenditures. See Figure 2 for CPU hours provided to the OSG by some of the major facilities.
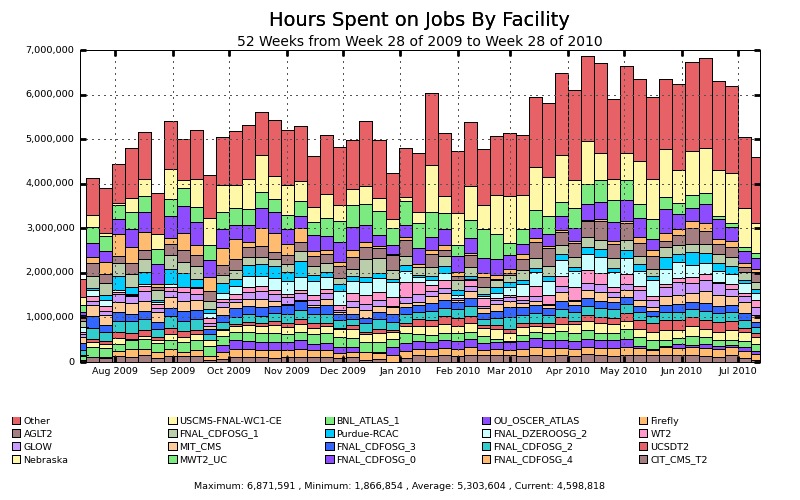
Figure 2. A week-by-week view of CPU hours provided to the Open Science Grid by computing facilities. Both “Nebraska” and “Firefly” are resources provided by the the University of Nebraska.
In short, what SETI@home does with people's desktops, OSG does for research using university computing centers.
The CMS experiment will generate more than one terabyte of recorded data every day. Every Tier-2 site is expected to store hundreds of terabytes on-site for analysis. How do you effectively store hundreds of terabytes and allow for analysis from grid-submitted jobs?
When we started building the CMS Tier-2 at Nebraska, the answer was a software package written at the high-energy physics (HEP) experiment DESY in Germany called dCache. dCache, or Disk Cache, was a distributed filesystem created by physicists to act as a front end to a large tape storage. This model fit well with the established practices of high-energy physicists. The HEP community had been using tapes to store data for decades. We are experts at utilizing tape. dCache was designed to stage data from slow tapes to fast disks without users having to know anything about tape access. Until recently, dCache used software called PNFS (Perfectly Normal File System, not to be confused with Parallel NFS) to present the dCache filesystem in a POSIX-like way but not quite in a POSIX-compliant way. Data stored in dCache had to be accessed using dCache-specific protocols or via grid interfaces. Because file access and control was not truly POSIX-compliant, management of the system could be problematic for non-dCache experts.
dCache storage is file-based. All files stored on disk correspond to files in the PNFS namespace. Resilience is managed via a replica manager that attempts to store a single file on multiple storage pools. Although a file-based distributed storage system was easy to manage and manually repair for non-experts using dCache, the architecture could lead to highly unbalanced loads on storage servers. If a large number of jobs were requesting the same file, a single storage server easily could become overworked while the remaining servers were relatively idle.
Our internal studies with dCache found that we were having a better overall experience when using large disk vaults rather than when using hard drives in our cluster worker nodes. This created a problem meeting our storage requirements within our budget. It is much cheaper to purchase hard drives and deploy them in worker nodes than to buy large disk vaults. The CMS computing model does not allow funding for large tape storage at the Tier-2 sites. Data archives are maintained at the Tier-0 and Tier-1 levels. This means the real strength of dCache is not being exploited at the Tier-2 sites.
The problems of scalability and budgeting prompted Nebraska to look to the Open Source world for a different solution. We found Hadoop and HDFS.
Hadoop (hadoop.apache.org) is a software framework for distributed computing. It is a top-level Apache project and actively supported by many commercial interests. We were not interested in the computational packages in Hadoop, but we were very interested in HDFS, which is the distributed filesystem that Hadoop provides. HDFS allowed us to utilize the available hard drive slots in the worker nodes in our cluster easily. The initial installation of HDFS cost us nothing more than the hard drives themselves. HDFS also has proven to be easy to manage and maintain.
The only development needed on our end to make HDFS suitable for our needs was to extend the gridftp software to be HDFS-aware. Analysis jobs are able to access data in HDFS via FUSE mounts. There is continued development on the analysis software to make it HDFS-aware and further remove unnecessary overhead.
HDFS is a block-based distributed filesystem. This means any file that is stored in HDFS is broken into data blocks of a configurable size. These individual blocks then can be stored on any HDFS storage node. The probability of having a “hot” data server that is serving data to the entire cluster starts to approach zero as the files become distributed over all the worker nodes. HDFS also recognizes when data required by the current node is located on that node and it does not initiate a network transfer to itself.
The block replication mechanisms in HDFS are very mature. HDFS gives us excellent data resiliency. Block replication levels are easily configured at the filesystem level, but also can be specified at the user level. This allows us to tweak replication levels in an intelligent way to ensure simulated data that is created at Nebraska enjoys higher fault tolerance than data we can readily retransfer from other sites. This maximizes our available storage space while maintaining high availability.
HDFS was a perfect fit for our Tier-2.
HadoopViz
A student at the University of Nebraska-Lincoln, Derek Weitzel, completed a student project that shows the real-time transfers of data in our HDFS system. Called HadoopViz, this visualization shows all packet transfers in the HDFS system as raindrops arcing from one server to the other. The figure below shows a still shot.

Screens from left to right: Condor View of Jobs; PhEDEx Transfer quality; Hadoop Status Page; MyOSG Site Status; CMS Dashboard Job Status; Nagios Monitoring of Nebraska Cluster; CMS Event Display of November 7 Beam Scrape Event; OSG Resource Verification Monitoring of US CMS Tier-2 Sites HadoopViz Visualization of Packet Movement
Once the data is stored at a Tier-2, physicists need to be able to analyze it to make their discoveries. The platform for this task is Linux. For the sake of standardization, most of the development occurs on Red Hat Enterprise-based distributions. Both CERN and FNAL have their own Linux distributions but add improvements and customizations into the Scientific Linux distribution. The Tier-2 at Nebraska runs CentOS as the primary platform at our site.
With data files constructed to be about 2GB in size and data sets currently hovering in the low terabyte range, full data set analysis on a typical desktop is problematic. A typical physics analysis will start with coding and debugging taking place on a single workstation or small Tier-3 cluster. Once the coding and debugging phase is completed, the analysis is run over the entire data set, most likely at a Tier-2 site. Submitting an analysis to a grid computing site is not easy, and the process has been automated with software developed by CMS called CRAB (CMS Remote Analysis Builder).
To create a user's jobs, CRAB queries the CMS database at CERN that contains the locations where the data is stored globally. CRAB constructs the grid submission scripts. Users then can submit the entire analysis to an appropriate grid resource. CRAB allows users to query the progress of their jobs and request the output to be downloaded to their personal workstations.
CRAB can direct output to the Tier-2 storage itself. Each CMS user is allowed 1 terabyte of space on each Tier-2 site for the non-archival storage of each user's analysis output. Policing the storage used by scientists is a task left to the Tier-2 sites. HDFS's quota functionality gives the Nebraska Tier-2 administrators an easily updated tool to limit the use of analysis space automatically.
Figure 3 shows a simulated event seen through CMS, and Figure 4 shows an actual record event.

Figure 3. How a physicist sees CMS—this is the event display of a single simulated event.

Figure 4. An actual recorded event from CMS—this event shows radiation and charged particles spilling into the detector from the beam colliding with material in the beam pipe.
The LHC will enable physicists to investigate the inner workings of the universe. The accelerator and experiments have been decades in design and construction. The lab is setting new benchmarks for energetic particle beams. Everyone I talk to about our work seems to get glossy-eyed and complain that it is just too complex to comprehend. What I want to do with this quick overview of the computing involved in the LHC is tell the Linux community that the science being done at the LHC owes a great deal to the contributors and developers in the Open Source community. Even if you don't know your quark from your meson, your contributions to open-source software are helping physicists at the LHC and around the world.
Carl Lundstedt received his PhD in high-energy particle physics from the University of Nebraska-Lincoln (UNL) in 2001. After teaching introductory physics for five years, he is now one of the administrators of the CMS Tier-2 computing facility located at UNL's Holland Computing Center.

