
The Pari Package On Linux
The pari package (named after the French capital Paris, where the idea for this package originated) is a computer algebra system designed to work under several Unix derivatives, and of course Linux is one of them. It is well-known to a small group of mathematicians, and most probably useful for anyone who wants to perform symbolic or numerical computations or who just likes to have a powerful calculator. Its features include arbitrary-precision numerical computation, symbolic calculations, matrix/vector operations, plotting facilities (text mode or X11), and tons of number theoretic functions. Pari provides an interactive interface (the GP calculator) as well as its own programming facilities and a library for using the kernel within its own C/C++ programs. An emacs lisp file (pari.el) for using the GP calculator within an emacs buffer is included in the package. Pari is not so extensive as the commercial packages Maple, Mathematica, or Axiom are, but its major advantage is its speed. Pari claims to be 5 to 100 times faster than the commercial counterparts. I personally like its very economical use of memory. It performs really well on my “low end” 386/40 with 8 meg RAM.
Pari is available by anonymous ftp from megrez.math.u-bordeaux.fr as pari-1.39a.tar.gz, together with examples, benchmarks, and a manual (160 pgs.) which includes a function reference and a tutorial. The authors are C. Batut, D. Bernardi, H. Cohen, and M. Olivier, who are well-known number-theorists. You can contact them at pari@math.u-bordeaux.fr.
On megrez.math.u-bordeaux.fr, you will find precompiled Linux binaries (gplinux.tar.gz) as well as the source package pari-1.39a.tar.gz. Because it contains the documentation and the examples, I recommend getting the source package even if you get the binaries. pari-1.39a.tar.gz unpacks into three subdirectories: doc, examples, and src. If you have gcc installed, recompiling is quite straightforward. After running configure i386 and performing a minor hack in the Makefile (read the src/INSTALL file), you are prepared to run make. You can optionally compile the gp calculator with readline support, meaning you have a command history, programmable keystrokes, and other features as within GNU bash. The source to bash also contains the necessary readline library.
It's easy to install the pari library and the gp calculator by issuing make install as root. Installing emacs support is a little bit tricky and requires you to edit some pathnames and constants defined in pari.el to match your configuration. Once pari.el is installed, you can start gp by issuing M-x gp and get an overview via M-x describe-mode, like most emacs modes.
After compiling and installing it successfully, let's start gp and try a few expressions at the “?” prompt:
? 2*3 %1 = 6 ? 4/3*5/14 %2 = 10/21 ? 4.0/3*5/14 %3 = 0.4761904761904761904761904761
As you can see, pari tries to use exact integer and rational numbers as long as possible. As soon as you introduce one real (floating point) number, the result will be real. You may request (almost) arbitrary precision:
? \precision=50
precision = 50 significant digits
? pi
%4 = 3.1415926535897932384626433832795028841971693993751
You may enter expressions with indeterminates
? (x+2)*(x^2+1) %5 = x^3 + 2*x^2 + x + 2
assign variables:
? x=2 %6 = 2
and evaluate, e.g., our (x+2)*(x2+1)
? eval(%5) %7 = 20
or compute some factorial
? 1000! %8 = 4023872600770937735437024339230039857193748642107146 3254379991042993851239862902059204420848696940480047 998861019719605863166687299480855890132382966994459...
within milliseconds.
Of pari's basic types, until now you have seen integer, rational, and real numbers and rational expressions with indeterminates (polynomials/rational functions). Integers can store values with up to 315,623 decimal digits. The precision of reals is controlled by the
\precision=n setting, where n is restricted to be not greater than 315623. Further, you can work with complex numbers, power series, row or column vectors, matrices, and more. You can combine these types (i.e. vectors of matrices); pari handles these using a recursive technique.
In addition to the standard mathematical operations +, -, *, and /, you find transcendental and number theoretical functions, functions dealing with elliptic curves, number fields, polynomials, power series, linear algebra, sums, and products, as well as functions for plotting.
For example, you can factor numbers and polynomials:
? factor(249458089531) %9 = [7 2] [48611 1] [104729 1]
meaning 249458089531=72*48611*104729, or
? factor(t^3+t^2-2*t-2) %10 = [t + 1 1] [t^2 - 2 1]
meaning t3+t2-2*t-2=(t+1)*(t2-2), where t2-2 cannot be factored further using rational coefficients. It is only possible to factor polynomials in one indeterminate.
To solve a linear equation x=3*y, y=2*x-1 (using the gauss method), you rewrite it as x-3*y=0, -2*x+y=-1, take the coefficient matrix A, the right side b and compute
? A=[1,-3;-2,1] %11 = [1 -3] [-2 1] ? b=[0;-1] %12 = [0] [-1] ? gauss(A,b) %13 = [3/5] [1/5]
giving you the result x=3/5, y=1/5.
To determine the roots of a polynomial you may just enter roots:
? \precision=4 precision = 4 significant digits :? roots(t^3+t^2-2*t-2) %14 = [-1.414 + 0.0000*i, -1.000 + 0.0000*i, 1.414 + 0.0000*i]~
Plotting gives you a quick overview of a function even in text-mode; see Figure 1. For plotting to a separate X11-window, enter:
? ploth(x=-pi,pi,sin(x))
Figure 1. A Function Plot in Text Mode
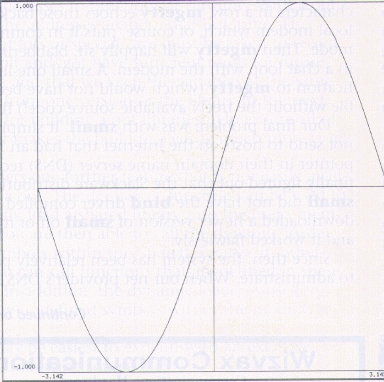
Instead, to get the graph in Figure 2, enter:
? plot(x=-pi,pi,sin(x))
The gp commands may be classified into expressions (which are evaluated immediately), function definitions, meta-commands, and help. Via the ? key, you obtain help for the meta-commands controlling gp as well as for each of the built-in functions. The meta-commands allow you to control the way of printing pari results as well as reading and writing from or to a file. \w <filename> saves your complete session (from starting gp up to issuing this command) to a file, \r <filename> does the reverse job, reading the session, bringing you to (or returning you to) the exact state that you previously saved. Other useful features include the writing of expressions in TeX/LaTeX format (via texprint) and switching the printing of timing information by the # command. You may also of course run gp as a batch job using standard I/O redirection. You span input over several lines by using the \ continuation character.
Defining your own functions in gp is quite simple. As an example, cube returns the third power of its argument:
? cube(x)=x*x*x ? cube(3) %15 = 27 ? cube(t+1) %16 = t^3 + 3*t^2 + 3*t + 1
You can use control structures as if, while, until, for (there are some special variants), goto and label as well as functions for printing or clearing variables. Though pari already provides a function fibo, let us try to program a function for the Fibonacci sequence. This sequence is defined by f0=1, f1=1, fn=fn-1+fn-2 for n>=2, yielding f2=1+1=2, f3=2+1=3, f4=5,... The (probably) shortest such function uses recursion. Here you need the if expression to test for the special cases f0=1 and f1=1. if(a,seq1,seq2) evaluates seq1 if a is nonzero and seq2 otherwise:
?fib(n)=if(n==0,1,\ if(n==1,1,fib(n-1)+fib(n-2))) ? fib(5) %17 = 8
For small n this is okay. A faster way is to compute the Fibonacci numbers by iteration. In each step the new value h=fn is computed as the sum of the last two values g=fn-1 and f=fn-2, and afterwards these values are exchanged. For this you need variables f, g, h, and m (counter). To avoid conflicts with variables defined outside the function, these four are declared as local by writing them at the end of the parameter list. The for(x=a,b,seq) expression evaluates seq for each value of x running from a to b. Expressions separated by a semicolon ; form a sequence, and a sequence's value is always that of its last expression:
? fib2(n, m,f,g,h)= f=1; g=1; \ for(m=2, n, h=f+g; f=g; g=h); g ? fib2(5) %18 = 8
Klaus-Peter Nischke has been an enthusiastic Linux user since 0.99pl13 (1993). He works at a small software company, and has worked at the local university as a mathematician. He uses pari for his own use and for mathematical research. He can be reached at klaus@nischke.do.eunet.de.


{kind=link}
{kind=link}