
Linux Swap Space
When it comes to system administration, one of the earliest decisions to be made is how to configure swap space. Many readers already are thinking they know what to do: throw in as much RAM as you can afford and configure little or no swap space. For many systems with a lot of RAM, this works great; however, very few people realize that Linux makes this possible by using a form of memory accounting that can lead to system instabilities that are unacceptable for production environments. In this article, I explain the fundamentals of Linux's swap system and show how to configure swap space for optimal stability and performance.
Linux is a demand-paged virtual memory system: all memory is broken up into pages—small equal-size chunks of a few kilobytes—and most of these chunks can be swapped (or “paged”) in or out of RAM as demand dictates (some pages are locked and can't be swapped). When a running process requires more RAM than is available, one or more pages of RAM that have not been used recently are “swapped out” to make RAM available. Similarly, if a running process requires access to RAM that previously has been “swapped out”, one or more pages of RAM are swapped out and the previously swapped-out RAM is swapped in. All of this happens behind the scenes without the programmer having to worry about it.
The filesystem cache, program code and shared libraries have a filesystem source, so the RAM associated with any of them can be reused for another purpose at any time. Should they be needed again, Linux can just read them back in from disk.
Program data and stack space are a different story. These are placed in anonymous pages, so named because they have no named filesystem source. Once modified, an anonymous page must remain in RAM for the duration of the program unless there is secondary storage to write it to. The secondary storage used for these modified anonymous pages is what we call swap space. Figure 1 shows a typical process' address space.
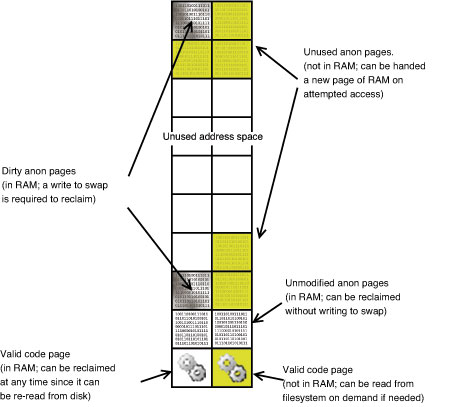
Figure 1. A typical process address space, broken into pages. Some of the pages have no valid mapping to virtual memory. Of the ones that do, many of them (shown with a yellow background) are not given RAM until the program tries to use them.
This immediately should clear up some common myths:
Swap space does not inherently slow down your system. In fact, not having swap space doesn't mean you won't swap pages. It merely means that Linux has fewer choices about what RAM can be reused when a demand hits. Thus, it is possible for the throughput of a system that has no swap space to be lower than that of a system that has some.
Swap space is used for modified anonymous pages only. Your programs, shared libraries and filesystem cache are never written there under any circumstances.
Given items 1 and 2 above, the philosophy of “minimization of swap space” is really just a concern about wasted disk space.
In some demand-paged virtual memory systems, the operating system refuses to hand out anonymous pages to programs unless there is sufficient swap space on which to store modified versions of those pages (so the RAM can be reused while the program remains active). The accounting roughly says that VM size = swap size. This provides two guarantees: that programs have access to every byte of virtual memory they allocate and that the OS always will be able to make progress because it can swap out one process' pages for another.
The problem with this is twofold. First, programs often ask for more memory than they use. The most common case is during a process fork, where an entire process is duplicated using copy-on-write anonymous pages. (Copy-on-write is a mechanism by which two processes can “share” a private writable page of RAM. Either of the processes can read the page, but the OS is required to resolve write conflicts by giving the writer a new copy of the page so as not to conflict with the other. This prevents the kernel from having to copy data unnecessarily.) Second, being able to write all of the anonymous pages to a swap device implies you are never willing to swap out pages that came from the filesystem (that is, you're not willing to allocate a filesystem page to an anonymous page such that the filesystem page may have to be swapped in later). Such systems typically require an over-provisioning of swap space in order to work properly.
Solaris relaxed this by allowing a certain amount of RAM to be considered in the allocation accounting for anonymous pages (VM size = swap size + percentage of RAM size). This reduced the need for swap space while still maintaining stability. If there wasn't sufficient swap space for modified anonymous pages, the ones currently in RAM simply could stay there while code and filesystem cache pages were reused instead.
Linux took this one step further and relaxed the accounting rules themselves, so that it tries to track memory “in use” (the non-yellow pages in Figure 1), as opposed to memory that has been promised via allocation requests. This works reasonably well because:
Many anonymous pages never get used, particularly the rarely copied copy-on-write pages generated during a fork.
Filesystem-based pages can be swapped when memory gets low.
The natural slowdown due to swapping of program code and shared library pages will discourage users from starting more than the system can handle.
It's not unlike airlines handing out reservations for seats. On average, a certain percentage of customers don't show for flights. So, overcommitting on reservations ensures that they will fly with a full plane and maximize their profit.
Similarly, Linux overcommits the available virtual memory in an attempt to maximize your return on investment in RAM and disk space. Unfortunately, if the overcommmitment turns out to have been a mistake, it kills a (seemingly) random process.
To be fair, the algorithm is careful when it knows it is running low on memory, but this is effective only if the growth in VM allocation roughly matches VM use. In other words, if a program allocates a lot of memory and immediately starts writing to the allocated pages, the algorithm is pretty good about keeping things in check. If a process allocates a lot of virtual memory but does not immediately use it (which is a common case with Java Virtual machines, databases and other production systems), the algorithm may hand out dramatically more virtual memory than it can back up with real resources.
Additionally, many programs can handle a refusal for more memory gracefully, for example, databases have tunable parameters that tell them how much RAM to use for specific tasks. Other programs might contain something like:
buffer = allocate_some_memory(10 MB) if buffer allocation ok sort_using(buffer) else do_a_slower_thing_that_uses_less_memory
But, Linux may tell such a program that it can have the requested memory, only to kill something in order to fulfill that commitment.
Fortunately, there is a kernel-tuning parameter that can be used to switch the memory accounting mode. This parameter is vm.overcommit_memory, and it indicates which algorithm is used to track available memory. The default (0), uses the heuristic method and overcommits the virtual memory system. If you want your programs to receive appropriate out-of-memory errors on allocation instead of subjecting your processes to random killings, you should set this parameter to 2.
Most Linux systems allow for tuning this parameter via the sysctl command (which does not survive reboot) or by placing it in a file that is applied when the system boots (typically /etc/sysctl.conf). To make the parameter permanent, add this to /etc/sysctl.conf:
vm.overcommit_memory=2
Now for the slightly harder part. With vm.overcommit_memory set to 2, Linux will no longer hand out anonymous pages unless it knows it has a place to store them in RAM or on swap space. So, you'll have to configure enough swap to cover it, or you won't fully utilize your RAM, because it will get reserved for things that never end up being used. The amount is the tough part. You either have to estimate the anonymous page space requirements for your system's common load, or you need to be conservative and configure a lot of it.
The classic recommendation on systems that do strict VM accounting vary, but most of them hover around a “twice the amount of RAM” figure. That number assumes your memory mostly will be filled with a bunch of small interactive programs (where their stack space is possibly their largest memory demand).
Say you're running a Web server with 500 threads, each with 8MB of stack space. That stack space alone is going to require that you have 4GB of swap space configured for the memory accountant to be happy.
Disk is cheap, so I typically start with the “twice RAM” figure. A 16GB box gets 32GB of swap. I fully expect this is overkill for my load, but disk performance considerations (lots of separate heads) mean I usually have more space than I can use anyway.
Next, I monitor system behavior. Remember, the swap space is for accounting; I don't want to see much I/O happening to it. A small amount of I/O on the swap partition(s) of a busy system is not a problem until overall throughput decreases, at which point you need more RAM or fewer programs.
Too little swap space definitely can be a problem, either because Linux denies requests for memory that can be served easily, or because idle dirty anonymous pages end up effectively locked in memory and might remain so for a very long time.
Performance indicators:
Superb: no swap space even has been allocated (the free command shows 0 swap in use), and RAM usage is low. Unless you benefit from a huge filesystem cache, you may have spent too much on RAM. Run more stuff.
Great: swap space is allocated, but there is almost no I/O on the swap partition.
OK: swap space is allocated, and there is some I/O on the swap partition. System throughput is still OK. For example, the CPUs are busy, and most of that is in the User or Nice categories. If you see CPU Wait, it indicates a disk bottleneck (possibly on swapping), and system time could mean the OS is frantically looking for memory to reuse (page scanning).
Not OK (too much swapping): lots of I/O on the swap partition. CPU is spending a lot of time in Sys or Wait, and swap disk service times exceed the average disk access times.
Not OK (too little swap space): system is running very well, but new programs refuse to start due to lack of virtual memory.
I typically have the sysstat package installed on my CentOS systems and configure the /usr/lib64/sa/sa1 script to collect all system data (including disk I/O) so I can analyze it over time. My crontab entry for this is:
*/5 * * * * root /usr/lib64/sa/sa1 -d 240 1
which gathers data over a four-minute time span every five minutes. You can analyze the resulting data using a utility called kSar (ksar.atomique.net) or at the command line. kSar has the advantage of making graphs that compare one metric to another.
You can check your historical usage by running sar against one of these data collection files. For example, to view data from the 2nd of this month:
# sar -f /var/log/sa/sa02
The most direct measure of swapping is reported from sar -W:
# sar -W -f /var/log/sa/sa02 00:00:01 pswpin/s pswpout/s 00:10:01 0.00 0.00 ...
The raw page numbers are a good start. If nonzero, you're doing some swapping. How much is acceptable is more difficult to judge. You'll need to examine the I/O on your swap partition. To do this, you may need to figure out the device major/minor numbers of your swap device. For example, if you swap to /dev/sdb1, use:
# ls -l /dev/hdb1 brw-r----- 1 root disk 8, 17 Dec 1 14:24 /dev/sdb1
to find that your device numbers are 8/17. Many versions of sar will report disk I/O by major/minor number. The command to look at the gathered disk data is:
# sar -d -f /var/log/sa/sa02
23:15:01 DEV \
tps rd_sec/s \
wr_sec/s avgrq-sz avgqu-sz \
await svctm %util
23:15:01 dev8-17 \
0.00 0.00 \
0.00 0.00 0.00 \
0.00 0.00 0.00
If you have a lot of disks, use egrep to see only the header and device:
# sar -d -f /var/log/sa/sa02 | egrep '(DEV|dev8-17)' ...
Any swapping could be bad, but if you're seeing the avgrq-sz (average size in sectors of the requests that were issued to the device) below 1 and an await time that roughly matches svctm (average service time in milliseconds for I/O requests that were issued to the device), you may be okay. Check other indicators of system performance, such as CPU waiting for I/O and high system CPU times.
Figures 2 and 3 show some custom graphs generated with kSar that make it easy to see things more clearly.
Figure 2 is a graph comparing the amount of swap space used to the amount of time the CPU spent waiting on I/O. There are spikes of I/O wait, but they don't follow any sort of pattern with the swap use. However, this system deserves more attention because there is an I/O bottleneck of some sort. It is likely that this system is underperforming, but it probably is not a swapping issue (in this case, the I/O waits were heavy database request loads).
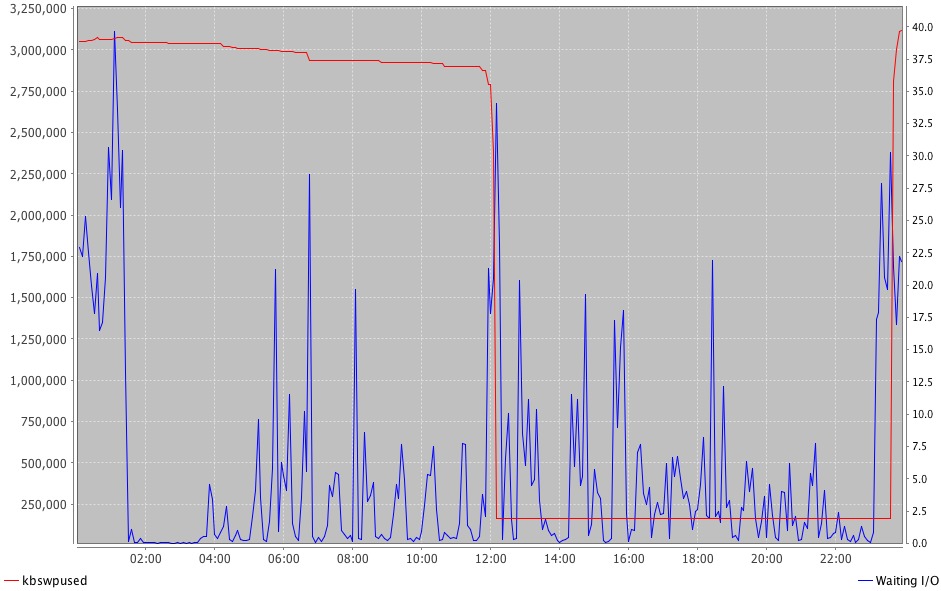
Figure 2. This graph of swap use vs. CPU I/O wait contains no real correlation between a nonzero use of swap and a performance degradation.
Figure 3 shows a graph comparing writes to the swap device vs. I/O wait (over a daytime time interval). It is a bit hard to see, but the red line for I/O is actually zero across the whole of the time span. This indicates that the I/O wait had nothing to do with swapping. Note that this does not mean no swapping of any sort occurred. Non-anonymous pages could have been reclaimed and reloaded.
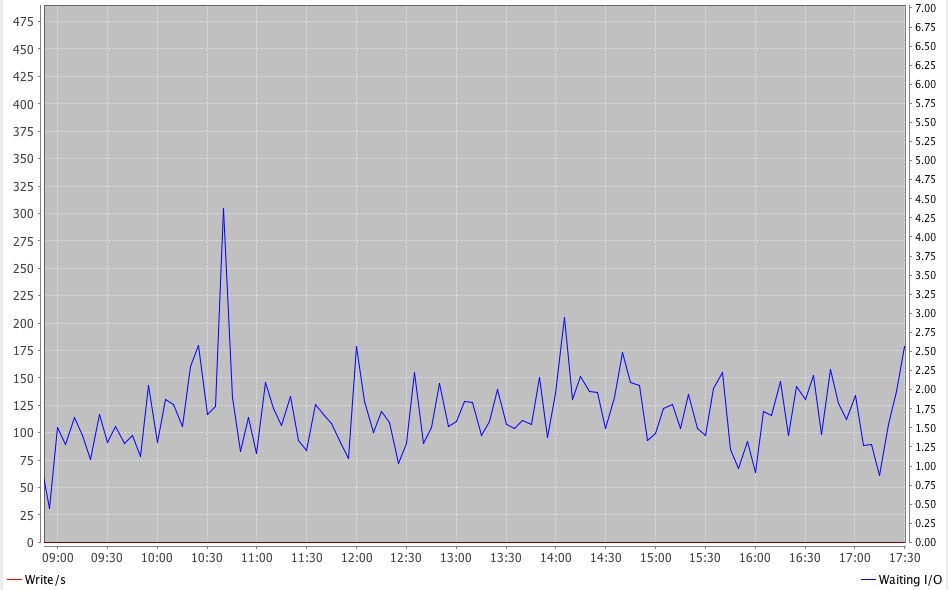
Figure 3. A Graph of I/O Writes vs. CPU I/O Wait
If you are lucky enough to have all of your data on one partition and all of your code on another, you can analyze this sort of paging by watching the reads on your “code” partition. The reads will indicate program loading at startup (which may be infrequent on your systems) and also paging due to memory pressure. If the reads correspond to large I/O waits, you may benefit from more RAM.
The final parameter I want to talk about can affect the responsiveness of certain loads. Have you ever left your system idle for a few hours, only to return to find that it takes a long time to start responding again? Here is probably what is happening: while you were gone, a cron job (like updatedb) scanned the filesystem, and because you weren't using the computer, all of the code pages for your “inactive” programs were thrown out in favor of disk cache! There is a kernel parameter called vm.swappiness that will affect the tendency of the system to throw out code pages instead of others.
The default value of vm.swappiness is 60 on most systems. Changing this parameter to 0 will prevent the kernel from throwing out code pages for filesystem caching and will prevent your desktop from becoming zombie-like due to an unmonitored filesystem scan.
The default value is fine for production systems, because any services that are heavily used will be kept in memory due to their activity. This allows the file cache to expand over anything that is truly unused and generally will work better. It may be advantageous to tune this if you are pretty certain that the majority of memory for programs should be kept (for example, you run a database that does most of its own caching). It might also help to increase this parameter to 100 on systems that have a set of very active programs.
As with any performance parameter, it helps to have some benchmarks that simulate your real workload so you can measure the effects.
Tuning these parameters will lead to a virtual memory system that provides a more stable foundation, particularly for production systems running programs that consume large amounts of memory.
Tony Kay has been working with UNIX and Linux systems for more than 20 years. He lives in Bend, Oregon, where he manages large Linux systems and develops mobile applications.

