
Inside the Linux Packet Filter, Part II
In the last issue we started following a packet's journey from the wire up to the higher levels of network stack processing. We left the packet at the end of layer 3 processing, where IP has completely finished its work and is going to pass the packet to either TCP or UDP. In this article, we complete our analysis by considering layer 4, the PF_PACKET protocol implementation and the socket filter hooks.
Apart from the case of IGMP and ICMP processing, which is dealt with in the kernel, the packet's journey toward the application proceeds by passing through either tcp_v4_rcv() or udp_rcv(). TCP processing is a bit intricate, since this protocol's FSM (finite state machine) has to deal with a lot of intermediate states (just think of the various states a TCP socket can assume: listening, established, closed, waiting and so on). To simplify our description, we can reduce it to the following steps:
Inside tcp_v4_rcv() (net/ipv4/tcp_ipv4.c), perform TCP header integrity checks.
Look for a socket willing to receive this packet (using __tcp_v4_lookup()).
If it is not found, take appropriate actions (among which, cause IP to generate an ICMP error).
Otherwise call tcp_v4_do_rcv(), passing to it both the packet (an sk_buff) and the socket (a sock structure).
Inside this latter function, perform different receive actions based on the socket's current state.
The most interesting aspect in TCP processing from the LSF point of view, comes in the last function we mentioned; at its very beginning, tcp_v4_do_rcv() calls sk_filter(), which as we will see, performs all the filter-related magic. How does the kernel know that it should invoke the filter for packets received on a given socket? This piece of information is stored inside the sock structure associated with the socket. If a filter has been attached to it with a setsockopt() system call, the appropriate field inside the structure is not NULL, and the TCP receive function knows that it has to call sk_filter().
For those of you who are fluent with sockets programming and recall that listening TCP sockets are forked upon reception of a connect message, it must be said that the filter is first attached to the listening socket. Then, when a connection is set up and a new socket is returned to the user, the filter is copied into the new socket. Have a look at tcp_create_openreq_child() in net/ipv4/tcp_minisocks.c for details.
Back to packet reception. After the filter has been run, the fate of the packet depends on the filter outcome; if the packet matches the filter rules, processing proceeds as usual. Otherwise, the packet is discarded. Furthermore, the filter may specify a maximum packet length that will be kept for further processing (the exceeding part is cut via skb_trim()).
The packet's trip proceeds on different paths depending on the socket's current state; if the connection is already established, the packet will be passed to the tcp_rcv_established() function. This one has the important task of dealing with the complex TCP acknowledgment mechanisms and header processing, which of course are not very relevant here. The only interesting line is the call to the data_ready() function belonging to the current sock (sk), commonly pointing to sock_def_readable(), which awakens the receiving process (the one that was receiving on the socket) with wake_up_interruptible().
Luckily, UDP processing is much simpler; udp_rcv() just performs some integrity checks before selecting the receiving sock (udp_v4_lookup()) and calling udp_queue_rcv_skb(). If no sock is found, the packet is discarded.
The latter function calls sock_queue_rcv_skb() (in sock.h), which queues the UDP packet on the socket's receive buffer. If no more space is left on the buffer, the packet is discarded. Filtering also is performed by this function, which calls sk_filter() just like TCP did. Finally, data_ready() is called, and UDP packet reception is completed.
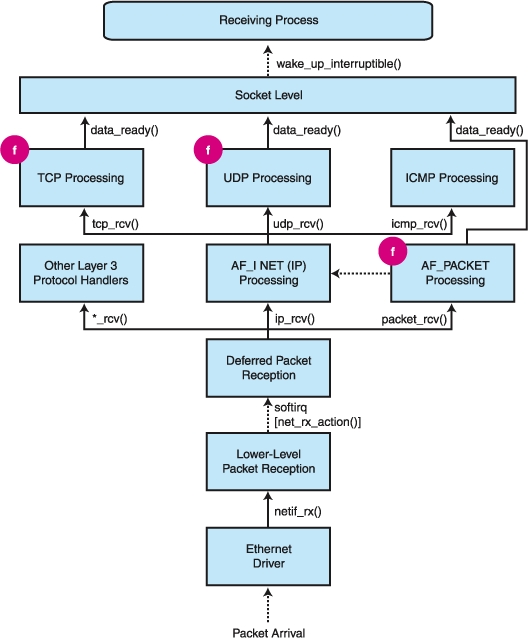
Figure 1. The Whole Reception Path, with Functional Blocks and Relevant Function Calls
The PF_PACKET family deserves a special handling. Packets must be sent directly to the application's socket without being processed by the network stack. Given the packet processing mechanisms we have outlined in the previous sections, this is actually not a difficult task.
When a PF_PACKET socket is created (see packet_create() in net/packet/af_packet.c), a new protocol block is added to the list used by the NET_RX softirq. The packet type related to this protocol family is put either in the generic list (ptype_all) or in the protocol-specific one (ptype_base) and has packet_rcv() as a receive function. For reasons that will be clear in a while, the newly created sock's address is written inside the packet type data structure. This address would not logically belong to this part of the kernel, since usually the socket information is dealt with by layer 4 code. Hence, in this case, it is written as private opaque information in the data field of the protocol block being registered—a field reserved inside the structure for protocol-specific mechanisms.
From that moment on, each packet entering the machine and going through the usual receive procedure will be intercepted during net_rx_action() execution and passed to the PF_PACKET receive function.
The first thing this function does is to try to restore the link layer header, if the socket type is SOCK_RAW (recall from my article, “The Linux Socket Filter: Sniffing Bytes over the Network”, LJ, June 2001, that SOCK_DGRAM sockets will not see the link layer header). This header has been removed either by the network card (or any other generic link layer device that received the packet) or by its driver (interrupt handler). When dealing with Ethernet cards, the latter is almost always the case. Restoring the link layer header is not possible if removal has taken place at the hardware level, since that information never gets to the system main memory and is invisible outside the network device. The computational cost of header restoration is quite low, thanks to the smart handling of skbuffs inside the kernel.
The following step is to check whether a filter has been attached to the receiving socket. This part is a bit tricky because filter information is stored inside the sock structure, which is not known yet since we are at the bottom of the protocol stack. But for PF_PACKET sockets, which must be able to skip the protocol stack, the receiving sock structure address has to be known a priori. This explains why, during the socket creation phase, the address of the sock structure had been written opaquely into the protocol block's private data field; this provides a relatively clean way to retrieve that information during packet reception.
With the sock structure in hand, the kernel is able to determine whether a filter is present and to invoke it (via the sk_run_filter() call). As usual, the filter will decide whether the fate of the packet is to be discarded (kfree_skb()), be trimmed to a given length (pskb_trim()) or be accepted as it is.
If the packet is not discarded, the next step consists in cloning the sk_buff containing the packet. This operation is necessary because one copy will be consumed by the PF_PACKET protocol, and the other must be made available for possible legitimate protocols that will be executed later. For example, imagine running a program that opens a PF_PACKET socket on a machine that is browsing the Web at the same time. For each packet belonging to the web connection, the net_rx_action() function would call the PF_PACKET processing routines before calling the normal IP ones. In this case, two copies of the packet would be needed: one for the legitimate receiving socket, which would go to the web browser, and the other for the PF_PACKET, which would go to the sniffer. Note that the packet is duplicated only after being processed by the filter. This way, only packets that actually match the filter rules engage the CPU. Also note that packet filtering performed at application level (i.e., using a PF_PACKET with no socket filter) would require cloning of all the packets received by the kernel, resulting in poor performance. Luckily, packet cloning simply involves copying the fields of the sk_buff, but not the packet data itself (which is referenced by the same pointer in the clone and in the original sk_buff).
The PF_PACKET receive function finally completes its job by invoking the data_ready() function on the receiving socket, just like the TCP and UDP processing functions did. At this point the application sleeping on a recv() or recvfrom() system call is awakened and packet reception is complete.
As a side note, you may be wondering, how does a user process come to sleep on a given socket when it invokes a recv(), recvfrom() or recvmesg() system call? The mechanism is actually pretty easy: all the recv functions are implemented inside the kernel by calling, more or less directly, sock_recvmsg() (in net/socket.c). This function, in turn, calls the recvmsg() function that is registered inside the protocol-specific operations within the sock structure. For example, this function is packet_recvmsg() in the case of PF_PACKET protocol.
The protocol-specific recvmsg function, among other things, sooner or later will call skb_recv_datagram(), which is a generic function handling datagram reception for all the protocols. The latter function obtains process blocking by calling wait_for_packet() (in net/core/datagram.c), which sets process status to TASK_INTERRUPTIBLE (i.e., sleeping task) and queues it into the socket's sleep queue. The process rests there until a call to wake_up_interruptible() is triggered by the arrival of a new packet, as we saw in the previous paragraphs.
The main filter implementation resides in core/filter.c, whereas the SO_ATTACH/DETACH_FILTER ioctls are dealt with in net/core/sock.c. The filter initially is attached to a socket via the sk_attach_filter() function, that copies it from user space to kernel space and runs an integrity check on it (sk_chk_filter()). The check is aimed at ensuring that no incongruent code is executed by the filter interpreter. Finally, the filter base address is copied into the filter field of the sock structure, where it will be used for filter invocation as we saw before.
The packet filter proper is implemented in the sk_run_filter() function, which is given an skb (the current packet) and a filter program. The latter is simply an array of BPF instructions (see Resources) that is a sequence of numeric opcodes and operands. The sk_run_filter() function does nothing more than implement a BPF code interpreter (or a virtual CPU, if you prefer) in a pretty straightforward way; a long switch/case statement discriminates the opcode and takes actions on emulated registers and memory accordingly. The emulated memory space, where the filter code is run, is of course the packet's payload (sk->data). The filter execution flow terminates, leading toward exiting the function, when a BPF RET instruction is encountered.
Note that the sk_run_filter() function is called directly only from PF_PACKET processing routines. Socket-level receive routines (i.e., TCP, UDP and raw IP ones) go through the wrapper function sk_filter() (in sock.h), which in addition to calling sk_run_filter() internally, trims the packet to the length returned by the filter.
Our tour of the kernel packet handling functions is now completed. It is interesting to draw some conclusions regarding the packet filter invocation points. As we have seen, there are three distinct call points inside the kernel where the filter may get invoked: the TCP and UDP (layer 4) receive functions, and the PF_PACKET (layer 2.5) receive function. Raw IP packets are filtered also because they pass through the same path followed by UDP packets (namely, sock_queue_rcv_skb()), which is used for datagram-oriented reception).
It is important to notice that, at each layer, the filter is applied to that layer's payload. That is, as the packet travels upward the filter can see less and less information. For PF_PACKET sockets, the filter is applied to layer 2 information, which includes either the whole link layer data frame for SOCK_RAW sockets or the whole IP packet; for TCP/UDP sockets, the filter is applied to layer 4 information (basically, port numbers and little other useful data). For this reason, layer 4 socket filtering is likely to be useless. Of course, in any case the application level payload (user data) is always available for the filter, even if it is often of little or no use at all.
A bright example of layer 4 uselessness is given in Listing 1 [available at ftp.linuxjournal.com/pub/lj/listings/issue95/5617.tgz and Listing 2, which presents a simple UDP server with an attached socket filter and an associated simple UDP data sender. The filter will accept only packets whose payload starts with “lj” (hex 0x6c6a). To test the program, compile and run Listing 1, called udprcv. Then compile Listing 2 (udpsnd), and launch it like this:
./udpsnd 127.0.0.1 "hello world"
Nothing will be printed by udprcv. Now, try writing a string starting with “lj”, as in
./udpsnd 127.0.0.1 "lj rules"This time the string is printed correctly by udprcv since the packet payload matches the filter.
Another important issue that filter writers should be aware of is that the filter must be written depending on the type of socket (PF_PACKET, raw IP or TCP/UDP) that the filter will be attached to. In fact, filter memory accesses use offsets that are relative to the first byte in the packet payload as seen at a specific level. Filter memory base addresses corresponding to the most common families are reported in Table 1.
Table 1. Filter Memory Base Addresses
Moreover, the method described in the June 2001 article to obtain the filter code (i.e., using tcpdump -dd) does not apply anymore if non-PF_PACKET sockets are used, as it produces a filter working only for layer 2 (since it assumes that address 0 is the start of the link layer frame).
Following a packet's journey through the kernel can be an interesting experience. In our trip we encountered typical kernel data structures (such as skbuffs), discovered idiomatic programming techniques (such as the use of structures with function pointers as an efficient alternative to C++ objects) and met some new 2.4 mechanisms (softirqs).
If you are eager to learn more on the subject, arm yourself with kernel sources and a comfortable editor, swallow a good cup of coffee and start peeking here and there. The price is cheap, and fun is guaranteed!


