
UpFront
UpFront
- Managing Your Dead Tree Library
- diff -u: What's New in Kernel Development
- Numeric Relativity
- Non-Linux FOSS
- Recycle's Friend, Reuse
- Organize Your Shows with Sickbeard
- They Said It
- Security at LinuxJournal.com
Managing Your Dead Tree Library
If you're an e-book reader, chances are you already use the wonderful Calibre software (www.calibre-ebook.com). If not, see Dan Sawyer's article in the April 2011 issue. Like many avid readers, however, I still find something soothing about a book made from dead trees. Unfortunately, it's easy to lose track of all the books I own. If you're the type of person who lends books out, it can become even more complicated. Enter Alexandria.
If you have a sizable personal book library, you might be interested in Alexandria (alexandria.rubyforge.org). With Alexandria, you not only can manage, sort, organize and consolidate your book collection, but you also can keep track of books you loan out. You can be a tiny little lending library, without the need for library cards!
At the very least, it's nice to keep track of your books. Alexandria makes adding books a snap, and most of the time it even automatically downloads cover art for you. You can go from a pile of dead trees (Figure 1), to a window full of perfect pixels (Figure 2) easily.

Figure 1. Dead Trees
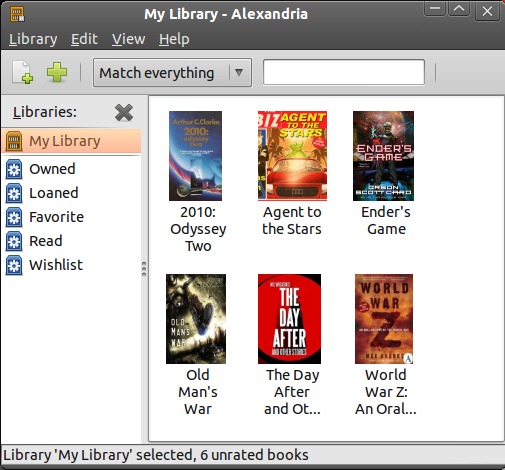
Figure 2. Books Organized with Alexandria
diff -u: What's New in Kernel Development
Sometimes a large kernel project does a lot of work outside the standard kernel development process, and then it's difficult to merge the code into the mainline source tree. This had been going on for a while with Google's Linux port to the Nexus One phone. The Nexus One development process involved lots and lots of “micro-patches” that could leave the code in a completely broken state, but that ultimately added up to the working system it had produced. This goes against standard kernel development practice, where each patch is expected to leave the kernel code in a working, testable state.
Another aspect of the Nexus One development process that caused some problems was the fact that in some cases, the true authors of a given piece of code could not be clearly established. This was just because of the way they constructed their changesets, but it made for a sticky situation for anyone trying to port code back to the official tree.
Just such an “anyone” recently appeared in the form of Daniel Walker. With excellent intentions, he tried to wrestle the Nexus One code base into a form that could be submitted for inclusion to the kernel folks, some of whom felt that such a merge was actually long overdue.
But because of the difficulty of determining attribution, and partly because Daniel himself may not have understood the true significance of some of the attribution fields in git changelogs, Daniel took an approach that led to some violent conflagrations before it was cleared up. Since his own patches were significant massages of Google's code, he just listed himself as the author and attributed the actual ownership of the code to Google in his changelog comments.
This caused problems, because some people thought Daniel was claiming authorship for other people's work; while others pointed out that without a proper chain of “signed-off-by” fields in the changesets, there would be no evidence that the code was appropriately GPLed. Others (the Google developers) felt that although Daniel wasn't necessarily claiming work that wasn't his, they still wanted attribution wherever it was feasible to give it.
Ultimately, the misunderstanding seems to have been cleared up, though it serves as a good illustration of what can happen when a large third-party project lets its code deviate beyond a certain degree from the main kernel tree before attempting to merge it back in.
I've been writing about the BKL and its future demise for a long time. Well, the future is now, apparently. Arnd Bergmann posted the patch of his recent dreams, not only taking out the last occurrences of uses of the BKL, but also removing its actual implementation. It is gone. Hoots and hollers of glee echoed through the kernel's chambers as the news was announced. Alan Cox reflected, “Nice to see it gone—it seemed such a good idea in Linux 1.3.”
Reinhard Tartler and the VAMOS team have released undertaker, a new tool that does static analysis (automated bug-hunting without compiling or running the code) for the Linux kernel. They've wound it tightly against producing false positives, saying it's better to miss a bug than to report on one incorrectly—sort of a software version of “innocent until proven guilty”.
Numeric Relativity
This month finds us at the cutting edge of physics, numerical general relativity. Because we haven't perfected mind-to-mind transmission of information, we won't actually be able to cover in any real detail how this all works. If you are interested, you can check out Wikipedia (en.wikipedia.org/wiki/ADM_formalism) or Living Reviews (relativity.livingreviews.org/Articles/subject.html#NumRel). Once you've done that, and maybe taken a few graduate courses too, you can go ahead and read this article.
General relativity, along with quantum mechanics, describes the world as we know it at its most fundamental level. The problem is there is a very small set of solutions to Einstein's equations. And, they are all solutions for idealized situations. Here are the most common ones:
Schwarzschild: static, spherically symmetric.
Reissner-Nordstrom: static, spherically symmetric, charged.
Kerr: rotating, spherically symmetric.
Kerr, Newman: rotating, spherically symmetric, charged.
In order to study more realistic situations, like a pair of black holes orbiting each other, you need to solve Einstein's equations numerically. Traditionally, this has been done either from scratch by each individual researcher, or you may inherit some previous work from another researcher. But, now there is a project everyone can use, the Einstein Toolkit. The project started out as Cactus Code. Cactus Code is a framework consisting of a central core (called the flesh) and a number of plugins (called thorns). Cactus Code provides a generic framework for scientific computing in any number of fields. The Einstein Toolkit is a fork of Cactus Code with only the thorns you need for numerical relativity.
General relativity is a theory of gravitation, proposed by Einstein, where time is to be considered simply another dimension, like the three spatial ones. So the three space and one time dimensions together give you space-time. Numerical relativity (at least in one of the more common techniques) re-introduces the break between space and time. The basic idea is that you describe space at one instance in time, and then describe with equations how that space changes moving from one time to another. This technique was introduced by Arnowitt, Deser and Misner, and is called the ADM formalism. The code in the Einstein Toolkit uses a variation on this technique.
The toolkit code is available through Subversion and Git. To make checkouts and updates easier on end users, the development team has provided a script called GetComponents. This script expects to use git, so you need git installed on your system. To get it, you can wget it from:
wget http://svn.cactuscode.org/Utilities/branches/ ↪ET_2010_11/Scripts/GetComponents chmod 777 GetComponents
Although there are several options to this script, most people simply will want to use it to grab the latest code for the Einstein Toolkit:
./GetComponents -a http://svn.einsteintoolkit.org/ ↪manifest/branches/ET_2010_11/einsteintoolkit.th
This downloads all of the parts you need to get a running system in the subdirectory Cactus. To update the code, you simply need to run:
./GetComponent -a -u ./einsteintoolkit.th
You can do it this way because the file einsteintoolkit.th actually is downloaded to the current directory by the GetComponents script.
This is pretty heavy-duty number crunching, so you likely will need to make sure you have several other packages installed on your system. You will need a C compiler, a C++ compiler and a FORTRAN compiler. You'll probably want to install MPI as well. File input and output is available in ASCII, but you may want to consider HDF5 for more structured data. Some thorns also may need some specialized libraries, such as LAPACK. This depends on which thorns you actually are using.
The way Einstein Toolkit is set up, you create and use a configuration for a particular executable. This way, you can have multiple configurations, which use different thorn combinations, all from the same core source code. To create a new configuration, it is as simple as typing make configname, where configname is the name you give to the configuration. For the rest of this article, let's play with a configuration called config1. So you would type make config1, and get a new subdirectory called config1 containing all the required files. Don't forget that this needs to be done from within the Cactus directory that was created by the GetComponents script. Once this initialization is done, you can execute several different commands against this configuration. An example would be make config1-configinfo, which prints out the configuration options for this particular configuration (Figure 1).
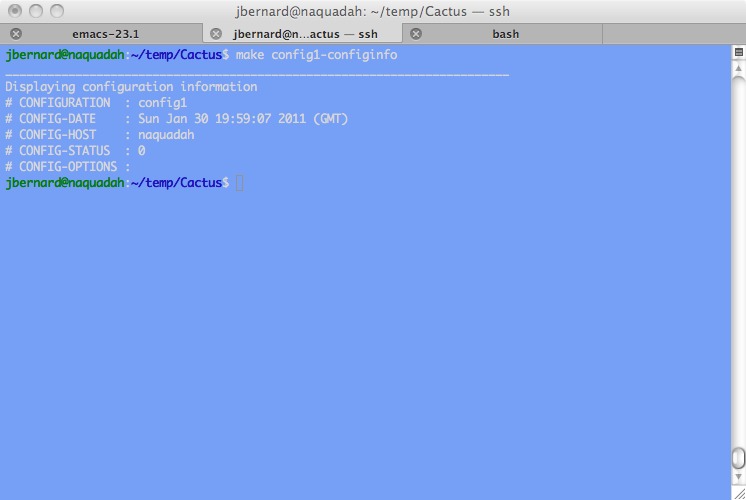
Figure 1. Example Configuration Options
The first step is making sure everything is configured properly. When you created your new configuration above, the config command was run for you. If you decide that you actually wanted to include some other options, you can rerun the config command with make config1-config <options>, where <options> are the options you wanted to set. These options are in the form <name>=<value>. An example would be MPI=MPICH, if you wanted to compile in support for MPICH parallelism. For now, you can just enter the following to do a basic configuration:
make config1-config MPI=MPICH
If you ever want to start over, you can try make config1-clean or make config1-realclean. If you are done with this particular configuration, you can get rid of it completely with make config1-delete.
Now that everything is configured exactly the way you want it, you should go ahead and build it. This is done simply with the command make config1. Now, go off and have a cup of your favourite beverage while your machine is brought to its knees with the compile. This is a fairly complex piece of software, so don't be too disappointed if it doesn't compile cleanly on the first attempt. Just go over the error messages carefully, and make whatever changes are necessary. The most likely causes are either that you don't have a needed library installed or the make system can't find it. Keep iterating through the build step until you get a fully compiled executable. It should be located in the subdirectory exe. In this case, you will end up with an executable called cactus_config1.
You can run some basic tests on this executable with the command make config1-testsuite. It will ask you some questions as to what you want to test, but you should be okay if you accept the defaults most of the time. When you get to the end, you can ask the system to run all of the tests, run them interactively or choose a particular test to run. Remember, if you are using MPICH, you need to have mpd running on the relevant hosts so the test suite will run correctly. This by no means guarantees the correctness of the code. It's just the first step in the process. As in any scientific programming, you should make sure the results you're getting are at least plausible.
Now that you have your executable, you need some data to feed it. This is the other side of the problem—the “initial data” problem. The Einstein Toolkit uses a parameter file to hand in the required parameters for all of the thorns being used. The development team has provided some introductory parameter files (located at https://svn.einsteintoolkit.org/cactus/EinsteinExamples/branches/ET_2010_06/par) that beginners can download to learn what is possible. To run your executable, run it as:
cactus_config1 parfile.par
If you are running an MPI version, it would look like this:
mpirun -np X cactus_config1 parfile.par
where X is the number of CPUs to use, and parfile.par is the parameter file to use.
As it stands, the Einstein Toolkit provides a very powerful set of tools for doing numerical relativity. But, this is only the beginning. The true power is in its extensibility. It is distributed under the GPL, so you are free to download it and alter it as you see fit. You just have to be willing to share those changes. But, the entire design of the toolkit is based around the idea that you should be able to alter the system easily. It's as simple as writing and including a new thorn. Because you have all the source code for the included thorns, you have some very good examples to look at and learn from. And, because thorns are ideally independent from each other, you should be able to drop in your new thorn easily. The list of thorns to be compiled and linked into the flesh is controlled through the file configs/config1/ThornList.
In case you decide to write your own thorn, I'll cover a bit of the concepts here. A thorn should, ideally, be completely unlinked from any other thorn. Any communication should happen through the flesh. This means that data should be translated into one of the standard formats and handed off to the flesh. The thorns are responsible for everything from IO to data management to the actual number crunching. If you are working on some new algorithm or solution technique, this is where you want to be.
The last step is getting pretty graphics. You likely will want to share your results with others, and that seems to be easiest through pictures. You will want to use other tools, like gnuplot, to generate plots or even movies of the results from your calculations. Several tutorials exist for what you can do with tools like gnuplot.
I hope this has given you enough to get started with a very powerful tool for numerical relativity. And, as always, if there is a subject you'd like to see, please let me know. Until then, keep exploring.
Non-Linux FOSS
If you love Linux but find yourself often stuck on Windows, the folks at Pendrivelinux.com have you covered. Their USB Linux installers are some of the best available, but you can create them only with Windows! Whether you want a simple Universal USB Installer tool for Linux ISO files or to create a USB drive with multiple bootable images, their tools are painless to use.
If you have Windows, but you want to install or use Linux, you owe it to yourself to give these USB creation tools a try. You might find Windows is the easiest way to install Linux!

Recycle's Friend, Reuse
Recycling is something we all deal with, or at least should deal with, when it comes to technology. Old computers, monitors, motherboards and their ilk are full of toxic chemicals that must be disposed of properly. Thankfully, “Being Green” is a trend that hasn't really lost any steam. As technologists, we understand the need to use less power, recycle old technology and make wise purchasing decisions when it comes to hardware. And, we shouldn't forget recycle's buddies reduce and reuse either.
With modern virtualization, it's possible to reduce the number of servers we need to buy. Add to that the reduction in power usage with low-power CPUs, and it's relatively easy to reduce the amount of waste in our server rooms. Unfortunately, it doesn't eliminate the problem completely. That's where reuse comes into play. In the photo, you'll see a clock I received as a Christmas gift. It's simply the circuit board from some sort of router that has “clock guts” added to it. Geeky yes, but if it's stuck on my wall, it's one fewer piece of computer scrap in a landfill.
No, reusing old technology like this won't solve our technology waste problem, but every little bit helps. Plus, items like my picture frame made from old 30-pin SIMM memory chips make for great conversation pieces. How have you reused technology in nontraditional ways? Send a photo to shawn@linuxjournal.com, and I'll post some of them on our Web site. Perhaps we'll all get some gift ideas for the next holiday season!

Organize Your Shows with Sickbeard
First, a disclaimer: the program Sickbeard was created for the purpose of pirating television shows from Usenet and torrent sites. I don't condone piracy of any sort, but Sickbeard has some amazing other features that make it worth mentioning.

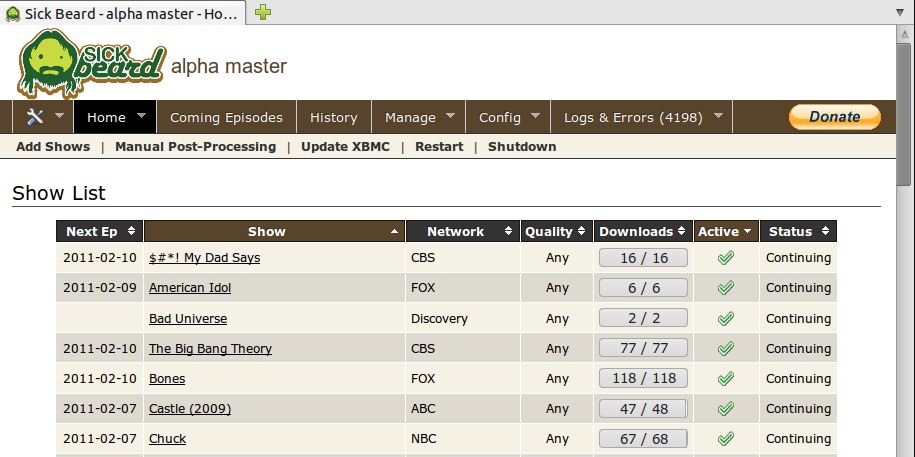
Sickbeard is a server-based application that runs on your file server, and it can manage and sort all of your television shows. If you have a collection of TV episodes you've recorded with MythTV, ripped from DVD, pulled from TiVo or however you might have procured them, organizing them in a way that programs like Boxee or XBMC understand can be daunting. Sickbeard is a program that can sort, organize and rename episodes automatically. It lets you know if you are missing episodes, and it can download metadata and cover art. It even can notify you with a pop-up on your XBMC home-theater device when a new episode is added to your library.
Again, Sickbeard was designed with nefarious intentions in mind, but even if you don't want to pirate television shows from Usenet, it's a great way to keep your XBMC database organized. Check it out at www.sickbeard.com.
They Said It
The real danger is not that computers will begin to think like men, but that men will begin to think like computers.
—Sydney J. Harris
The factory of the future will have only two employees, a man and a dog. The man will be there to feed the dog. The dog will be there to keep the man from touching the equipment.
—Warren G. Bennis
What the country needs are a few labor-making inventions.
—Arnold Glasow
If it keeps up, man will atrophy all his limbs but the push-button finger.
—Frank Lloyd Wright
Security at LinuxJournal.com
Did you know you can visit www.linuxjournal.com/tag/security to see all our latest security-related articles in one place? It's important to stay informed about all things security-related, so we hope you'll visit us often.
Do you have some security insights to share with LinuxJournal.com readers? We're always looking for Web contributors, so let us know if you have something to share with the whole class. Drop me a line at webmistress@linuxjournal.com.

