
Semantic Web Publishing with RDFa
I learned UNIX from a real old-style guru named Jimmy who memorized microchip numbers and used sed as a word processor. Wanting to do well on my first job, I proudly showed him how I was putting detailed comments in my code. My mentor was not impressed. “Why are you doing that?” he shot at me, going on to explain that neither comments nor docs could be trusted. If you wanted to understand what the code was doing, you better read the code. Software project managers might not agree, but Jimmy did have a point. Docs and comments can become out of date or inaccurate, but the code can't. Broken, yes. Inaccurate, no.
A similar issue arises when writing a Web page that is intended to be read by humans and parsed by machines. New sophisticated search engines on the horizon will be hungry for semantic content—that is, for data that can be machine-parsed for meaning. Often the format will be some form of RDF, or Resource Description Framework. If you are publishing Web pages in order to share your data with the world, it follows that you want to make it available to both humans and search engines. Generating two sets of files, one human-readable HTML and another machine-parsable RDF, means that you give up the ability to hand-edit your HTML files to make corrections and sets up your site for likely inconsistency down the road—not to mention that full-on RDF/XML is verbose and ugly.
Enter RDFa, a lightweight relatively new mechanism for embedding structured data into HTML in a simple but fully standards-compliant way. I run a Web site that is generated from templates. To understand how RDFa might fit in to my site, I started with a simple manually created example: an event schedule for the local rodeo. Later in this article, I also briefly cover some of the emerging tools that automate RDF and RDFa and describe how one company has created a large-scale RDF implementation to solve enterprise problems. Now, here's the example.
My original sample code looked like this, in vanilla HTML:
<div>
<h1>Saturday Rodeo Schedule 2/22/08</h1>
<div>
2:00PM : Bull Riding
</div>
</div>
It's pretty straightforward and clear to the human reader of the Web page or even someone editing the source, but it's meaningless to a search engine. To make this event clear to an RDFa-parsing engine, my first step was to pick a vocabulary that has well-defined terms for events. Luckily, there is just such a vocabulary, based on the iCalendar standard for calendar data. The vocabulary or vocabularies used in a document are specified right in the <html> tag at the start of the document:
<html xmlns="http://www.w3.org/1999/xhtml" >
The xmlns stands for XML NameSpace, and cal is the shorthand name we'll use to refer to this namespace further down. The http://www.w3.org/2002/12/cal/ical# is the URL to the RDF vocabulary file, and http://www.w3.org/1999/xhtml is the URL for the standard XML namespace that you might already be including in your documents. I explain further on discovering those and deciding which to use in a bit. Applying a bit of RDFa using basic iCal properties, we have this:
<div id=RodeoSchedule2008>
<h1>Saturday Rodeo Schedule 2/22/08</h1>
<div rel="cal:Vevent">
<span property="cal:dtstart"
content="20080222T1400-0700">2:00PM</span>
:
<span property="cal:summary">Bull Riding</span>
</div>
</div>
From the browser's point of view, the HTML layout is unchanged. If desired, class= properties could be added for CSS formatting and would not impact the RDFa logical structure. This is different from the microformat hCalendar (another popular way of representing calendar data in HTML), in which fixed class names are assigned.
One last step alerts parsers to the presence of RDFa in our document and also specifies the encoding or character set used. We add the following lines at the very beginning of the file, before the <html..> tag:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML+RDFa 1.0//EN" "http://www.w3.org/MarkUp/DTD/xhtml-rdfa-1.dtd">
Now, any application that understands RDFa can scan your Web page and learn that there is an event called Bull Riding occurring on February 22, 2008 at 2:00 PM PST. In fact, you can verify that you've communicated correctly with the RDFa world by using any of a number of validating/parsing services. Using the Python-based service at www.w3.org/2007/08/pyRdfa, called RDFa Distiller, we can see that the above snippet produces the following semantic data, in what is called the N3 format:
@prefix cal:<http://www.w3.org/2002/12/cal/ical#>.
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>.
[ a cal:Vevent;
cal:dtstart "20080222T1400-0700";
cal:summary "Bull Riding"].
N3 is a shorthand that people who work heavily in the RDF world like to use for writing and representing the triples that compose the Semantic Web.
Now, it's time to back up a bit. The term Semantic Web is used in this article to refer to the goal of a machine-parsable Web of structured data, as envisioned by Tim Berners-Lee in his 2001 Scientific American article by that name. Although there still is plenty of spirited debate over exactly how Web 3.0 will take shape, the W3 folks and others have been working diligently on a core set of technologies that has started to gain serious traction in the wild. Check out the layercake diagram from the W3C (Figure 1).
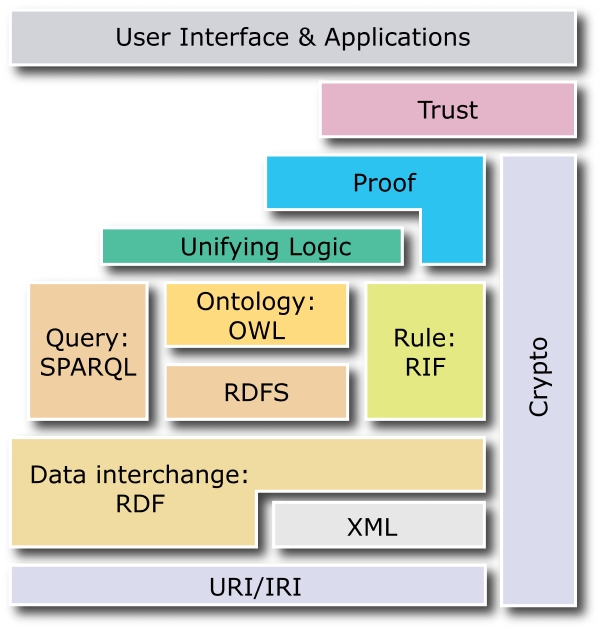
Figure 1. Layercake Diagram from W3C (source: www.w3.org/2001/sw/layerCake.png)
RDF, the data model on which the whole thing is based, represents the world as a set of triples: subject, predicate and object. Each item in the triple can be a URI, a literal or a blank node (a kind of temporary variable). In practice, the predicate is likely to be a URI in a namespace created for the purpose, like cal:dtstart or cal:summary.
Vocabularies and ontologies form the backbone of the Semantic Web. You can define your own, and some tools like Semantic MediaWiki create an ontology for you automatically. When defining the terms in a specialized domain, or when creating a private within-enterprise application, creating your own ontology makes sense. For sharing data with the world, I prefer to reuse existing vocabularies as much as possible. (By vocabulary, I mean an RDF file that defines terms and properties; by ontology, I mean a vocabulary that also contains logical rules.) Some widely used vocabs include the following:
foaf: friend of a friend, for identifying people and other entities (xmlns.com/foaf/spec/20071002.rdf).
ical: based on the iCalendar W3 standard, for calendar and event data (www.w3.org/2002/12/cal/ical).
vcard: intended as an electronic business card, it has simple fields for contact information (www.w3.org/2001/vcard-rdf/3.0).
dc: Dublin Core, defining core properties like title and creator (purl.org/dc/elements/1.1).
cc: for Creative Commons licenses (creativecommons.org/ns).
rss: the RSS 1.0 namespace (purl.org/rss/1.0).
Note that in our document, we can choose our own shorthand name for each vocabulary when we list it in the <html> tag. Then, we can use that shorthand to write what is called a CURIE, or Compact URI, like dc:title or foaf:name. In RDFa, those CURIEs are valid URIs and are much easier to read once you get used to them. One of the core ideas of RDF is to be able to use URIs to refer to concepts and things outside cyberspace, and then use them to make logical statements. So, it helps if the URIs are human-readable.
Going back to the rodeo schedule example, suppose we want to list the contestants in each event. Now, we get into the power of RDFa—the ability to connect different types of data together in a logical way right in an HTML file. The first step is to pick or create a vocabulary to describe the contestants. FOAF is the standard for referring to people, but I also want to specify that they are contestants in the rodeo. I did a search on Swoogle for the word contestant, and after a few minutes examining the available ontologies, I decided that http://smartweb.semanticweb.org/ontology/sportevent is the most apt. I also want to add a contact person for the rodeo as a whole, using the vCard vocabulary. So, I added foaf, contact and sportevent vocabularies to the list at the start of the document, which now looks like this:
<html xmlns="http://www.w3.org/1999/xhtml" xmlns:foaf= "http://xmlns.com/foaf/spec/20071002.rdf" xmlns:contact= "http://www.w3.org/2001/vcard-rdf/3.0#" >
Zooming in on just the event itself, we can add some contestants:
<div rel="cal:Vevent">
<span property="cal:dtstart" content="20080222T1400-0700">2:00PM</span>
:
<span property="cal:summary">Bull Riding</span>
<ul>List of Contestants:
<li rel="sportevent:Contestant" id="Marchi">
<span property="foaf:name" about="#Marchi"
>Guilherme Marchi</span><br/>
<a rel="foaf:weblog" about="#Marchi"
href="http://example.com/~Marchi"
>Marchi's blog</a>
</li>
<li rel="sportevent:Contestant" id="Briscoe">
<span property="foaf:name" about="#Briscoe">Travis Briscoe</span>
</li>
</ul>
</div>
And, at the bottom of the page, we add a footer with general contact information:
<p class="footer" about="/main/page/for/Rodeo"> For general information or event questions, please call <span property="contact:phone">800-555-1212</phone> or email <a rel="contact:email" href="mailto:rodeo-info@example.com" >rodeo-info@example.com</a> </p>
RDFa uses several existing HTML properties and creates a few new ones. Recall that an RDF statement has three parts: subject, predicate and object. The about= or instanceOf= property of a tag can specify the subject. The rel=, rev= or property= property specifies the predicate. Then, the object may be the href=, content= or actual content enclosed by the tag pair. Note that the subject may be in a parent tag and, if missing, defaults to the document itself. Refer to the RDFa Syntax Specification and Primer documents for a detailed explanation of all the ways that RDF can be embedded in HTML.
Re-verifying through the RDFa Distiller returns the necessary @prefix lines to specify the vocabularies, followed by the N3:
@prefix cal: <http://www.w3.org/2002/12/cal/ical#>
(...all the other prefixes...)
<http://abra.info/lj/rodeo.xhtml> cal:Vevent
[ sportevent:Contestant
<http://abra.info/lj/rodeo.xhtml#Briscoe>,
<http://abra.info/lj/rodeo.xhtml#Marchi>;
cal:dtstart "20080222T1400-0700";
cal:summary "Bull Riding"
].
<http://abra.info/main/page/for/Rodeo>
contact:email <mailto:rodeo-info@example.com>;
contact:phone "800-555-1212".
<http://abra.info/lj/rodeo.xhtml#Briscoe>
foaf:name "Travis Briscoe".
<http://abra.info/lj/rodeo.xhtml#Marchi>
foaf:name "Guilherme Marchi";
foaf:weblog <http://example.com/~Marchi>.
It's just like that. Well, that's not exactly how it went. The RDFa Distiller fails tersely on less-than-valid XHTML, which means that one mismatched tag or missing quotation mark causes unexplained failure. So, what I really did was use the user-friendly W3 Validator service first, at validator.w3.org, which reminded me about some missing tags and also to save my example as .xhtml so it would be returned with the correct MIME type. After passing the validator, I renamed the file and ran it back through the RDFa Distiller to generate the above N3 output. (The Distiller also has some caching issues. It was designed as a check of the syntax specification, not as a user tool. I use it anyway because I like the N3 output format.)
Another useful tool for checking your triple logic is the GetN3 bookmarklet available from www.w3.org/2006/07/SWD/RDFa/impl/js. Once you've saved it as a bookmark, you can use it to extract the RDFa quickly as N3 of any page you have in the browser. It's also more forgiving than the Distiller, so you can use it as a quick logic check without worrying about valid XHTML.
Tools are emerging from the RDF world at an accelerating pace this year, and you may find what you need without writing a line of code. Not all of them produce RDFa, however. Some, such as Semantic MediaWiki, produce the HTML and RDF side by side, from an internal triple store. It's a fair chance you've already used RSS (which originally stood for RDF Site Summary when it was created at Netscape back in 1999). If you use version 1.0, take a look at the RSS source—it's valid RDF/XML.
Another group to keep an eye on is the Simile Project at MIT. It has an interesting range of tools with the broad purpose of managing and reusing bits of digital data. Not all are RDF-related, but the RDFizer promises to convert a variety of structured formats to RDF for you: mbox, Debian software packages, Subversion and many more.
The most advanced tools probably are not yet in the open-source arena. Metatomix, Inc., has done some heavy lifting in the semantic application field, with major implementations in engineering, finance and integrated justice. I talked to CTO Howard Greenblatt, and he explained the company's technology stack. The key components are first, a set of development tools for creating the ontology, and second, a messaging platform that gathers data from traditional data sources and integrates it into a triple store, along with some business rules logic. For the first component, they have their own plugin for the Eclipse development environment, and for the second, they use Jena from HP Labs plus a bunch of proprietary code. Then, the whole thing can be queried in SPARQL, the query language of the Semantic Web.
That's more than most Web developers are likely to bite off. However, it brings us back to a point from our example above: choosing, or creating, an appropriate vocabulary. To say anything on the Semantic Web, you have to have a namespace in which to speak precisely. Writing your own vocabulary is not too hard (and Semantic MediaWiki helps you do it automatically), but you may want to choose a standard one, at least if you are interested in search engine discovery.
Yahoo announced in March 2008 that it would start supporting Semantic Web standards, including microformats, RDFa and eRDF. And, it announced specific vocabulary components that would be supported: Dublin Core, Creative Commons, FOAF, GeoRSS and MediaRSS. Using these vocabularies will make your data more portable and easier for search engines to index intelligently.
If you want to see what vocabularies others are using, the GetN3 bookmarklet is helpful. A visit to digg.com, run through the GetN3 bookmarklet, shows that Digg is now embedding RDFa using the Dublin Core and Creative Commons vocabularies (prefixes added):
<http://digg.com/> cc:attributionName "Digg users"; cc:license cclicense:publicdomain/; ... <http://digg.com/space/Jules_Verne_in_Orbit> dc:source <http://apod.nasa.gov...>; dc:title "Jules Verne in Orbit"; dc:abstract "The bright edge of planet Earth.."; dc:creator <http://digg.com/users/ezentmyer>; dc:date "2008-04-05 05:07:38";
I think the Semantic Web is finally taking off this year. Semantic applications range from personal desktop productivity (MIT's Piggybank) to new Web search engines (Yahoo) to huge enterprise applications and even military information-sharing. As the social networks grow heavy with data, sharing and structuring that data becomes more important. Eric Miller, an MIT professor who led the Semantic Web initiative for the W3C, sees “a new market space for data aggregation, data integration, and data discovery”. And, all you have to do to be a part of that space is add a couple tags into your page.
Thanks to the following individuals for their time, assistance and insight: Michael Hausenblas, Ivan Herman, Eric Miller, Howard Greenblatt, Duane Degler, Marwan Sabbouh and Michel Biezunski.
Resources
Related links are collected at abra.info/lj/rdfa.xhtml.
The example in this article is available at abra.info/lj/rodeo.xhtml.
Golda Velez (goldavelez.info) is a developer, consultant and freelance writer focusing on emerging technologies. She works on developing vocabularies for specialized domains and partnering with domain experts to create vertical sites. She lives with her husband and children in Tucson, Arizona.


{kind=link}