
New Projects - Fresh from the Labs
In the multitude of first-person shooter projects available comes a particularly solid one: Warsow. Warsow is based on the Qfusion 3-D engine (itself a modification of the Quake 2 GPL engine); however, it runs as a completely standalone package and has a solid feel, avoiding the tackier drawbacks of a simple mod. For those of you about to say, “I've seen it all before”, hold on, because this is a particularly solid outing with some fresh approaches to game dynamics in an already-stale genre.
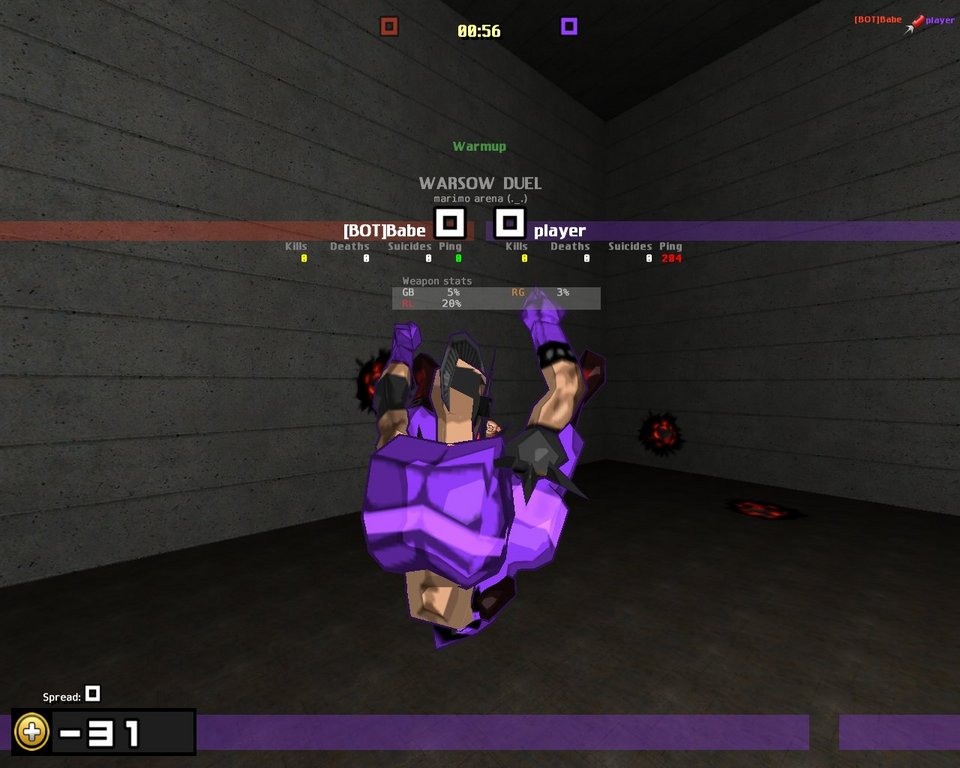
Warsow
Warsow has two elements in particular that make it stand out from the rest: speed and motion. Warsow is all about how you move around in the 3-D world. It's about fluidity, motion and some interesting changes to game balance. Particularly interesting are moves, such as the “Wall Jump”, where pressing a special key when touching a wall allows you to rebound while jumping, or probably the game's main dynamic, “Bunny Hopping”. Bunny Hopping has been in first-person games since you could first jump, but Warsow adds the element of increased momentum and speed, allowing for a slew of new gameplay tactics and design elements.
Don't be put off by seeing Quake 2 either, Qfusion is not an old and ugly engine destined to turn out some clunky old game that looks blockier than a LEGO factory with clumsy control. Warsow is an elegant title including great architecture, gameplay and feel, with its own unique cards brought to the table. Warsow has a unique approach to weapons with two types of ammo: the stock ammo that comes with a weapon (weaker) and stronger ammo once more is collected. Aesthetics also play a large part, in particular, a cell shading look similar to manga and the like, lending the game a feel of something like a cross between Quake III and Nerf Arena Blast. Part of this cell shading ideal is to remove the ultra-realistic, gritty feel of most modern shooters and to reduce the violent content and feel with something more lighthearted with a comic inspiration (which is, indeed, a welcome relief).

Despite the old Quake 2 base, Qfusion's modifications allow for some great architecture, as seen in Warsow.
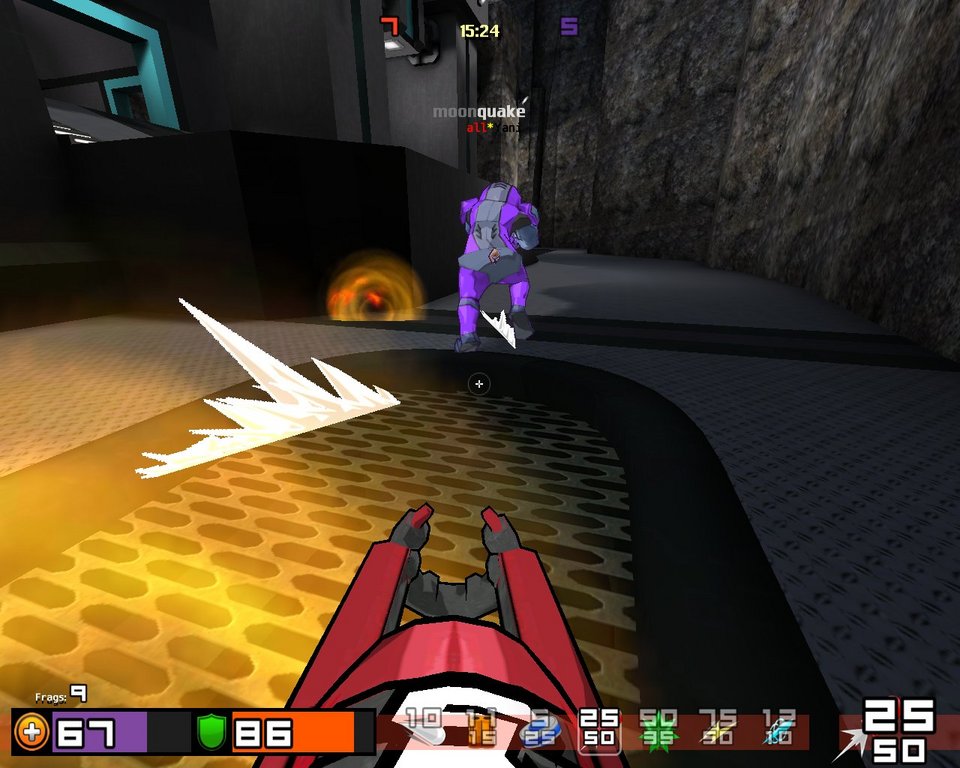
Cell shading makes Warsow's environment much more colorful and lighthearted than today's standard grizzly fare of action games.
Installation
Installing Warsow is very easy. Available on the Web site is a unified package containing both Windows and Linux binaries. Download this, and extract it to somewhere convenient. Open the new folder either with a file manager or a terminal if you're the minimalist type. The solitary inconvenience in this package is that you'll have to flag two files as executable: the warsow script and the platform binary that suits your system. For Linux users with an Intel-based machine, you have the choice of warsow.i386 or warsow.x86_64, for 32- and 64-bit systems, respectively.
If you're using a file manager (I use Konqueror for this example, other file managers should be similar), right-clicking on the script and the binary, and choosing Properties and then the Permissions tab will show you the options you need. Check the box for Is executable, and you should be ready to go simply by left-clicking on the warsow script when you're done. For those using a terminal, this should do the trick:
$ chmod u+x warsow warsow.i386
Once done, start the game by entering:
$ warsow
Usage
First things first, I'm afraid that Warsow is a multiplayer-only affair—sorry. However, for those looking to refine their skills without other humans, in-game bots are available (see the game's documentation for more details). Before you jump head on into the action, check out the available tutorials. These are clever presentations using the game itself, but instead of you being in control, it puts the movement “on rails” so to speak, and a voice-over guides you through what is happening.
Once you're confident enough to start the game itself, the controls are the standard FPS affair with WADS controlling the movement, and the Spacebar for jumping, steering and looking around. Shooting is done with the mouse, as well as with the “Special” button, which is used for dashing, wall jumping and the like. All of the controls are re-assignable, however, and it's well worth customizing it to your own needs as well as checking out the game's other controls.
When you're ready, choose join game to search for an arena to play in, or alternatively, you can host one yourself. At first, join game probably will come up with nothing, so you will have to click search down at the bottom to browse for new games. Choose the server that sounds best for you (look for one with other players if you can, obviously), and if you don't have the map installed, Warsow will download it from that game's server.
At the time of this writing, Warsow is at 0.40 status, yet the gameplay is seriously solid. There are a few problems here and there, such as the occasional menu quirk and jolts with the sound, but the level of problems in the game are normally what you'd associate with something close to full release instead of an early demonstration. I imagine that Warsow probably will add things like single-player skirmishes before it gets to something like 0.9 status, but it's already a fantastic piece of work even for the fussiest of players. Keep an eye on this one, and any programming houses, keep an eye on these coders!
I realise I tend to cover wacky things like molecule imaging, telekinesis and 3-D knitting software, but this is something that actually may be of genuine industrial use in everyday life. libdmtx is an open-source project dedicated to providing tools for reading and writing 2-D Data Matrix barcodes. The Data Matrix standard (en.wikipedia.org/wiki/Data_Matrix) is gaining widespread popularity due to its impressive features, but it may be of particular interest to the FOSS community because it's unencumbered by patents and royalty-free (thus, free to use and distribute). Also, the existing proprietary solutions can be quite expensive, and libdmtx now has reached a point where it realistically can save some users six-digit savings every year.
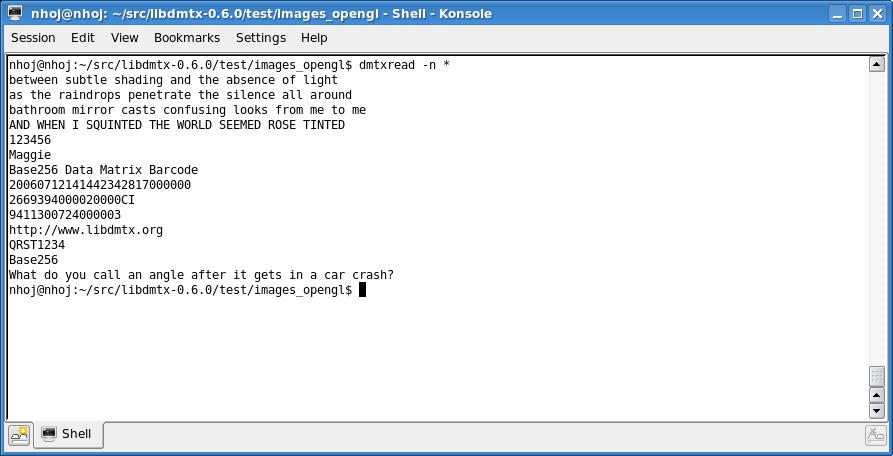
Data Matrix barcodes also can hold secret messages along with the usual barcode data as shown here.
Data Matrix barcodes have been around since the 1980s, but for years, they were used only to mark electronic components. More recently, they have been adopted by a wide variety of industries in the US and Europe, and they are becoming especially popular with mobile phone developers due to their affinity to work with small digital cameras. Most US readers instantly will recognize Data Matrix barcodes, as they appear on most first-class mail delivered by the US Postal Service. Curious readers can snap a photo of their mail with a camera or Webcam and scan it with libdmtx without purchasing any special hardware (it also works well with faxed and scanned images).



libdmtx has the ability to find and decrypt barcodes under a variety of trying conditions.
Installation
Installing libdmtx is fairly straightforward with either a Debian package available under the name of libdmtx-utils or a source tarball. For those installing via source, compiling is basically the standard affair of:
$ ./configure $ make
And, as root or sudo:
# make install
However, the configure script did come up with a dependency you probably won't have installed by default, GraphicsMagick. GraphicsMagick is in many distro repositories though, and to get past the configure script, I had to install libgraphicsmagick1 and libgraphicsmagick1-dev from the Ubuntu archive.
Once you have libdmtx compiled, before you can run the program, you probably will need to run the following command (as root or sudo):
# ldconfig
Usage
I cover only very basic usage in reading barcodes for now, but libdmtx also will write barcodes along with a bunch of other features that make it worth checking the man pages. First, grab an image to test. If you have a photo of a barcode around, great stuff, use that. Otherwise, some test images are available from the source tarball under the folder test/images_opengl, which cover a variety of different situations and tricky tests on libdmtx's abilities. Once you're ready to go, use the following command:
$ dmtxread nameofimage.png
And, that's pretty much all you need to do. dmtxread will spend a few seconds analyzing the image you've given it, and if it finds a matrix barcode, it then outputs the contained text to the terminal. Check the screenshot for some of the hidden messages and real-world codes that you can contain within a barcode.
What really intrigued me about this project is that you can recover barcode data from old pictures that never would have been meant for the purpose originally. And, the James Bond in me gets a kick out of knowing you can hide a message in a barcode in a seemingly unrelated picture as a covert method of communication—neat! Although this has just a command-line utility for now, it's really only a basic program on top of a very clever and versatile library. This project is begging for a GUI front end, at which point, it could make some serious inroads and savings in the real industrial world.
Finally, we have a tool that will end some serious headaches, whohas. According to the project's readme file:
whohas is a command-line tool that allows querying several package lists at once—currently supported are Arch, Debian, Gentoo and Slackware. whohas is written in Perl and was designed to help package maintainers find ebuilds, pkgbuilds and similar package definitions from other distributions to learn from. However, it also can be used by normal users who want to know: what distribution has packages available for apps upon which the user depends and what version of a given package is in use in each distribution or in each release of a distribution (implemented only for Debian).
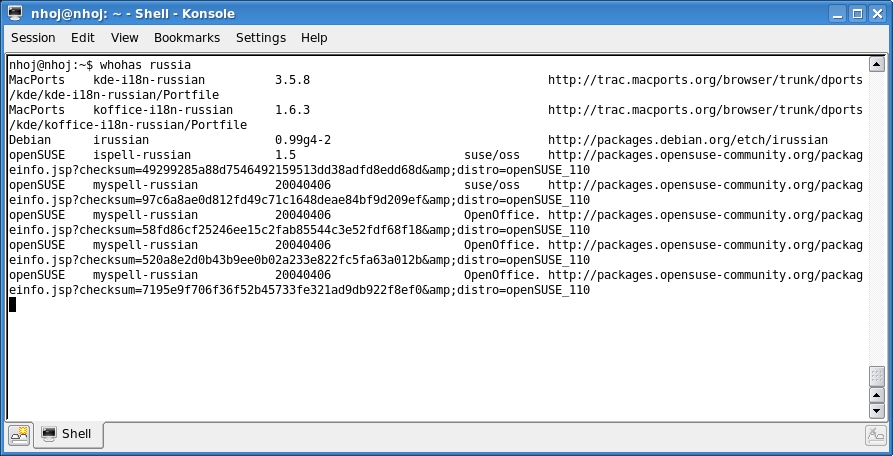
whohas makes finding obscure packages a breeze.
Installation
whohas is genuinely very easy to install and is unlikely to have unresolved dependencies on most systems. Compilation isn't a worry either, as whohas is merely a Perl script that gets copied into your /usr/bin directory. To install whohas, grab the latest tarball from the whohas Web site, extract the contents, and open a terminal in the new folder. Then, as root or sudo, enter the following command:
# ./install.sh
Usage
Once whohas is installed, using the program is as easy as entering:
$ whohas nameofpackage
You needn't be super-specific either. A simple search like “quake”, “audacity” or “chartr” will do fine—no need for entering something like “chartr_0.16_i386.deb”. whohas then scans a number of repositories and prints the results out to screen one by one. If nothing comes up at first, don't despair; it still might be searching. whohas also provides URLs to more details about the package, so project maintainer Philipp Wesche recommends using a terminal that recognises hyperlinks and allows easy forwarding to the browser. And, as with most *nix command-line programs of this nature, the results can be piped through to grep and the like for further refinement (and if you know what that means, you don't need me to explain how it works).
I'm hoping whohas will become an everyday tool the way we use something like whereis or grep. whohas is a fantastic little project that should have existed years ago, and hopefully, it will make its way into many distributions by default.
Brewing something fresh, innovative or mind-bending? Send e-mail to newprojects@linuxjournal.com.
John Knight is a 24-year-old, drumming- and climbing-obsessed maniac from the world's most isolated city—Perth, Western Australia. He can usually be found either buried in an Audacity screen or thrashing a kick-drum beyond recognition.

