
How We Should Program GPGPUs
Using GPUs for general-purpose computing is attractive because of the high-compute bandwidth available, yet programming them still is a costly task. This article makes the claim that current GPU-oriented languages, like CUDA or Brook, require programmers to do a lot of busy work and keep track of a lot of details that would be better left to a compiler. I argue that host-based, accelerator-enabled C, C++ and FORTRAN compilers are feasible with current technology and discuss the issues and difficulties with automatic compilation for GPUs and how to address them.
Today's programmable GPUs are the latest instantiation of programmable accelerators. Going back to the 1970s, the Floating Point Systems AP-120 and FPS-164 attached processors provided mainframe computational speeds at minicomputer cost. Many other vendors built similar products until the advent of the full mini-supercomputer. Today, we have the Clearspeed board, selling into much the same market. In the embedded world, music players and digital phones use programmable digital signal processors (DSPs) to encode and decode audio. Typically, they use dedicated hardware blocks to handle the video to minimize power requirements. In each case, the accelerator is designed to improve the performance for a particular family of applications, such as scientific computing or signal processing. GPUs are themselves (obviously) designed to speed up graphic shaders.

Figure 1. NVIDIA Architecture Block Diagram
Accelerators are made programmable so as to be as flexible as possible. DSPs can be reprogrammed to handle new encoding standards or to use more efficient algorithms, for example. The programming strategy always is a trade-off between performance and convenience, and efficiency and productivity. Designing a language that is close to the hardware allows a user to write as efficient a program as possible, yet such a program likely will have to be rewritten for each such accelerator. It even may need re-tuning for different generations of accelerator from the same vendor and may bear no resemblance to the corresponding CPU program from which it was ported. On the other hand, using a higher-level language puts performance in the hands of a compiler, which may leave a significant fraction of the potential on the table.
Some arguments in favor of a lower-level language are that many programmers want that level of control; compiler development is expensive and time consuming; hardware moves so quickly that compilers are out of date by the time they are tuned properly; and programmers don't trust compilers to deliver good performance.
There are similarities between these arguments and those used 50 years ago during the development of the first high-level languages. When developing the first FORTRAN compiler, the state of the art of programming was machine or assembler language. The developers at IBM realized they had to overcome a very high-acceptance barrier before anyone would be willing to adopt the language. Where would we be today had they not forged ahead? Although FORTRAN is out of favor with most Linux programmers, I submit that all subsequent imperative languages are descendants of, and owe a debt to, that first FORTRAN effort, which formalized named procedures and variables, and introduced the if keyword and the assignment statement (and what languages have no assignment statement?).
Now, having had some years of experience programming GPUs in various ways, we should look at whether we can use less-specific (and less-arcane), more general-purpose languages, open up GPU programming to a wider audience, and still achieve high performance.
Vector computing was first introduced in the 1960s, but was commercially successful only with the introduction of the Cray 1 in 1976. It may be difficult for less-experienced developers to believe, but the Cray 1's 80MHz clock (12.5ns) was the fastest on the planet, and it was the fastest scalar machine available at the time. In addition, the Cray 1 had a vector instruction set that could deliver floating-point results six to ten times faster than the corresponding scalar code. Because the payoff was so high, programmers were quite willing to invest nontrivial effort to make sure their programs ran as fast as possible.

Figure 2. Cray 1 Supercomputer at the Computer History Museum, Photograph by Ed Toton, April 15, 2007
As with GPUs and accelerators today, the parallelism exploited on a Cray covered a wide range of applications, but it was not universal; it tended to self-select the applications that were ported to it. Moving a program to the Cray may have required changing an algorithm to one that was more amenable to vector processing, changing the data layout and, even with appropriate algorithms and data, may have required recoding the program to expose the parallelism. When it first was introduced, many users decried the effort they had to expend. In response, many optimized library kernels (such as the BLAS) were introduced, which could be written in assembly and presumably were highly optimized—programs that used these kernels for computationally intensive regions could expect good performance.
Some of the Cray 1's contemporaries and competitors introduced new languages or language extensions. The Control Data Cyber 205 exposed its vector instruction set in its version of FORTRAN.
Writing a(1;n) meant a vector starting at a(1) with a length of n. Two vectors could be added, as a(1;n) + b(2;n). Nontrivial operations were handled by a large set of Q8 intrinsics, which generated inline code. The expression q8ssum(a(1;n)) would generate the vector instruction to compute the single-precision summation of the vector a(1;n). Such an approach made programming the Cyber 205 costly, and programs optimized for it were not portable.
The Texas Instruments' Advanced Scientific Computer (TI-ASC) came with an aggressive automatic vectorizing compiler, though the machine was not a commercial success. The Cray Fortran Translator (CFT) was the first widely used vectorizing compiler, and it became the dominant method by which the Cray vector instruction set was used. Many tuned libraries still were written in assembly, but the vectorizing compiler was good enough that most programmers could use it effectively.
Although CFT did an effective job of vectorization, the key to its success was something else. It was one of the first compilers that gave performance feedback to the user. The compiler produced a program listing that included a vectorization table. It would tell which loops would run in vector mode and which would not. Moreover, if a loop failed to vectorize, the compiler gave very specific information as to why not, down to which variable or array reference in which statement in the loop prevented vectorization. This had two effects; the first was that programmers knew what to change to make this loop run faster.
The second effect was that programmers became trained to write vector loops: take out procedure calls, don't use conditionals, use stride-1 array references and so on. The next program they wrote was more likely to vectorize from the start. After a few years, programmers were quite comfortable using the “vectorizable subset” of the language, and they could achieve predictable high performance. An important factor in this success was that the style of programming the compiler encouraged was portable, in that it gave predictably good performance across a wide range of vector computers, from Cray, IBM, NEC, Fujitsu, Convex and many others.
More recently, SSE registers with packed arithmetic instructions were added to the X86 architecture with the Pentium III in 1999. When first introduced, compilers were enhanced with a large set of intrinsics that operated on 128-bit wide data; _mm_add_ss(m,n) would do a packed four-wide single-precision floating-point add on two __m128 operands, which presumably would be allocated to XMM registers.
PGI applied classical vectorization technology in its version 3.1 C and FORTRAN compilers to generate the packed arithmetic instructions automatically from loops. The other x86 compilers soon followed, and this is now the dominant method by which the SSE instructions on the x86 are used. Again, there are library routines written in assembly, but the compilers are good enough to be used effectively. As with the Cray compilers, performance feedback is crucial to effective use. If performance is critical, programmers will look at the compiler messages and rewrite loops that don't vectorize.
Current approaches to programming GPUs still are relatively immature. It's much better than it was a few years ago, when programmers had to cast their algorithms into OpenGL or something similar, but it's still unnecessarily difficult.
Programmers must manage (allocate and deallocate) the device, deal with the separate host and device memories, allocate and free device memory, and move data from and to the host, manage (upload) the kernel code, pack up the arguments, initiate the kernel, wait for completion and free the code space when done. All this is in addition to writing the kernel in the first place, exposing the parallelism, optimizing the data access patterns and a host of other machine-specific items, testing and tuning. A matrix multiplication takes a few lines in FORTRAN or C. Converting this to CUDA or Brook takes a page or more of code, even when making simplifying assumptions. One might question whether there is a better way.
Listing 1. Simplified Matrix Multiplication in CUDA, Using Tiled Algorithm
__global__ void
matmulKernel( float* C, float* A, float* B, int N2, int N3 ){
int bx = blockIdx.x, by = blockIdx.y;
int tx = threadIdx.x, ty = threadIdx.y;
int aFirst = 16 * by * N2;
int bFirst = 16 * bx;
float Csub = 0;
for( int j = 0; j < N2; j += 16 ) {
__shared__ float Atile[16][16], Btile[16][16];
Atile[ty][tx] = A[aFirst + j + N2 * ty + tx];
Btile[ty][tx] = B[bFirst + j*N3 + b + N3 * ty + tx];
__syncthreads();
for( int k = 0; k < 16; ++k )
Csub += Atile[ty][k] * Btile[k][tx];
__syncthreads();
}
int c = N3 * 16 * by + 16 * bx;
C[c + N3 * ty + tx] = Csub;
}
void
matmul( float* A, float* B, float* C,
size_t N1, size_t N2, size_t N3 ){
void *devA, *devB, *devC;
cudaSetDevice(0);
cudaMalloc( &devA, N1*N2*sizeof(float) );
cudaMalloc( &devB, N2*N3*sizeof(float) );
cudaMalloc( &devC, N1*N3*sizeof(float) );
cudaMemcpy( devA, A, N1*N2*sizeof(float), cudaMemcpyHostToDevice );
cudaMemcpy( devB, B, N2*N3*sizeof(float), cudaMemcpyHostToDevice );
dim3 threads( 16, 16 );
dim3 grid( N1 / threads.x, N3 / threads.y);
matmulKernel<<< grid, threads >>>( devC, devA, devB, N2, N3 );
cudaMemcpy( C, devC, N1*N3*sizeof(float), cudaMemcpyDeviceToHost );
cudaFree( devA );
cudaFree( devB );
cudaFree( devC );
}
Listing 2. Simplified Matrix Multiplication in Brook
kernel void
matmulKernel( float N2, float A[][], float B[][],
out float result<> ){
float2 ik = indexof(result).xy;
float4 ijjk = float4( ik.x, 0.0f, 0.0f, ik.y );
float4 jp1 = float4( 0.0f, 1.0f, 1.0f, 0.0f );
float C = 0.0f;
float n2 = N2;
while( n2 > 0 ) {
C += A[ijjk.zw]*B[ijjk.xy];
ijjk += jp1;
n2 -= 1.0f;
}
result = C;
}
void
matmul( float* A, float* B, float* C,
size_t N1, size_t N2, size_t N3 ){
float Astream<N1, N2>;
float Bstream<N2, N3>;
float Cstream<N1, N3>;
streamRead( Astream, A );
streamRead( Bstream, B );
matmulKernel( (float)N2, Astream, Bstream, Cstream );
streamWrite( Cstream, C );
}
Compilers are good at keeping track of details and should be taken advantage of for that as much as possible. Is there anything specific to a GPU that makes it a more difficult compiler target than vector computers or attached processors, both of which had very successful, aggressive compilers? Could a compiler be created that would generate both host and GPU or accelerator code from a single source file, using standard C or FORTRAN, without language extensions?
I think it's feasible (though nontrivial), and a good idea. Here, I discuss what such a compiler might look like and what steps it would have to take. Two overriding goals are that the compiler operates just like a host compiler, except perhaps with a command-line flag to enable or disable the GPU code generator, and that no changes are needed to the other system tools (such as a linker and library archiver).
A significant difference between such a compiler and one for a vector computer has to do with the cost of failure. If a compiler fails to vectorize a specific loop, the performance cost can be a factor of five or ten, which is enough that a programmer will pay attention to messages from the compiler. If a compiler does a bad job of code generation for a GPU, the cost can be a slowdown (relative to host code) of a factor of ten or 100. This is enough that a fully hands-off, automatic approach just isn't feasible, at least not yet. At all steps, a programmer must be able to understand what the compiler has done and, if necessary, to override it.
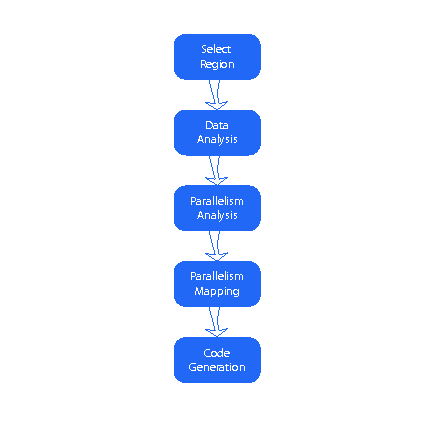
Figure 3. Five-Step Flowchart
The first, and perhaps most important step is to select what part or parts of the program should be converted to a kernel. Currently, that is done explicitly by a programmer who rips out that part of the program, replaces it with the code to manage the GPU, writes a kernel to execute on the GPU and combines it all into a single program.
Abstractly, we can use compute intensity to determine the parts of the program that are attractive for GPU acceleration. Compute intensity for a function, loop or block of code is the ratio of the number of operations to the amount of data that needs to be moved. For GPU computing, we are most limited by the host-GPU bandwidth, so the critical ratio is the amount of data that needs to be moved from the host to GPU and back, divided into the number of operations that the GPU will execute. If the ratio is high enough, it's worth the cost of the data movement to get the high compute bandwidth of the GPU, assuming the computation has enough parallelism.
Listing 3. Fortran Matrix Multiplication Loop, Tagged to Be Compiled for the Accelerator
!$acc begin
do i = 1,n1
do k = 1,n3
c(i,k) = 0.0
do j = 1,n2
c(i,k) = c(i,k) + a(i,j) + b(j,k)
enddo
enddo
enddo
!$acc end
Although a compiler may be able to determine or estimate compute intensity, there are enough issues with GPU computing that it's better to leave this step to the programmer. Let's suppose a programmer can add a pragma or directive to the program, telling the compiler that a particular routine or loop or region of code should be compiled for the GPU.
The second step is data analysis on the region: what data needs to be allocated on the device memory and what needs to be copied from the host and back to the host afterward? This is within the scope of current compiler technology, though peculiar coding styles can defeat the analysis. In such cases, the compiler reports usage patterns with strange boundary conditions; usually, it's easy to determine where this comes from and adjust the program to avoid it. In many cases, it arises from a potential bug lurking in the code, such as a hard-coded constant in one place instead of the symbolic value used everywhere else. Nonetheless, the compiler must have a mechanism to report the data analysis results, and the user must be able to override those results, in cases where the compiler is being too conservative (and moving too much data, for example).
The third step is parallelism analysis on the loops in the region. The GPU's speed comes from structured parallelism, so parallelism must be rampant for the translation to succeed, whether translated automatically or manually. Traditional vectorizing and parallelizing compiler techniques are mature enough to apply here. Although vectorizing compilers were quite successful, both practically and commercially, automatic parallelization for multiprocessors has been less so. Much of that failure has been due to over-aggressive expectations. Compilers aren't magic; they can't find parallelism that isn't there and may not find parallelism that's been cleverly hidden or disguised by such tricks as pointer arithmetic.
Yet, parallelism analysis for GPUs has three advantages. First, the application domain is likely to be self-selected to include those with lots of rampant, structured parallelism. Second, structured parallelism is exactly the domain where the classical compiler techniques apply. And finally, the payoff for success is high enough that even when automatic parallelization fails, if the compiler reports that failure specifically enough, the programmer can rewrite that part of the code to enable the compiler to proceed.
The fourth step is to map the program parallelism onto the machine. Today's GPUs have two or three levels of parallelism. For instance, the NVIDIA G80 architecture has multiprocessor (MIMD) parallelism across the 16 processors. It also has SIMD parallelism within each processor, and it uses another level of parallelism to enable multithreading within a processor to tolerate the long global memory latencies. The loop-level program parallelism must map onto the machine in such a way as to optimize, as much as possible, the performance features of the machine. On the NVIDIA, this means mapping a loop with stride-1 memory accesses to the SIMD-level parallelism and mapping a loop that requires synchronization to the multithread-level parallelism. This step is likely very specific to each GPU or accelerator.
The fifth step is to generate the GPU code. This is more difficult than code generation for a CPU only because the GPU is less general. Otherwise, this uses standard code-generation technology. A single GPU region may generate several GPU kernels to be invoked in order from the host. Some of the code-generation goals can be different from that of a CPU. For instance, a CPU has a fixed number of registers; compilers often will use an extra register if it allows them to schedule instructions more advantageously. A GPU has a large number of registers, but it has to share them among the simultaneously active threads. We want a lot of active threads, so when one thread is busy with a global memory access, the GPU has other work to keep it busy. Using extra registers may give a better schedule for each thread, but if it reduces the number of active threads, the total performance may suffer.
The final step is to replace the kernel region on the host with device and kernel management code. Most of this will turn into library calls, allocating memory, moving data and invoking kernels.
These five steps are the same that a programmer has to perform when moving a program from a host to CUDA or Brook or other GPU-specific language. At least four of them can be mostly or fully automated, which would simplify programming greatly. Perhaps OpenCL, recently submitted by Apple to the Khronos Group for standardization, will address some of these issues.
There are some other issues that still have to be addressed. One is a policy issue. Can a user grab the GPU and hold onto it as a dedicated device? In many cases, there is only one user, so sharing the device is unimportant, but in a computing center, this issue will arise. Another issue has to do with the fixed size, nonvirtual GPU device memory. Whose job is it to split up the computation so it fits onto the GPU? A compiler can apply strip-mining to the loops in the GPU region, processing chunks of data at a time. The compiler also can use this strategy to overlap communication with computation by sending data for the next chunk while the GPU is processing the current chunk.
There are other issues that aren't addressed in this article, such as allocating data on the GPU and leaving it there for the life of a program, or managing multiple GPUs from a single host. These can all be solved in the same framework, all without requiring language extensions or wholesale program rewrites.
The future for GPU programming is getting brighter; these devices will become more convenient to program. There is no magic bullet; only appropriate algorithms written in a transparent style can be compiled for GPUs; users must understand and accept their advantages and limitations. These are not standard processor cores.
The industry can expect additional development of programmable accelerators, targeting different application markets. The cost of entering the accelerator market is much lower than for the CPU market, making a niche target market potentially attractive. The compiler method described here is robust enough to provide a consistent interface for a wide range of accelerators.
Michael Wolfe has been a compiler engineer at The Portland Group since joining in 1996, where his responsibilities and interests include deep compiler analysis and optimizations ranging from improving power consumption for embedded microcores to improving the efficiency of FORTRAN on parallel clusters. He has a PhD in Computer Science from the University of Illinois and authored High Performance Compilers for Parallel Computing, Optimizing Supercompilers for Supercomputers and many technical papers.

