
Hack and / - Manage Multiple Servers Efficiently
Through the years I've had to manage a wide-ranging number of different servers. At one job, I started with only a few and expanded to around ten, while at another job, I've managed hundreds. In both cases, I've found that you just can't accomplish everything you need to do efficiently when you log in to machines one at a time. Over the years, I've discovered a couple tools and techniques that certainly make it easier. Now granted, even these techniques can scale only so far. If you have a very large environment, you probably will be best served with some sort of centralized management tool like Puppet, cfengine or other tools that you can buy from vendors. Even so, for those of you who have a small-to-medium environment at work (or at home), here are some tricks to help you manage those machines better.
A common need you have when there are more than a few servers in your environment is to run the same command on more than one machine. When I first had this problem, I came up with a pretty simple shell script:
$ HOSTS="machine1 machine2 machine3 machine4"; ↪for i in $HOSTS; do ssh $i uname -a; done;
This one-liner iterates through each machine I've listed in the HOSTS environment variable and runs uname -a. You can, of course, replace uname -a with any command-line command that you would want to run on the hosts. For instance, one need I had was to keep all of my Debian servers up to date. I created a small shell script on each Debian host called /usr/local/bin/apt-automate:
#!/bin/sh apt-get update && apt-get -u upgrade
Then, I edited my /etc/sudoers file, so that my regular user could execute that script as root without a password:
username ALL=(root) NOPASSWD: /usr/local/bin/apt-automate
(Replace username with your local user name for that host.) Once I had the script in place and sudo configured, I set up SSH keys so my user could log in to each of those machines easily. Then, I could update four hosts with a simple one-liner:
HOSTS="machine1 machine2 machine3 machine4"; ↪for i in $HOSTS; do ssh $i sudo apt-automate; done;
Ultimately, I found I executed this one-liner so much, it warranted its own script, which I called update-all:
#!/bin/sh hosts="machine1 machine2 machine3 machine4" # Run the command on each remote host for i in $hosts; do echo $i; ssh $i sudo apt-automate; done; # Also run the command on the local machine sudo apt-automate
Now, this system worked for me at the time, but it has plenty of room for improvement. For one, I potentially could set up a set of environment variables for different host groups. Then, instead of defining HOSTS each time I ran the one-liner, I could reference one of those groups.
When I had only a few hosts to manage, the SSH loop method worked well for me. However, that plan didn't scale quite so well when I needed to manage a few hundred machines in different data centers. For one, I didn't always just need to run a command on a group of machines. Sometimes, I wanted to make the same change to the same file on each of the hosts. Although I could play with Perl, or use awk and sed scripts to edit files in-line, that was prone to mistakes. Lucky for me, I found an invaluable tool for managing small-to-medium server environments called ClusterSSH (clusterssh.sourceforge.net).
ClusterSSH opens a terminal for every machine you want to manage. In addition to these terminals, ClusterSSH opens a small Tk control window. Anything you type into one of the individual terminals will execute just on that server, but anything you type or paste into the Tk window is input into every terminal. The control window also allows you to toggle whether input goes to a particular terminal and allows you to add extra hosts as well.
ClusterSSH is packaged by a number of distributions. If your distribution doesn't have it, you also can download and build the source from the project page. Once the package is installed, execution is simple:
$ cssh host1 host2 host3 host4
A nice feature of ClusterSSH is that it automatically will tile all of the windows for you so that you get the maximum amount of visible screen space on each (Figure 1). This is particularly useful when you operate on a large number of servers at the same time. If you happen to rearrange the windows or add or remove hosts from ClusterSSH, you can press Alt-R or click Hosts→Refile Hosts to rearrange all the windows.
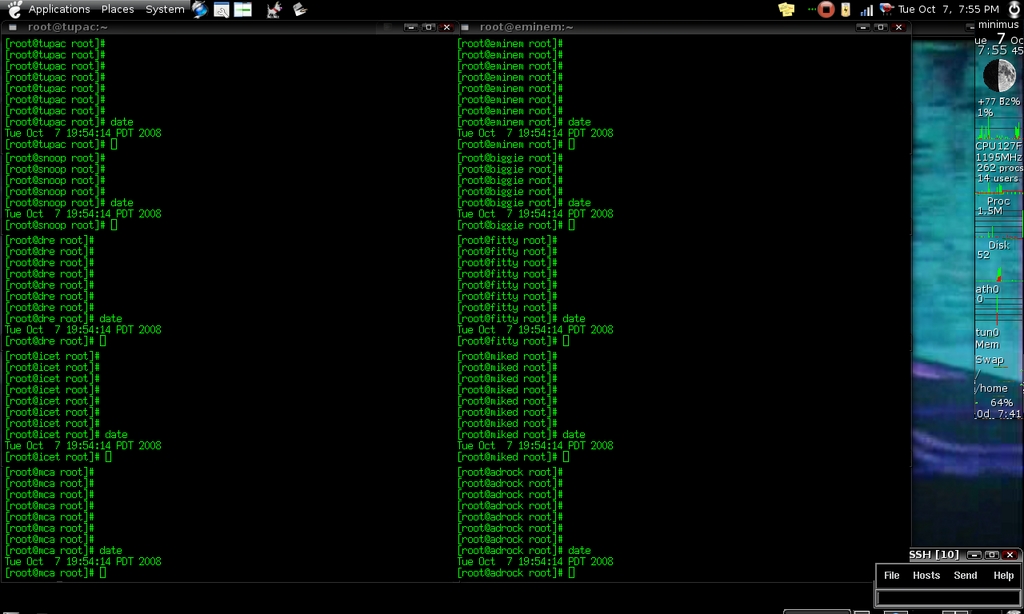
Figure 1. Ten terminal windows tiled by ClusterSSH.
Now you might be saying, “That all looks fine, but you still have to specify all the servers on the command line each time. What if I have a cluster of 30 servers to manage?” Well, ClusterSSH has that covered via its configuration files. In the ~/.csshrc file, you not only can define default settings for ClusterSSH, such as terminal settings, but you also can define groups of servers. If you want to change settings for all users, you can define clusters in the /etc/clusters file and set ClusterSSH parameters in /etc/csshrc. Otherwise, ~/.csshrc works fine as a place to store all the settings for your user. Here's a sample ~/.csshrc that highlights some of the useful options:
terminal_args = -fg green terminal_font = 7x14 clusters = web dbtest dbprod dns web = web1 web2 web3 web4 web5 web6 web7 web8 web9 web10 dbtest = testdba@db1.test.example.net testdba@db2.test.example.net dbprod = proddba@db1.prod.example.net proddba@db2.prod.example.net dns = root@ns1 root@ns2 root@10.1.1.1
The first two options in this file configure terminal settings. First, I set the foreground to green on my xterm (since green on black is the one true terminal color), and then I set the terminal font. The third line sets the clusters option and defines aliases for all the clusters you will define below. Note that if you define a cluster in this file but don't remember to add it to the cluster option, you won't be able to access it. Below the clusters option, I've defined a number of different clusters. The syntax is essentially clustername = serverlist with each hostname separated by spaces. As you can see in the examples, you can specify servers strictly by hostname (in which case your DNS search path will attempt to resolve the fully qualified domain name), by the host's fully qualified domain name or by IP. If you want to log in under a different user name, you also can specify that on a host-by-host basis.
Once your configuration file is in place, you can connect any or all of the cluster aliases on the command line. So, if I wanted to run a command on all the Web servers I would type:
$ cssh web
If I wanted to access both the dbtest and dbprod servers, I would type:
$ cssh dbtest dbprod
One downside when you specify multiple host groups is that if you don't have SSH keys set up, you might have to type in different passwords for each host. In that case, you need to highlight each terminal window individually and then log in. After that, you can return to the Tk control window and execute commands across all hosts.
All in all, I've found ClusterSSH to be an invaluable tool for managing small-to-medium groups of servers. The interface is pretty straightforward, and there is something so cool about being able to paste 20 lines of configuration to a vim session across 30 hosts or quickly run tail against all of your Web server logs. I've found I use it the most to deploy packages to groups of servers. I can single out one server to make sure the package works correctly, then toggle that server off and apply it to the rest.
Kyle Rankin is a Senior Systems Administrator in the San Francisco Bay Area and the author of a number of books, including Knoppix Hacks and Ubuntu Hacks for O'Reilly Media. He is currently the president of the North Bay Linux Users' Group.
