
Building a Scalable High-Availability E-Mail System with Active Directory and More
In early 2006, Marshall University laid out a plan to migrate HOBBIT (Figure 1), an HP OpenVMS cluster handling university-wide e-mail services. Plagued with increasing spam attacks, this cluster experienced severe performance degradation. Although our employee e-mail store was moved to Microsoft Exchange in recent years, e-mail routing, mailing list and student e-mail store (including IMAP and POP3 services) were still served by OpenVMS with about 30,000 active users. HOBBIT's e-mail software, PMDF, provided a rather limited feature set while charging a high licensing fee. A major bottleneck was discovered on its external disk storage system: the dated storage technology resulted in a limited disk I/O throughput (40MB/second at maximal) in an e-mail system doing intensive I/O operations.

Figure 1. HOBBIT OpenVMS Cluster Hardware
To resolve the existing e-mail performance issues, we conducted brainstorming sessions, requirements analysis, product comparison and test-lab prototyping. We then came up with the design of our new e-mail system: it is named MUMAIL (Figure 2) and uses standard open-source software (Postfix, Cyrus-IMAP and MySQL) installed on Red Hat Enterprise Linux. The core system consists of front-end e-mail hub and back-end e-mail store. The front-end e-mail hub uses two Dell blade servers running Postfix on Linux. Network load balancing is configured to distribute load between them. The back-end e-mail store consists of two additional blade servers running a Cyrus-IMAP aggregation setup. Each back-end node is then attached to a different storage group on the EMC Storage Area Network (SAN). A fifth blade server is designated as a master node to store centralized user e-mail settings. Furthermore, we use LDAP and Kerberos to integrate the e-mail user identities with Windows Active Directory (AD).

Figure 2. Linux E-Mail Server Blades and SAN
Figure 3 illustrates our new e-mail system architecture and the subsystem interactions with existing services, which include Webmail, AD and SMTP gateway. The block diagrams highlighted in red are the components to be studied in detail.
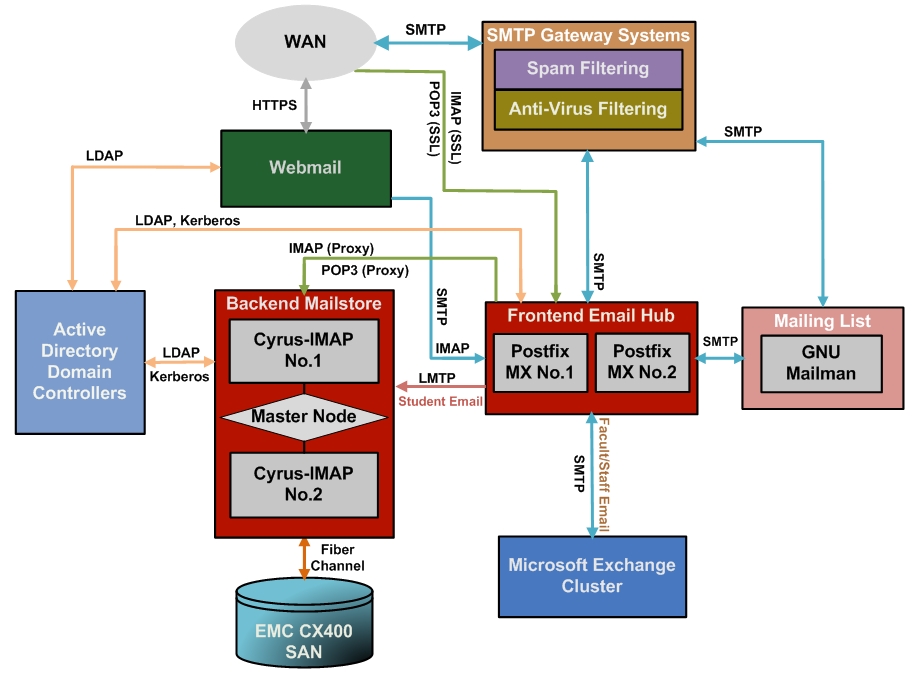
Figure 3. System Architecture
Before we zoom further into our new e-mail system, I want to mention some of the existing Linux/UNIX e-mail solutions in higher-education environments. First, the HEC Montréal e-mail system discussed in a Linux Journal article (see Resources) influenced our design, which is based on Cyrus-IMAP and Postfix. Second, we looked into Cambridge University's solution. It uses custom IMAP proxy front-end servers and multiple pairs of Cyrus-IMAP mail store servers replicating data to each other. Furthermore, Carnegie Mellon University (CMU), which originally developed Cyrus-IMAP, uses Sendmail as the front-end mail exchanger and a Cyrus-IMAP Murder Aggregator setup on the back end. Columbia University moved its e-mail system to a Cyrus-IMAP-based solution in 2006, and the University of Indiana moved to Cyrus back in 2005. Cyrus and Postfix also are used by Stanford University.
Although the designs of these related solutions are different, most of them use a cluster-based approach that separates mail transport/delivery from the mail store. Multiple front-end MTA-MDA (Mail Transport Agent and Mail Delivery Agent) servers are set up to deliver mail to the back-end mail store, which then saves messages either in a filesystem (for example, Maildir) or a database. Most of the solutions use Cyrus-IMAP (on UNIX or Linux) as their mail store server.
Some distinctive differences set our design apart from the existing solutions:
Instead of using a separate directory service (such as OpenLDAP) for user authentication, our design integrates user identities with Windows Active Directory (AD).
Rather than using an LDAP server to store user e-mail routing settings, we designed a relational database to store these settings.
In the mail store setup, instead of using an active-passive high-availability cluster setup, like the HEC approach or the Cyrus replication approach developed at Cambridge, we deployed the Cyrus-Murder Aggregator. Unlike the CMU Cyrus Aggregator server allocation, which uses separate MTA server nodes, we consolidate both MTA and Cyrus Proxy functions to run on our front-end mail hub nodes.
We designed an e-mail user database (running MySQL on the Master node) to serve as a centralized data store for information including e-mail accounts, user e-mail routing, group aliases and mailing lists. Web-based user interfaces were developed using PHP to allow users to make changes to their settings in the database. Automated scripts running on the front-end nodes will query the database for user settings and build Postfix maps to apply these settings.
A Postfix server can be thought of as routers (not for IP packets but for e-mail). For each e-mail message, Postfix looks at the destination (envelope recipient) and the source (envelope sender) and then chooses how to route the e-mail message closer to its destination. Lookup tables called Maps (such as Transport, Virtual, Canonical and Alias Maps) are used to find the next-hop e-mail delivery location or apply e-mail address re-rewrites.
A background job is running on each of the front-end e-mail hub nodes to “pull” the e-mail settings (delivery location, e-mail alias and group alias information) stored in the e-mail user database to the Postfix maps (aliases, virtual, canonical and transport). Written in Perl, the program is configured to run periodically as a crond job.
Our design principle of the new e-mail system is to scale out from a single, monolithic architecture to multiple nodes sharing the same processing load. In a large e-mail environment, scaling out the front-end MTA system is considerably easier compared with scaling out the back-end mail store. As the front-end nodes are essentially data-less, using DNS or IP-based load balancing on multiple front-end servers is a typical practice. However, the same technique cannot be applied to design the back-end mail store where the user data resides. Without clustering, shared storage or additional software components (such as a proxy server), multiple mail store servers cannot share the same IMAP/POP3 process load under a unified service namespace. Because of this, using a single mail store server tends to be an obvious solution. However, one node usually implies elevated server hardware expenses when more powerful server hardware needs to be purchased to accommodate the ever-increasing system load. The price of a mid-range server with four CPUs is usually much higher than the total price of three or more entry-class servers. Furthermore, a single-node architecture reduces system scalability and creates a single point of failure.
The Cyrus-IMAP package is proven to be robust and suitable in large settings. It differs from other Maildir or mbox IMAP servers in that it is intended to run as a “sealed” mailbox server—the Cyrus mailbox database is stored in parts of the filesystem that are private to the Cyrus-IMAP system. More important, a multiple server setup using Cyrus Murder aggregation is supported. It scales out the system's load by using multiple front-end IMAP proxies to direct IMAP/POP3 traffic to multiple back-end mail store nodes. Although we found other ways to scale out Cyrus-IMAP—for example, Cambridge University's pair-wise replication approach, mentioned in the Related Solutions section of this article, or using a clustered filesystem to share IMAP storage partitions between multiple servers with products like Red Hat's Global File System (GFS)—compared with the aggregation approach, these solutions either are too customized to support (the Cambridge approach) or involve extra cost (GFS is sold separately by Red Hat, Inc.).
So, the Cyrus-IMAP Aggregation approach was adopted. Figure 4 illustrates the setup: two Cyrus back-end servers were set up, and each handles half the user population. Two Postfix MTA front-end nodes are designated to serve the proxy functions. When e-mail clients connect through SMTP/IMAP/POP3 to the front-end servers, the Cyrus Proxy service will communicate with the Cyrus Master node using the MUPDATE protocol, so that it gets the information about which Cyrus back-end node stores e-mail for the current client. Furthermore, the back-end Cyrus nodes will notify the Master node about the mailbox changes (creating, deleting and renaming mailboxes or IMAP folders) in order to keep the Master updated with the most current mailbox location information. The Master node replicates these changes to the front-end proxy nodes, which direct the incoming IMAP/POP3/LMTP traffic. The MUPDATE protocol is used to transmit mailbox location changes.
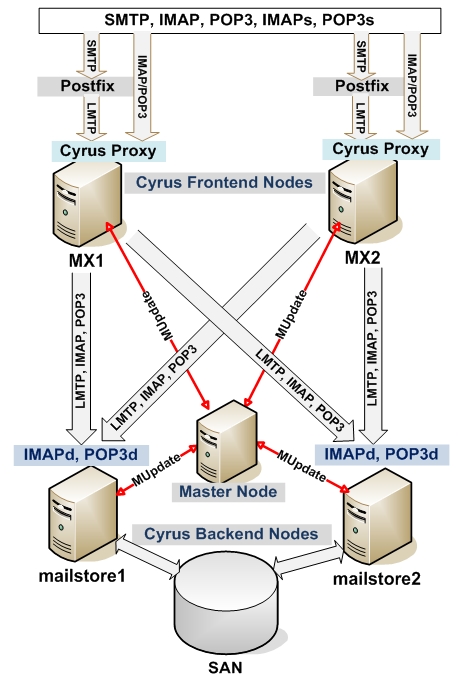
Figure 4. Cyrus-IMAP Aggregation Setup
Although it is not a fully redundant solution (the Master node is still a single point of failure), and half our users will suffer a usage outage if either one of the back-end nodes is down, the aggregator setup divides the IMAP processing load across multiple servers with each taking 50% of the load. As a result of this division of labor, the new mail store system is now scalable to multiple servers and is capable of handling a growing user population and increasing disk usage. More back-end Cyrus nodes can join with the aggregator to scale up the system.
One of the requirements of our new e-mail system is to integrate user identities with the university directory service. Because Microsoft Active Directory services have been made a standard within our centralized campus IT environment, Cyrus (IMAP/POP3) and Postfix (SMTP) are architected to obtain user authentication/authorization from AD. After the integration, all e-mail user credentials can be managed from AD. Most directory services are constructed based on LDAP. AD uses LDAP for authorization, and it has its own Kerberos implementation for authentication. The goal of an integrated AD authentication is to allow the Linux e-mail servers to use AD to verify user credentials. The technology used to support the AD integration scheme is based mainly on the Kerberos and LDAP support, which come with native Linux components, as shown in Figure 5.
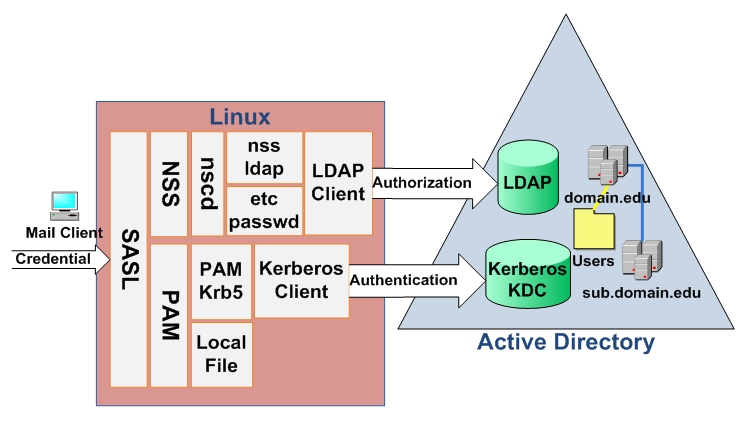
Figure 5. Linux Authentication and Authorization Against AD
Here is how it works. First, we use AD Kerberos to authenticate Linux clients. Pluggable Authentication Module (PAM) is configured to get the user credentials and pass them to the pam_krb5 library, which is then used to authenticate users using the Linux Kerberos client connection to the Key Distribution Center (KDC) on Active Directory. This practice eliminates the need for authentication administration on the Linux side. However, with only the Kerberos integration, Linux has to store authorization data in the local /etc/passwd file. To avoid managing a separate user authorization list, LDAP is used to retrieve user authorization information from AD. The idea is to let authorization requests processed by Name Service Switch (NSS) first. NSS allows the replacement of many UNIX/Linux configuration files (such as /etc/passwd, /etc/group and /etc/hosts) with a centralized database or databases, and the mechanisms used to access those databases are configurable. NSS then uses the Name Service Caching Dæmon (NSCD) to improve query performance. (NSCD is a dæmon that provides a cache for the most common name service requests.) This can be very important when used against a large AD user container. Finally, NSS_LDAP is configured to serve as an LDAP client to connect to Active Directory to retrieve the authorization data from the AD users container. (NSS_LDAP, developed by PADL, is a set of C library extensions that allow LDAP directory servers to be used as a primary source of aliases, ethers, groups, hosts, networks, protocol, users, RPCs, services and shadow passwords.) Now, with authorization and authentication completely integrated with AD using both LDAP and Kerberos, no local user credentials need to be maintained.
In order to support LDAP authorization integration with Linux, Windows Server 2003 Release 2 (R2), which includes support for RFC 2307, is installed on each of the AD domain controllers. R2 introduces new LDAP attributes used to store UNIX or Linux user and group information. Without an extended AD LDAP schema, like the one used by R2, the Linux automatic authorization integration with AD is not possible. It is also important to mention that the SASL Authentication layer shown in Figure 3 is using Cyrus-SASL, which is distributed as a standard package by Carnegie Mellon University. The actual setup uses PAM for authenticating IMAP/POP3 users. It requires the use of a special Cyrus dæmon, saslauthd, which the SASL mechanism uses to communicate via a Linux-named socket.
Our new e-mail system is mostly based on open-source software. The incorporation of Postfix, Cyrus-IMAP and MySQL helped fulfill most of the system requirements. From the hardware perspective, the technologies used, such as Storage Area Network (SAN), blade server and the Intel x86_64 CPUs, helped to meet the requirements of fast access, system scalability and high availability. However, the use of open-source software and new hardware technologies may introduce new management overhead. Although all the open-source software packages used on the new system are mature products, compared with commercial software, they typically lack a GUI for system management. Their configuration and customization are completely based on a set of plain-text configuration files. Initially, this may present a learning curve, as the syntax of these configuration files must be studied. But, once the learning curve is passed, future management easily can be automated, as scripts can be written to manage the configuration parameters and store them in a centralized location. On the hardware side, complex settings also may imply complex network and server management settings, which also may introduce overhead during system management. However, the benefits of using the technologies discussed outweigh the complexities and learning curves involved. It is easy to overcome the drawbacks through proper design, configuration management and system automation.
At the time of this writing, our new Linux e-mail system (MUMAIL) has been running in production for ten months. The entire system has been running in a stable state with minimal downtime throughout this period. All user e-mail messages originally on HOBBIT were moved successfully to MUMAIL in a three-day migration window with automated and non-disruptive migration processes. Users now experience significantly faster IMAP/POP3 access speed. Their e-mail storage quota is raised from 20MB to 200MB, and there is potential to increase the quota to a higher number (1GB). With the installation of gateway-level spam/virus firewalls as well as increased hardware speed, no e-mail backlog has been experienced on MUMAIL during recent spam/virus outbreaks. With an Active Directory integrated user authentication setup, user passwords or other sensitive information are no longer stored on the e-mail system. This reduces user confusion and account administration overhead and increases network security. Mail store backup speed is improved significantly with faster disk access in the SAN environment. Finally, the new system has provided a hardware and software environment that supports future growth with the adoption of a scalable design. More server nodes—both front end and back end—and storage can be added when system usage grows in the future.
Resources
“Migration of Alcator C-Mod Computer Infrastructure to Linux” by T. W. Fredian, M. Greenwald and J. A. Stillerman: www.psfc.mit.edu/~g/papers/fed04.pdf
“HEC Montréal: Deployment of a Large-Scale Mail Installation” by Ludovic Marcotte: www.linuxjournal.com/article/7323
Cyrus-IMAP Aggregation: cyrusimap.web.cmu.edu/ag.html
“Scaling up Cambridge University's E-Mail Service” by David Carter and Tony Finch: www-uxsup.csx.cam.ac.uk/~fanf2/hermes/doc/talks/2004-02-ukuug/paper.html
CMU's Cyrus-IMAP Configuration: cyrusimap.web.cmu.edu/configuration.html
Columbia's Cyrus-IMAP Move: www.columbia.edu/cu/news/05/12/cyrus.html
Indiana's Cyrus-IMAP Information: uitspress.iu.edu/040505_cyrus.html
Stanford's E-Mail System Discussion: www.stanford.edu/dept/its/vision/email.html
Windows Security and Directory Services for UNIX Guide: www.microsoft.com/downloads/details.aspx?familyid=144f7b82-65cf-4105-b60c-44515299797d&displaylang=en
“Toward an Automated Vulnerability Comparison of Open-Source IMAP Servers” by Chaos Golubitsky: www.usenix.org/events/lisa05/tech/golubitsky/golubitsky.pdf
Jack Chongjie Xue holds a Masters' degree in Information Systems from Marshall University, where he did Linux and Windows systems administration work. His job duties now include developing Business Intelligence applications and working on data mining projects at Marshall.
