
Exploiting 64-Bit Linux
Wide availability of 64-bit systems offers an opportunity to simplify programming. By leveraging large virtual addresses and memory mapped files, we combine programming and file persistence into a single activity. This simplifies programming when persistence and sharing of large complex data structures are required. It also improves the efficiency of data access and sharing, as multiple programs can access data directly (operate in place) from the single real page copy. This eliminates the need to copy the data through multiple layers of buffering. When all programs share data at the same virtual address, there are opportunities for the kernel to manage the memory map to avoid aliases and share MMU resources across applications.
As a proof of concept, I have a small user library I call SPHDE (Shared Persistent Heap/Data Environment). This library manages a portion of the application's address space to provide blocks of persistent and shared storage. The library also provides some locking primitives and some “utility objects” that provide finer-grained storage allocation and indexing.
As a demonstration, I wrote a gigapixel Mandelbrot (GTK2) GUI program. This program computes each point in the Mandelbrot set once and saves the resulting image as a quadtree in SPHDE storage. This quadtree representation can be shared and displayed by multiple instances of the program. Program instances can cooperate to fill in the next level of detail.
System design and programming models are (initially) driven by the need to manage scarce resources. In the early days of programming, both address spaces and physical memory were small. IO Subsystems evolved to manage the buffering of serial media, such as tape and punch cards. Even the introduction of random access disk and virtual memory did not change the basic paradigm much. The programming paradigms we use and teach today have far outlived the original scarcity that caused them. The separation of programming from persistent data is a prime example. It creates inefficiencies in both programming effort and runtime execution.
With the prevalence of 64-bit microprocessors, the original (addressing/memory) scarcity is gone. We can leverage virtual memory to access and share massive data structures directly using “operate in place” and “implicit persistence” patterns. This simplifies programming, because any data structure is implicitly persistent by where it is allocated. This improves operational efficiency, because it eliminates layers of buffer management and the OS has more opportunities to share a single physical copy. There are additional opportunities for improving address translation efficiency by eliminating address aliasing and exploiting hardware features, such as large pages.
There have been attempts to unify programming and persistence before. Persistence frameworks abound, but they simply add layers of buffering and data conversions to the top of the IO Subsystem stack. Operational efficiency is lost to obtain a modest reduction in programming effort.
Alternatively, Single-Level Stores have been a research topic for years. Although the technology works (simplified programming and data efficiency), the requirement for specialized hardware or unique OS environments has limited acceptance.
This picture changes again with widely available 64-bit microprocessors and standardized POSIX memory management APIs. The addition of a small runtime library allows adventurous programmers to use operate in place and implicit persistence across numerous OSes and 64-bit hardware platforms. This hybrid Single-Level Store approach allows for incremental exploration and adoption of a new programming paradigm.
Simple memory-mapped files is not enough. We need a design for how the address space and backing files are managed. The design should balance simplicity and efficiency in the management of the virtual (address space) and physical (real memory and disk space) resources.
Here are some principles I believe are important to include in the design. The runtime should be simple to use and compatible with UNIX programming and POSIX APIs. It should use resources (address space) that are not normally used in existing applications. It should appear to the program like a large shared persistent heap (SPH). Access to data in the SPH should use standard C pointer semantics. Setup to access to data in the SPH should be minimum. The design evolved to the concepts of regions, stores, segment and blocks, all with power of two sizes.
The region is simply the range of virtual addresses that the application wants the runtime to manage on its behalf. The region should be in a range of virtual addresses not normally used by the application. We want to ensure that the region does not interfere with the normal program usage of (local temporary) heap and dynamic libraries. On Linux, this means the area above the TASK_UNMAPPED_BASE and below the main stack. Leaving lots of room below the stack and above TASK_UNMAPPED_BASE still allows for the use of up to half the program's address space for SPH.
Next, we need to choose a segment size. The segment is the unit size for allocating backing files and memory mapping those files into the region. This should be large enough so that we don't do frequent kernel calls and small enough so that we don't waste file space.
A store is a directory that contains one or more files used to back SPH segments. A system can have multiple SPH stores by allocating the backing files in different directories. For now (also to keep things simple), a program can bind to only one region/store at a time.
Finally, a block is the unit of space allocation within an SPH region. It is normally between a page and a segment in size, but that is not a hard limit. The only hard limit is that the block fits with the remaining space at the time. If the block is allocated to a portion of the SPH region that does not currently have a backing file allocated, the SPH runtime will implicitly create the file(s) in the store directory associated with the region.
For overall simplicity, we use power of two sizes for blocks and segments. This allows a power of two buddy system to be used to track all aspects of SPH storage. The buddy system reduces fragmentation and simplifies recombining smaller blocks into larger blocks when they are freed.
We need some low-level utility functions to help manage the buddy lists. First, we need a simple heap manager to sub-allocate blocks for smaller control blocks and lists. The lists need to be ordered and will be searched frequently, so we use a simple binary tree. Algorithms for the heap manager and binary tree can be found in Donald E. Knuth's The Art of Computer Programming (see Resources).
Finally, we need a place to store and maintain this information. The anchor block is the first block in the region. The anchor block starts with a block header, which includes signature words (eye-catchers initialized to special values), type info, pointer to the start of the local free list (heap) and a set of pointers for the various binary trees that manage space in the SPH region. The remainder of the anchor block is initialized as free heap space. This internal heap is used to allocate additional nodes required for the binary trees and any other internal control blocks needed to manage the SPH region.
After an SPH region is initialized, we have mostly an empty region with one segment (backing file in the store directory) and one block (the anchor block) allocated from that segment. The various lists have been initialized to depict this state. For example, the region free and used lists contain entries for the unallocated (no backing files) and allocated (with backing files) portion of the region. An entry for the anchor block is added to the “used” list. The “uncommitted” list contains entries for the current unused portions of the first segment. And, the free list is empty. Now we are ready to allocate more blocks.
Listing 1. A List of Memory Blocks and Their Usage
------address------ --size-- 0, 0x400000000000, 1024KB Total in use 1024KB Total free 0KB 0, 0x400000100000, 1024KB 1, 0x400000200000, 2048KB 2, 0x400000400000, 4096KB 3, 0x400000800000, 8192KB Total Uncommitted 15360KB 0, 0x400001000000, 16384KB 1, 0x400002000000, 32768KB 2, 0x400004000000, 65536KB 3, 0x400008000000, 131072KB 4, 0x400010000000, 262144KB 5, 0x400020000000, 524288KB 6, 0x400040000000, 1048576KB 7, 0x400080000000, 2097152KB 8, 0x400100000000, 4194304KB 9, 0x400200000000, 8388608KB 10, 0x400400000000, 16777216KB 11, 0x400800000000, 33554432KB 12, 0x401000000000, 67108864KB 13, 0x402000000000, 134217728KB 14, 0x404000000000, 268435456KB 15, 0x408000000000, 536870912KB 16, 0x410000000000, 1073741824KB 17, 0x420000000000, 2147483648KB 18, 0x440000000000, 4294967296KB 19, 0x480000000000, 8589934592KB 20, 0x500000000000, 17179869184KB Total Region free 34359721984KB 0, 0x400000000000, 16384KB Total Region used 16384KB
We choose a hash table-based lock manager using the virtual address as the lock ID. The addresses of data within SPH are unique, and active locks can be found quickly in a hash table.
Storage for the lock tables has to be shared but not persistent, so we allocate IPC shared memory for that. This memory is initialized with a block header and associated heap, which is used to allocate storage for the lock hash table and lock lists. IPC semaphores also are allocated and used to block threads waiting on contended locks.
So far, we have blocks of shared persistent storage and an address-based lock manager. Blocks are useful for storing large uniform arrays but are awkward to use for complex structures, such as link lists and trees. The SPH runtime includes utility objects that allocate and manage blocks for finer-grained allocations and complex lists and trees.
Utility objects all start with a block header and provision for an internal heap (using the same heap manager as the anchor block). The same signature words are used, but each utility object has a unique type. The type values define a simple type system for runtime checks. The signature words and the fact that blocks are all powers of two sizes simplifies finding the block header for any utility object from any address within a block. This is the trick supporting the new-near allocation scheme discussed later.
The simplest utility object is SPHSimpleStack. The SimpleHeap is simply a block header and internal heap. A CompoundHeap is a heap manager that allocates SimpleHeaps. The block header links multiple CompoundHeap blocks together to form an expandable CompoundHeap. This “heap of heaps” structure, combined with the “new-near” mechanism is useful for maintaining locality of reference for large complex list and tree structures.
The CompoundHeap is a framework (think superclass) for the SPHStringBTree, SPHIndex and SPHContext utility objects. The SimpleHeap is the framework for the BTree nodes internal to SPHStringBTree and SPHIndex. An SPHStringBTree maps a string (name) to an address. An SPHIndex maps an arbitrary binary value to an address. An SPHContext defines a two-way mapping between one or more strings and an address. These utility objects are useful for creating naming structures and content-addressable memories.
I needed a test for Shared Persistent Heap runtime and thought storing and processing large images would be interesting. In a previous personal project, I implemented a fast Mandelbrot Fractal (see Resources) display based on breaking the image in quadrants and storing the image in a quadtree structure. The Mandelbrot set is interesting, because it is “self-similar” and shows detail and any zoom factor.
This program could pan and zoom over color renditions of the Mandelbrot set where most of the image was pre-computed and stored in the quadtree. The algorithm is incremental, so detail is computed and added to the quadtree as needed (for the current display).
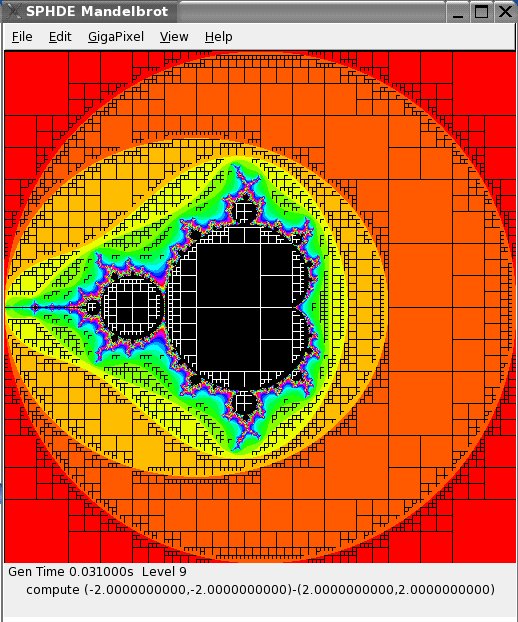
Figure 1. Mandelbrot Set with Quadtrees Outlined

Figure 2. Zoom 8192X with Quadtrees Outlined
At the time, I had no good way to store the resulting quadtree for later use. I did write recursive streaming code to write/read a flattened representation of the quadtree to/from a file. But, as the quadtree image accumulated detail, it slowed down noticeably. Also, I ended up with multiple files with pre-computed details of different areas of the Mandelbrot set, but had no good way to merge them in a single high-resolution image. At this point, the Mandelbrot Project was set aside.
Later, when I was working on the SPHDE Project and was trying to think of a good demo, I remembered the quadtree Mandelbrot Project. The hard part was converting the original Mandelbrot program from Borland OWL to Linux and GTK2. The actual conversion to use SPHDE was much easier.
First, I added SPHJoinRegion and SPHCleanUp calls to the entry and exit of main. Then, I added code to handle first-time setup. This involved allocating a control block to anchor the quadtree and create an expanding SPHCompoundHeap to manage storage of the quadtree. Subsequent use of the program needs to obtain only the address of this control. This pointer can be stored and retrieved from a free slot in the anchor block header.
The next step was to change the quadtree algorithm to use SPHDE storage. This is only slightly complicated by a desire to maintain good locality of reference within the quadtree itself. The SPHCompoundHeap allocates SPHSimpleHeaps from which quadtree nodes are allocated. Allocating adjacent quadtree nodes from the same SPHSimpleHeap ensures physically locality in memory and the backing file. This minimizes the number of pages touched to display the whole Mandelbrot set (the topmost part of the quadtree) or zoom to any part of the set.
The simple call:
node = (TQuadTree*) SPHSimpleHeapNearAlloc (near, sizeof (TQuadTree));
always will attempt to allocate from the SimpleHeap containing the nearest existing quadtree node. If this allocation fails, we either need to find another SimpleHeap with free space or call SPHCompoundHeapAlloc to allocate another SimpleHeap:
if (!node)
{
temp1 = SASCompoundHeapAlloc (QuadBlockPtr->compoundHeap);
if (temp1)
{
node = (TQuadTree *)
SASSimpleHeapAlloc (temp1, sizeof (TQuadTree));
lastAlloc = temp1;
}
}
A simple cache of recently allocated SimpleHeaps and SimpleHeaps where nodes were recently freed served to keep the quadtree relatively dense within the SPHCompoundHeap managed storage. All this logic is contained in 100 lines of code.
Finally, we need to ensure that multiple instances of the program can share and update the quadtree safely. This requires adding SPHLock/SPHUnlock calls around any code with the potential to modify a quadtree node. There are only four such locations in the current algorithm. The utility objects (SimpleHeap, CompondHeap and so on) use appropriate locks internally to ensure consistent behavior in a shared environment.
The result is a program that can compute and store a gigapixel or larger image. Generating a gigapixel (32768x32768) Mandelbrot image takes about five minutes (Apple G5 dual-2.3GHz PowerPC). Once the gigapixel quadtree is generated, exiting and restarting is nearly instantaneous (24 milliseconds to display a 512x512 pixel image). Panning and zooming around the pre-computed quadtree is also fast (12–20 milliseconds). Zooming to a depth beyond the current pre-computed set will slow down (200–500 milliseconds) due to the heavy computation required. Once an area is computed and stored, subsequent displays are fast (12–20 milliseconds) again.
The SPHDE runtime and Mandelbrot demo program run on both 32-bit and 64-bit Linux, including the PowerPC, i386 and x86_64 platforms. 32-bit systems can support a 1–2GB region, which is large enough to store a gigapixel Mandelbrot quadtree (~313MB). Larger (terapixel) images will require the large regions allowed by 64-bit systems. With recent Linux kernels, PowerPC64 can support regions in the 8TB range. The X86_64 platform supports a 128TB address space and a 64TB region. This is more than enough for some interesting projects.
Resources
Enterprise Java Performance, Chapter 14, Steve L. Halter and Steven J. Munroe, Prentice Hall 2001, ISBN 0-13-017296-0.
The Art of Computer Programming, Volume 1, Fundamental Algorithms, 3rd ed., Donald E. Knuth, Addison Wesley 1997, ISBN 0-201-89683-4.
SASOS: liinwww.ira.uka.de/csbib/Os/sasos.html
Mandelbrot Set: en.wikipedia.org/wiki/Mandelbrot_Set
Quadtree: en.wikipedia.org/wiki/Quadtree
Steve Munroe is currently an architect covering toolchain (GCC, GLIBC, binutils, GDB and related performance collection tools) issues in IBM's Linux Technology Center. Steve is an active contributor to open-source software, porting the GNU C library (GLIBC) to 64-bit PowerPC. Steve is an expert in single-level storage, large address space architectures and Java, with an emphasis on object persistence and business applications. He coauthored (with Steven Halter) the book Enterprise Java Performance. He also was a performance architect for IBM's San Francisco Project and authored a Java workload from which he helped SPEC (Standard Performance Evaluation Corporation) create SPECjbb2000, an industry-standard workload for Java server performance.
