
MySQL 5 Stored Procedures: Relic or Revolution?
Stored procedures (or stored routines, to use the official MySQL terminology) are programs that are both stored and executed within the database server. Stored procedures have been features in closed-source relational databases, such as Oracle, since the early 1990s. However, MySQL added stored procedure support only in the recent 5.0 release and, consequently, applications built on the LAMP stack don't generally incorporate stored procedures. So, this is an opportune time to consider whether stored procedures should be incorporated into your MySQL applications.
Database stored programs first came to prominence in the late 1980s and early 1990s, during the client-server revolution. In the client-server applications of that time, stored programs had some obvious advantages:
Client-server applications typically had to balance processing load carefully between the client PC and the (relatively) more powerful server machine. Using stored programs was one way to reduce the load on the client, which might otherwise be overloaded.
Network bandwidth was often a serious constraint on client-server applications; execution of multiple server-side operations in a single stored program could reduce network traffic.
Maintaining correct versions of client software in a client-server environment was often problematic. Centralizing at least some of the processing on the server allowed a greater measure of control over core logic.
Stored programs offered clear security advantages because, in those days, application users typically connected directly to the database, rather than through a middle tier. As I discuss later in this article, stored procedures allow you to restrict the database account only to well-defined procedure calls, rather than allowing the account to execute any and all SQL statements.
With the emergence of three-tier architectures and Web applications, some of the incentives to use stored programs from within applications disappeared. Application clients are now often browser-based, security is predominantly handled by a middle tier, and the middle tier possesses the ability to encapsulate business logic. Most of the functions for which stored programs were used in client-server applications now can be implemented in middle-tier code (PHP, Java, C# and so on).
Nevertheless, many of the traditional advantages of stored procedures remain, so let's consider these advantages, and some disadvantages, in more depth.
Stored procedures are subject to most of the security restrictions that apply to other database objects: tables, indexes, views and so forth. Specific permissions are required before a user can create a stored program, and, similarly, specific permissions are needed in order to execute a program.
What sets the stored program security model apart from that of other database objects—and from other programming languages—is that stored programs may execute with the permissions of the user who created the stored procedure, rather than those of the user who is executing the stored procedure. This model allows users to perform actions via a stored procedure that they would not be authorized to perform using normal SQL.
This facility, sometimes called definer rights security, allows us to tighten our database security, because we can ensure that a user gains access to tables only via stored program code that restricts the types of operations that can be performed on those tables and that can implement various business and data integrity rules. For instance, by establishing a stored program as the only mechanism available for certain table inserts or updates, we can ensure that all of these operations are logged, and we can prevent any invalid data entry from making its way into the table.
In the event that this application account is compromised (for instance, if the password is cracked), attackers still will be able to execute only our stored programs, as opposed to being able to run any ad hoc SQL. Although such a situation constitutes a severe security breach, at least we are assured that attackers will be subject to the same checks and logging as normal application users. They also will be denied the opportunity to retrieve information about the underlying database schema (because the ability to run standard SQL will be granted to the procedure, not the user), which will hinder attempts to perform further malicious activities.
Another security advantage inherent in stored programs is their resistance to SQL injection attacks. An SQL injection attack can occur when a malicious user manages to “inject” SQL code into the SQL code being constructed by the application. Stored programs do not offer the only protection against SQL injection attacks, but applications that rely exclusively on stored programs to interact with the database are largely resistant to this type of attack (provided that those stored programs do not themselves build dynamic SQL strings without fully validating their inputs).
It is generally a good practice to separate your data access code from your business logic and presentation logic. Data access routines often are used by multiple program modules and are likely to be maintained by a separate group of developers. A very common scenario requires changes to the underlying data structures while minimizing the impact on higher-level logic. Data abstraction makes this much easier to accomplish.
The use of stored programs provides a convenient way of implementing a data access layer. By creating a set of stored programs that implement all of the data access routines required by the application, we are effectively building an API for the application to use for all database interactions.
Stored programs can improve application performance radically by reducing network traffic in certain situations.
It's commonplace for an application to accept input from an end user, read some data in the database, decide what statement to execute next, retrieve a result, make a decision, execute some SQL and so on. If the application code is written entirely outside the database, each of these steps would require a network round trip between the database and the application. The time taken to perform these network trips easily can dominate overall user response time.
Consider a typical interaction between a bank customer and an ATM machine. The user requests a transfer of funds between two accounts. The application must retrieve the balance of each account from the database, check withdrawal limits and possibly other policy information, issue the relevant UPDATE statements, and finally issue a commit, all before advising the customer that the transaction has succeeded. Even for this relatively simple interaction, at least six separate database queries must be issued, each with its own network round trip between the application server and the database. Figure 1 shows the sequences of interactions that would be required without a stored program.
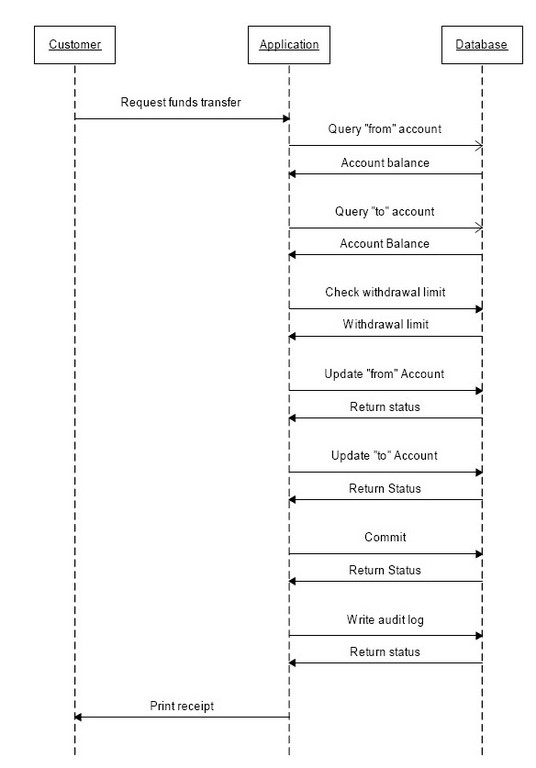
Figure 1. Network Round Trips without Stored Procedure
On the other hand, if a stored program is used to implement the fund transfer logic, only a single database interaction is required. The stored program takes responsibility for checking balances, withdrawal limits and so on. Figure 2 shows the reduction in network round trips that occurs as a result.
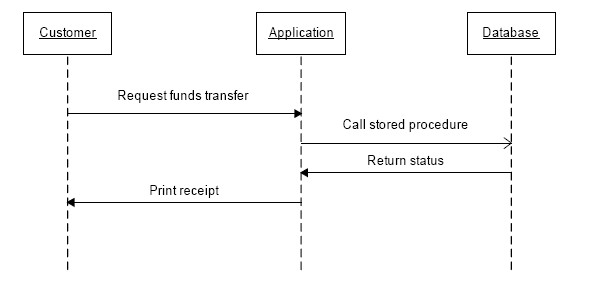
Figure 2. Network Round Trips with Stored Procedure
Network round trips also can become significant when an application is required to perform some kind of aggregate processing on very large record sets in the database. For instance, if the application needs to retrieve millions of rows in order to calculate some sort of business metric that cannot be computed easily using native SQL, such as average time to complete an order, a very large number of round trips can result. In such a case, the network delay again may become the dominant factor in application response time. Performing the calculations in a stored program will reduce network overhead, which might reduce overall response time, but you need to be sure to take into account the differences in raw computation speed, which I discuss later in this article.
Although it is commonplace for a MySQL database to be at the service of a single application, it is not at all uncommon for multiple applications to share a single database. These applications might run on different machines and be written in different languages; it may be hard, or impossible, for these applications to share code. Implementing common code in stored programs may allow these applications to share critical common routines.
For instance, in a banking application, transfer of funds transactions might originate from multiple sources, including a bank teller's console, an Internet browser, an ATM or a phone banking application. Each of these applications could conceivably have its own database access code written in largely incompatible languages, and without stored programs we might have to replicate the transaction logic, including logging, deadlock handling and optimistic locking strategies, in multiple places and in multiple languages. In this scenario, consolidating the logic in a database stored procedure can make a lot of sense.
It would be terribly unfair of us to expect the first release of the MySQL stored program language to be blisteringly fast. After all, languages such as Perl and PHP have been the subject of tweaking and optimization for about a decade, while the latest generation of programming languages—.NET and Java—has been the subject of a shorter, but more intensive optimization process by some of the biggest software companies in the world. So, right from the start, we might expect that the MySQL stored program language would lag in comparison with the other languages commonly used in the MySQL world.
Still, it's important to get a sense of the raw performance of the language. First, let's see how quickly the stored program language can crunch numbers. The first example compares a stored procedure calculating prime numbers against an identical algorithm implemented in alternative languages.
In this computationally intensive trial, MySQL performed poorly compared with other languages—five times slower than PHP or Perl, and dozens of times slower than Java, .NET or C (Figure 3).
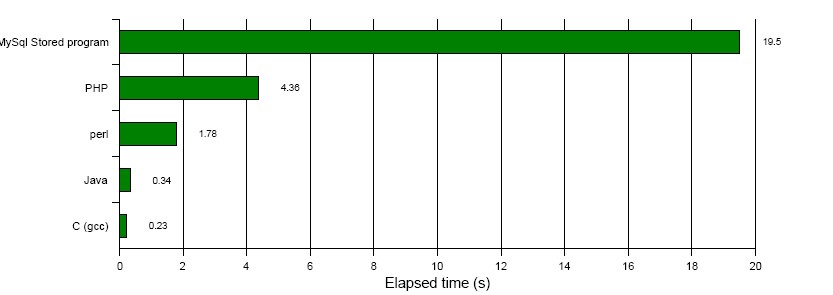
Figure 3. Stored procedures are a poor choice for number crunching.
Most of the time, stored programs are dominated by database access time, where stored programs have a natural performance advantage over other programming languages because of their lower network overhead. However, if you are writing a number-crunching routine, and you have a choice between implementing it in the stored program language or in another language, such as PHP or Java, you may wisely decide against using the stored program solution.
If the previous example left you feeling less than enthusiastic about stored program performance, this next example should cheer you right up. Although stored programs aren't particularly zippy when it comes to number crunching, it is definitely true that you don't normally write stored programs simply to perform math; stored programs almost always process data from the database. In these circumstances, the difference between stored program and PHP or Java performance is usually minimal, unless network overhead is a big factor. When a program is required to process large numbers of rows from the database, a stored program can substantially outperform programs written in client languages, because it does not have to wait for rows to be transferred across the network—the stored program runs inside the database. Figure 4 shows how a stored procedure that aggregates millions of rows can perform well even when called from a remote host across the network, while a Java program with identical logic suffers from severe network-driven response time degradation.
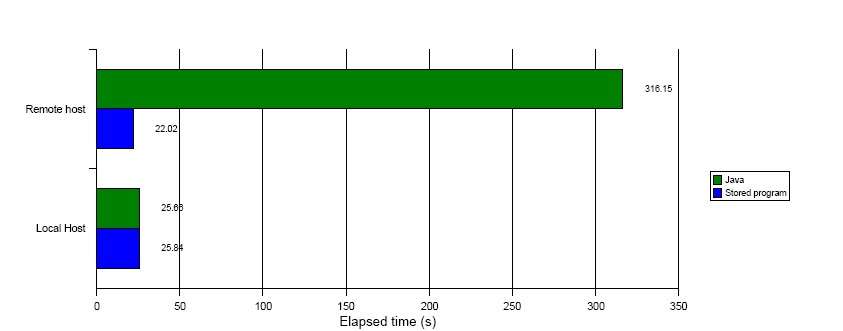
Figure 4. Stored procedures outperform when the network is a factor.
Although it is generally useful to encapsulate data access logic inside stored programs, it is usually inadvisable to “fragment” business and application logic by implementing some of it in stored programs and the rest of it in the middle tier or the application client.
Debugging application errors that involve interactions between stored program code and other application code may be many times more difficult than debugging code that is completely encapsulated in the application layer. For instance, there is currently no debugger that can trace program flow from the application code into the MySQL stored program code.
Also, if your application relies on stored procedures, that's an additional skill that you or your team will have to acquire and maintain.
It's becoming increasingly common for an Object-Relational Mapping (ORM) framework to mediate interactions between the application and the database. ORM is very common in Java (Hibernate and EJB), almost unavoidable in Ruby on Rails (ActiveRecord) and far less common in PHP (though there are an increasing number of PHP ORM packages available). ORM systems generate SQL to maintain a mapping between program objects and database tables. Although most ORM systems allow you to overwrite the ORM SQL with your own code, such as a stored procedure call, doing so negates some of the advantages of the ORM system. In short, stored procedures become harder to use and a lot less attractive when used in combination with ORM.
Although all relational databases implement a common set of SQL syntax, each RDBMS offers proprietary extensions to this standard SQL, and MySQL is no exception. If you are attempting to write an application that is designed to be independent of the underlying database, you probably will want to avoid these extensions in your application. However, sometimes you'll need to use specific syntax to get the most out of the server. For instance, in MySQL, you often will want to employ MySQL hints, execute non-ANSI statements, such as LOCK TABLES, or use the REPLACE statement.
Using stored programs can help you avoid RDBMS-dependent code in your application layer while allowing you to continue to take advantage of RDBMS-specific optimizations. In theory, stored program calls against different databases can be made to look and behave identically from the application's perspective. You can encapsulate all the database-dependent code inside the stored procedures. Of course, the underlying stored program code will need to be rewritten for each RDBMS, but at least your application code will be relatively portable.
However, there are differences between the various database servers in how they handle stored procedure calls, especially if those calls return result sets. MySQL, SQL Server and DB2 stored procedures behave very similarly from the application's point of view. However, Oracle and Postgres calls can look and act differently, especially if your stored procedure call returns one or more result sets.
So, although using stored procedures can improve the portability of your application while still allowing you to exploit vendor-specific syntax, they don't make your application totally portable.
MySQL stored programs can be used for a variety of tasks in addition to traditional application logic:
Triggers are stored programs that fire when data modification language (DML) statements execute. Triggers can automate denormalization and enforce business rules without requiring application code changes and will take effect for all applications that access the database, including ad hoc SQL.
The MySQL event scheduler introduced in the 5.1 release allows stored procedure code to be executed at regular intervals. This is handy for running regular application maintenance tasks, such as purging and archiving.
The MySQL stored program language can be used to create functions that can be called from standard SQL. This allows you to encapsulate complex application calculations in a function and then use that function within SQL calls. This can centralize logic, improve maintainability and, if used carefully, improve performance.
The bottom line is that MySQL stored procedures give you more options for implementing your application and, therefore, are undeniably a “good thing”. Judicious use of stored procedures can result in a more secure, higher performing and maintainable application. However, the degree to which an application might benefit from stored procedures is greatly dependent on the nature of that application. I hope this article helps you make a decision that works for your situation.
Guy Harrison is chief architect for Database Solutions at Quest Software (www.quest.com). This article uses some material from his book MySQL Stored Procedure Programming (O'Reilly 2006; with Steven Feuerstein). Guy can be contacted at guy.harrison@quest.com.
