
Optimizing Oracle 10g on Linux: Non-RAC ASM vs. LVM
It's been over a year since my first and enthusiastic automatic storage management (ASM) article, titled "Optimizing Oracle 10g on Linux Using Automated Storage Management", was published. It still is available here, here and here. Since then, quite a lot has changed in terms of the software technologies now available:
Red Hat released Advanced Server 4.0 built on the 2.6 kernel
Along with AS 4.0, Red Hat released a greatly improved LVM with a GUI
Red Hat released the Global File System, which now is a part of Fedora
Oracle released version 10.2.0.1 of the database (10g release 2)
Oracle released version 2.0 of the ASM kernel driver and libraries
Oracle released version 2.0 of the Oracle Cluster File System
As you can see, the software technology landscape has changed so extensively that it has reopened the entire ASM debate. In my first ASM paper, I simply assumed people either would be utilizing ASM or not--without considering RAC usage ramifications. During this past year at shows, conferences and on-site visits, a number have told me that although ASM makes obvious sense for RAC environments, they also want to know if ASM is a viable alternative for non-RAC environments. Specifically, does ASM perform as well as Linux filesystems using a logical volume manager (LVM)?
Of course, that's a challenge far too enticing to pass up, especially when tools such as Quest's Benchmark Factory are available that make these tests trivial. So on to the races.
Looking back at the technology change listing above, what we want to benchmark is the new LVM vs. ASM 2.0 on Red Hat Advanced Server 4.0's 2.6 kernel running Oracle 10g Release 2. In other words, we want to test all of the latest and greatest software technology available for non-RAC scenarios. The goal is simply to benchmark their fundamental performance characteristics against one another and, where possible, declare a winner. For that purpose, we need to simulate two radically different kinds of real-world workloads to cover differing needs. Thus, the following industry-standard benchmark tests are being used:
The TPC-C benchmark measures on-line transaction processing (OLTP) workloads. It combines read-only and update intensive transactions, simulating the activities found in complex OLTP enterprise environments.
The TPC-D benchmark measures a broad range of decision support applications requiring complex, long-running queries against large and complex databases.
Both tests simulate 100 users against 1GB databases. Although these test parameters are not too large, they nonetheless are the maximum realistic values that our limited test hardware can accommodate. But it's expected that results from such tests should be sufficient for extrapolating to larger environments.
Setting up an industry-standard database benchmark, such as the TPC-C and TPC-D, using Quest's Benchmark Factory is a snap and can be done in five easy steps. First, after opening the application, press the New toolbar icon to launch the New Project wizard. From there, specify that you want to create a Standard Benchmark Workload, as shown in Figure 1.
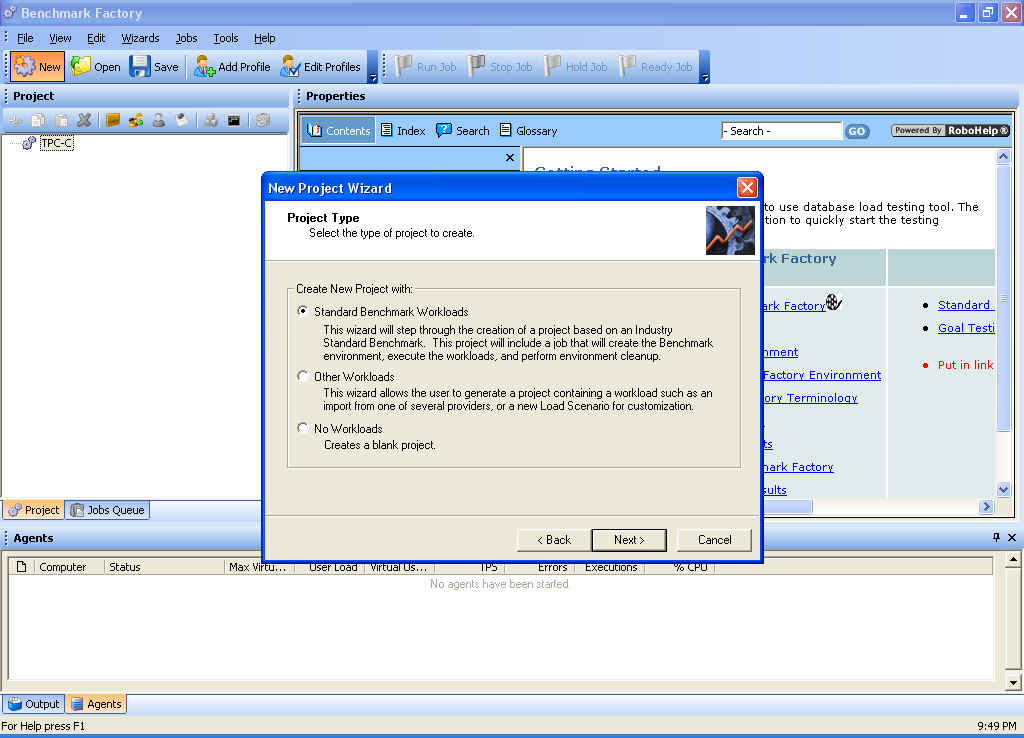
Figure 1. Creating a Standard Benchmark Workload
Second, choose which industry standard benchmark you want to perform from the list of available tests, as shown in Figure 2.
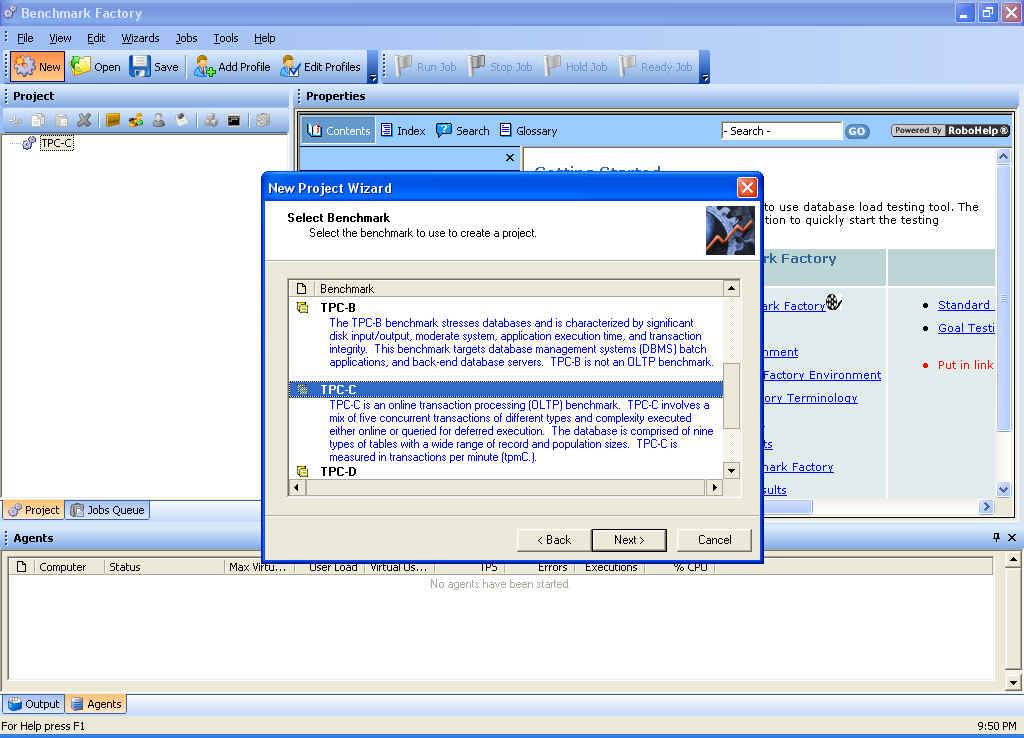
Figure 2. Choosing the Benchmark
Third, choose the approximate database size to create for performing the benchmark, as shown in Figure 3. Remember, Benchmark Factory has to create and populate it.
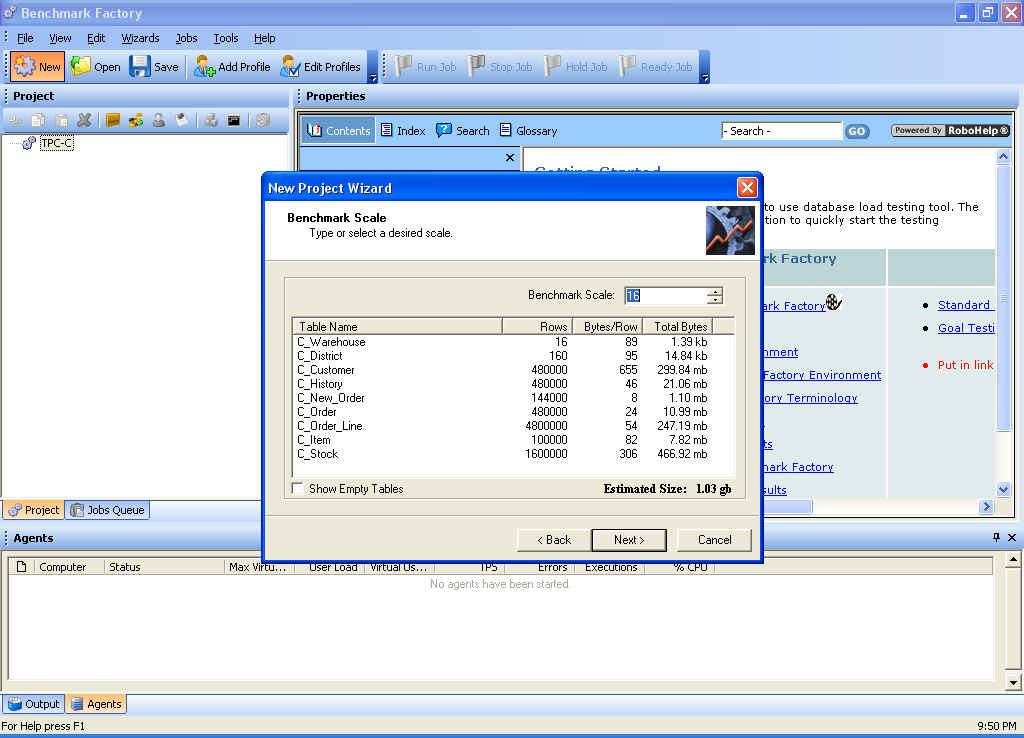
Figure 3. Choosing the Database Size
Fourth, select the number of concurrent users you want to simulate for performing the benchmark, as shown in Figure 4. As a side note, you can run this from one or more Windows computers.
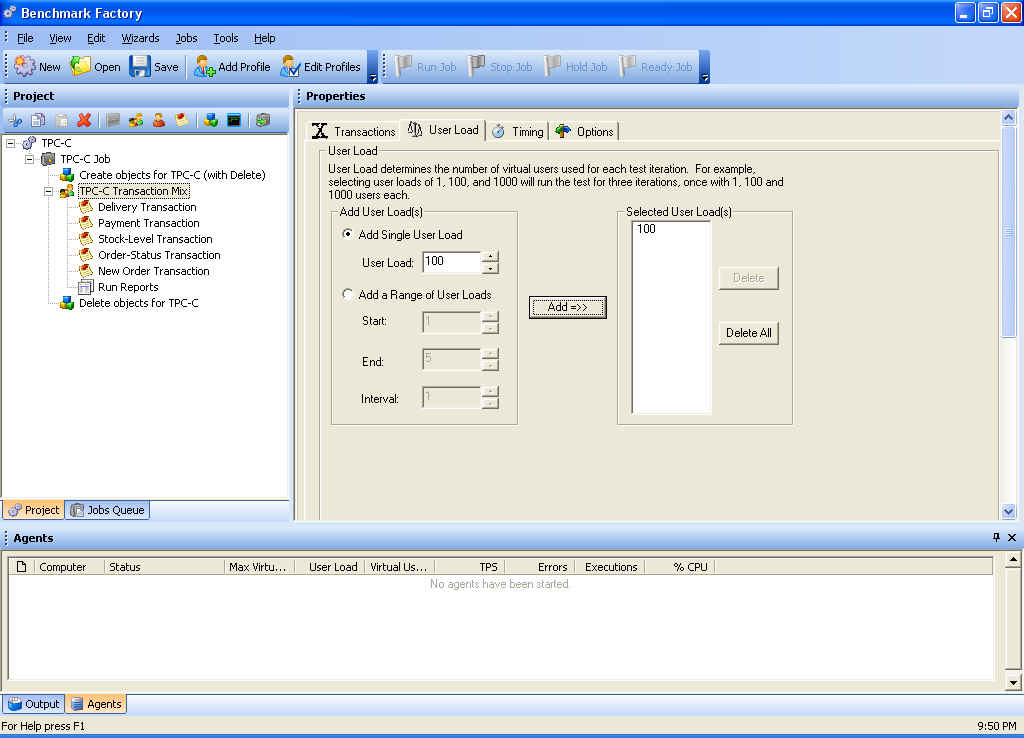
Figure 4. Selecting Concurrent Users
Fifth, run the test and record the results. The total time it generally takes to configure a standard benchmark is roughly 30 seconds.
In order for the benchmark test results to provide a fair, apples to apples comparison, both the LVM and ASM disk layouts must be similar enough to draw meaningful and reliable conclusions. That means neither setup should get preferential treatment in the allocation of devices. To that end, Figure 5 shows how the two environments were allocated across four identical IDE disks; you can tell they are IDE disks by the /hdb1 through /hde2 naming convention. These were 7,200 RPM SATA IDE disks with 2MB of cache each. Notice also how two inner and two outer disk partitions were allocated to each solution. The idea was to eliminate any unintentional speed advantages due to quicker access times for inner disk tracks. Finally, no operating system, swap or database binary files are on these disks; they were used solely for database data.
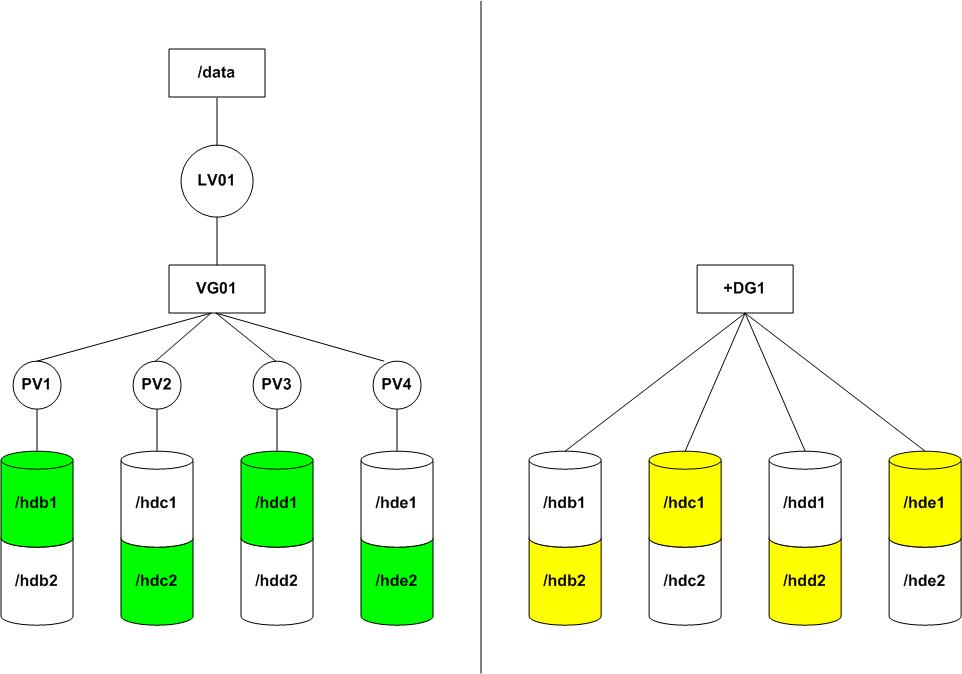
Figure 5. Allocating Devices
Although SCSI is obviously the preferable choice, the popularity of SATA IDE for low-cost RAID arrays is rising. The results obtained should apply equally well to faster and more reliable disk technologies such as SCSI, as well as highly popular RAID array appliances, such as NAS and SAN. The chief goal here was to implement Oracle's SAME (stripe and mirror everything) approach. Even though there are only four disks, we nonetheless should be able to compare these two methods' fundamental striping capabilities. And, minus all the other bells-and-whistles distractions, that's essentially the heart of the question people have been asking: do the ASM striping algorithms match up well against those of the more mature LVM?
Remember as we look at these results that we're not worrying about which environment is easier to set up and maintain, because as the prior paper clearly pointed out, ASM has numerous advantages in those areas. Our goal here is simply to see how they perform in head-to-head speed tests. So the results here focus on only that aspect--speed.
Let's look first at the TPC-C results. Remember, we simulated 100 concurrent users accessing a 1GB database. The results are shown in Figure 6.
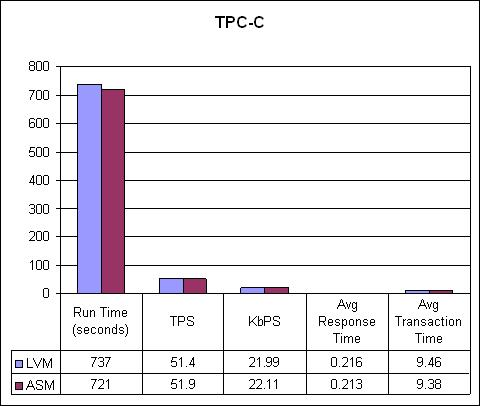
Figure 6. The TPC-C Results
Basically, the TPC-C results were too close to award a winner. I suspect that a key reason for the lack of any major difference is the Oracle data, index, temporary and rollback segments did not have to grow and shrink by any measurable amount in this type of load test scenario. This is because OLTP transactions tend to be short and bursty in nature. Thus, we are measuring primarily read-only access across four disk stripes. Therefore, we have to call the TPC-C benchmark test results a draw, with neither ASM nor LVM showing any real performance advantage.
Note: Although this tie was unexpected, it clearly shows why you need to consider more than one type of benchmark test when comparing such radically different technologies. Benchmark Factory offers additional database benchmarking tests, including TPC-B, TPC-D, AS3AP and Scalable Hardware Benchmark. Make sure that you choose the tests that best reflect the database environment you will be building and maintaining.
Now let's look at the TPC-D. Again, we simulated 100 concurrent users accessing a 1GB database. The results are shown in Figure 7.
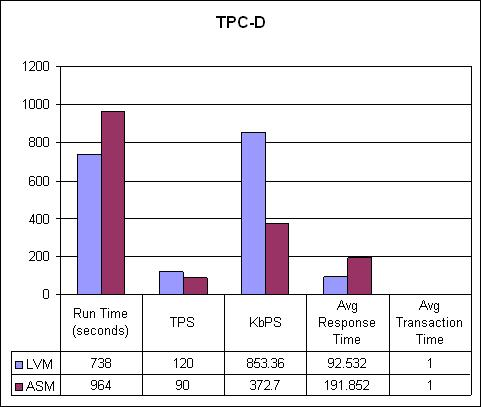
Figure 7. The TPC-D Results
Here we have a clear-cut winner. The LVM ran 30% faster, achieved a 25% higher transaction per second rate, scored 56% faster on kilobytes per second and had a 108% better average response time. I suspect that the real differentiator here was the temporary segment allocation necessary for the large GROUP BY and ORDER BY operations.
I was not entirely happy, however, with simply running the industry-standard benchmarks and speculating as to why the results ended up as they did. I wanted a little more clarity regarding objects' segment creation and allocation--and the corresponding tablespace growth issues. My belief was the LVM somehow handles space allocation due to object growth more efficiently than ASM does. Of course, this seems totally contrary to what one would expect, as ASM touts the advantages of RAW without the headaches. So how could the ext3 filesystem on top of the LVM be faster? To this end, I devised a simple, brute force benchmark to test this premise. I created a simple table with two indexes whose data format would yield predictable growth with increasing row counts. Thus, I could test the object space creation and allocation for both tables and indexes with one simple script. The script is provided below.
set verify off
drop table junk;
create table junk (
c1 number not null,
c2 number not null,
c3 number not null,
c4 number not null,
c5 date not null,
c6 char(100) not null,
c7 varchar2(1000) not null,
constraint junk_pk primary key (c1, c2),
constraint junk_uk unique (c3, c4)
);
variable t1 varchar2(12)
variable t2 varchar2(12)
variable t3 number
begin
:t1 := to_char(sysdate,'DDD:HH24:MI:SS');
end;
/
begin
for i in 1 .. &1 loop
insert into junk values (i,i,i,i,sysdate,
'This is a test of the emergency broadcast system',
'In the case of an actual emergency, you would be
told where to tune');
if (mod(i,100) = 0) then
commit;
end if;
end loop;
end;
/
begin
:t2 := to_char(sysdate,'DDD:HH24:MI:SS');
:t3 := to_number(to_date(:t2,'DDD:HH24:MI:SS')-
to_date(:t1,'DDD:HH24:MI:SS'))*60*60*24;
end;
/
print t1
print t2
print t3
col segment_name format a20
col tablespace_name format a20
col megs format 999,999,999
select segment_name, tablespace_name, ceil(bytes/(1024*1024))
MEGS from user_segments where segment_name like 'JUNK%';
exit
The results of calling this script for row counts from 10,000 to 100,000,000 for both LVM and ASM are shown in Figure 8.
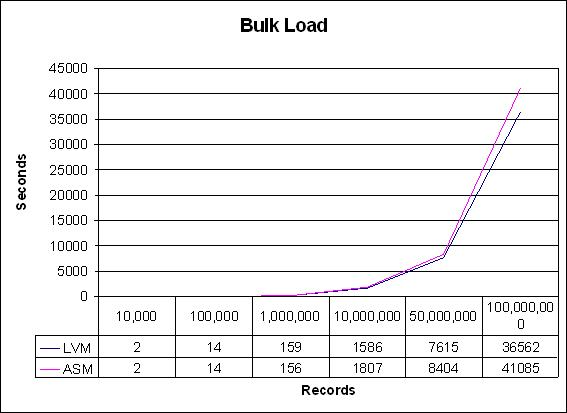
Figure 8. Script-Generated Results
The results from this additional experiment were quite simple and conclusive. Although both approaches used exactly the same amount of space, the LVM run times consistently beat the ASM run times by anywhere from 10 to 14%. As you can see by the graph's lines, the trend seems clear: LVM is slightly more efficient at bulk data loads than is ASM.
So, what does all of this mean? For people doing RAC, ASM is a viable and credible approach for disk space management, with numerous administrative and maintenance benefits to its credit. But for those simply doing non-RAC database deployments, ASM is not yet as scalable as the Linux ext3 filesystem using an LVM. And while all these benchmarks were done using the standard LVM included with Red Hat and other popular Linux distributions, it's quite possible that an enterprise targeted LVM, such as those available from either IBM or Veritas, would best even these results. Therefore, for people not doing RAC who care more about performance than administrative ease, for now you should stick with the Linux filesystems and an LVM.
Bert Scalzo is a product architect for Quest Software and a member of the TOAD development team. He designed many of the features in the TOAD DBA module. He has worked as an Oracle DBA with versions 4 through 10g and has worked for both Oracle Education and Consulting. Mr. Scalzo holds several Oracle Masters, as well as a BS, MS and PhD in Computer Science, an MBA and several insurance industry designations. He can be reached at bert.scalzo@quest.com or bert.scalzo@comcast.net.
