
Heterogeneous Processing: a Strategy for Augmenting Moore's Law
Better application performance: everyone wants it, and in the high-performance computing (HPC) community, we've come to expect it. Maybe we've even gotten a little spoiled. After all, we've enjoyed basically continuous performance improvement for four decades, thanks to Moore's Law.
Now in its 40th year, that principle (which predicts a doubling of transistor density every 18 months) is still going strong. But unfortunately, ever-increasing transistor density no longer delivers comparable improvements in application performance. The reasons for this are well known. Adding transistors also adds wire delays and speed-to-memory issues. More aggressive single-core designs also inevitably lead to greater complexity and heat. Finally, scalar processors themselves have a fundamental limitation: a design based on serial execution, which makes it extremely difficult to extract more instruction-level parallelism (ILP) from application codes.
These issues are no longer the sole concern of a small, high-end user base, if they ever were. It is becoming more apparent that major performance improvements could have a profound effect on virtually every scientific field. The President's Information Technology Advisory Committee, which challenged HPC researchers to achieve a sustained petaflop on real applications by 2010, noted that trans-petaflop systems will be crucial for better weather and climate forecasting, manufacturing, pharmaceutical development and other strategic applications. Industry experts at conferences such as Petaflops II are demanding improvements for a laundry list of applications, including crash testing, advanced aircraft and spacecraft design, economic modeling, and combating pandemics and bio-terrorism.
The HPC community is responding by developing new strategies to augment Moore's Law and exploring innovative HPC architectures that can work around the limitations of conventional systems. These strategies include:
Multicore systems that use two or more cores on a die to continue providing steady performance gains.
Specialized processors that deliver enhanced performance in areas where conventional commodity processors fare poorly.
Heterogeneous computing architectures, in which conventional and specialized processors work cooperatively.
Each of these strategies can potentially deliver substantial performance improvements. At Cray, we are exploring all three. But in the long term, we believe heterogeneous computing holds tremendous potential for accelerating applications beyond what one would expect from Moore's Law, while overcoming many of the barriers that can limit conventional architectures. As a participant in the DARPA High Productivity Computing Systems Program, we expect heterogeneous processing to become crucially important over the next several years.
Placing multiple cores on a die is the fastest way to deliver continuous performance gains in line with Moore's Law. A well-known example of a multiple-core processor is the Dual-core AMD Opteron.
Cray and other HPC manufacturers have already embraced this model. Today, Cray is delivering dual-core systems, with expectations to leverage more cores in the future. This strategy offers immediate doubling of computing density, while reducing per-processor power consumption and heat.
For many applications (especially those requiring heavy floating-point operations), multicore processing will provide performance gains for the foreseeable future, and the model will likely serve as the primary vehicle through which Moore's Law is upheld. However, for some applications (notably, those that depend on heavy bit manipulation, sorting and signal processing, such as database searching, audio/video/image processing and encryption/decryption), Moore's Law may not be enough. Major advances in these applications can be realized only with processing speeds orders of magnitude beyond what is available today (or likely to be available anytime soon) through conventional processors. So HPC researchers are exploring alternative models.
In recent years, architectures based on clusters of commodity processors have overtaken high-end, specialized systems in the HPC community, due to their low cost and solid performance for many applications. But, as some users begin to bump up against the inherent limitations of scalar processing, we are beginning to see a reversal in that trend. Examples of this resurgence include:
Vector processors: vector processors increase computational performance by efficiently pipelining identical calculations on large streams of data, eliminating the instruction issue rate limitations of conventional processors.
Multithreaded processors: HPC memory speeds have been increasing at only a fraction of the rate of processor speeds, leading to performance bottlenecks as serial processors wait for memory. Systems incorporating multithreaded processors (such as IBM's Simultaneous Multi-Threading processor and Intel's Hyper-Threading technology) address this issue by modifying the processor architecture to execute multiple threads simultaneously, while sharing memory and bandwidth resources. Cray's multithreaded architecture takes this a step further by allowing dozens of active threads simultaneously, fully utilizing memory bandwidth.
Digital Signal Processors (DSPs): DSPs are optimized for processing a continuous signal, making them extremely useful for audio, video and radar applications. Their low power consumption also makes these processors ideal for use in plasma TVs, cell phones and other embedded devices.
Specialized coprocessors: coprocessors such as the floating-point accelerator developed by Clearspeed Technology and the n-body accelerator GRAPE, use unique array processor architectures to provide a large number of floating-point components (multiply/add units) per chip. They can deliver noticeable improvements on mathematically intense functions, such as multiplying or inverting matrices or solving n-body problems.
Processors such as these can deliver substantially better performance than general-purpose processors on some operations. Vector and multithreaded processors are also latency tolerant and can continue executing instructions even while allowing large numbers of memory references to be underway simultaneously. These enhancements can allow for significant application performance improvement, while reducing inter-cache communication burdens and real estate on the chip required by conventional caching strategies.
However, as specialized processors have traditionally been deployed, they have had serious limitations. First, although they can provide excellent acceleration for some operations, they often run scalar code much more slowly than commodity processors—and most software used in the real world employs at least some scalar code. To address this issue, these processors traditionally have been incorporated into more conventional systems via the PCI bus—essentially as a peripheral. This inadequate communications bandwidth severely limits the acceleration that can be achieved. (Communicating a result back to the conventional system may actually take more time than the calculation itself.) There are also hard economic realities of processor fabrication. Unless the processor has a well-developed market niche that will support commodity production (such as the applicability of DSPs to consumer electronics), few manufacturers are willing to take on the huge costs of bringing new designs to market.
These issues are leading Cray and others to explore an alternative model.
Heterogeneous computing is the strategy of deploying multiple types of processing elements within a single workflow, and allowing each to perform the tasks to which it is best suited. This model can employ the specialized processors described above (and others) to accelerate some operations up to 100 times faster than what scalar processors can achieve, while expanding the applicability of conventional microprocessor architectures. Because many HPC applications include both code that could benefit from acceleration and code that is better suited for conventional processing, no one type of processor is best for all computations. Heterogeneous processing allows for the right processor type for each operation within a given application.
Traditionally, there have been two primary barriers to widespread adoption of heterogeneous architectures: the programming complexity required to distribute workloads across multiple processors and the additional effort required if those processors are of different types. These issues can be substantial, and any potential advantages of a heterogeneous approach must be weighed against the cost and resources required to overcome them. But today, the rise of multicore systems is already creating a technology discontinuity that will affect the way programmers view HPC software, and open the door to new programming strategies and environments. As software designers become more comfortable programming for multiple processors, they are likely to be more willing to consider other types of architectures, including heterogeneous systems. And several new heterogeneous systems are now emerging.
The Cray X1E supercomputer, for example, incorporates both vector processing and scalar processing, and a specialized compiler that automatically distributes the workload between processors. In the new Cell processor architecture (designed by IBM, Sony and Toshiba to accelerate gaming applications on the new Playstation 3), a conventional processor offloads computationally intensive tasks to synergistic processing elements with direct access to memory. But one of the most exciting areas of heterogeneous computing emerging today employs field programmable gate arrays, or FPGAs.
FPGAs are hardware-reconfigurable devices that can be redesigned repeatedly by programmers to solve specific types of problems more efficiently. FPGAs have been used as programmable logic devices for more than a decade, but are now attracting stronger interest as reconfigurable coprocessors. Several pioneering conferences on FPGAs have been held recently in the United States and abroad, and the Ohio Supercomputer Center recently formed the OpenFPGA (www.openfpga.org) initiative to accelerate adoption of FPGAs in HPC and enterprise environments.
There's a reason for this enthusiasm: FPGAs can deliver orders of magnitude improvements over conventional processors on some types of applications. FPGAs allow designers to create a custom instruction set for a given application, and apply hundreds or even thousands of processing elements to an operation simultaneously. For applications that require heavy bit manipulation, adding, multiplication, comparison, convolution or transformation, FPGAs can execute these instructions on thousands of pieces of data at once, with low control overhead and lower power consumption than conventional processors.
FPGAs have had their own historic barriers to widespread adoption. First, they traditionally have been integrated into conventional systems via the PCI bus, which limits their effectiveness like the specialized processors described above. More critically, adapting software to interoperate with FPGAs has been extremely difficult, because FPGAs must be programmed using a Hardware Design Language (HDL). Although these languages are commonplace for electronics designers, they are completely foreign to most HPC system designers, software programmers and users. Today, the tools that will allow software designers to program in familiar ways for FPGAs are just beginning to emerge. Users are also awaiting tools to port existing scalar codes to heterogeneous FPGA coprocessor systems. However, Cray and others are working to eliminate these issues.
The Cray XD1, for example (one of the first commercial HPC systems to use FPGAs as user-programmable accelerators), eliminates many performance limitations by incorporating the FPGA directly into the interconnect and tightly integrating FPGAs into the system's HPC Optimized Linux operating system. New tools also allow users to program for FPGA coprocessor systems with higher-level C-type languages. These include the Celoxica DK Design Suite (a C-to-FPGA compiler that is being integrated with the Cray XD1), Impulse C, Mitrion C and Simulink-to-FPGA from Matlab, which offers a model-based design approach.
Ultimately, as heterogeneous systems incorporating FPGAs become more widely used, we believe they will allow users to solve certain types of problems much faster than anything that will be provided in the near future through Moore's Law, and even support some applications that would not have been possible before. (For an example of the potential of FPGA coprocessor systems, see the sidebar on the Smith-Waterman bioinformatics application.)
Smith-Waterman: an Example of the FPGA Coprocessor Approach to Heterogeneous Computing
New techniques in genomics can provide millions of pieces of DNA from a few tests, but transforming the mountains of raw data into meaningful results can be a long, grueling process. Genes are usually represented as ordered sequences of nucleotides. (Similarly, protein sequences are strings of amino acids.) Investigators can infer a great deal about genes and proteins from their sequence alone, and answer questions such as the similarity of genes in different species by comparing sample sequences to ones already classified. However, to do this, accurate methods to determine the similarity between two sequences are critical.
Smith-Waterman is the most powerful algorithm available for accomplishing this (Temple F. Smith and Michael S. Waterman, “Identification of Common Molecular Subsequences”, J. Mol. Biol., 147:195—197, 1981). But the mathematical operations involved are difficult for commodity processors, and conventional systems deliver extremely poor performance. By attacking the problem with the Cray XD1—a heterogeneous system combining scalar processing with FPGA coprocessors—investigators can accelerate Smith-Waterman and get results up to 40 times faster than with conventional systems.
Characteristics of Smith-Waterman
The Smith-Waterman algorithm compares sample DNA or proteins against existing databases. Because both sample and database may have errors in the form of missing or added characters—and because a variation of a few characters can signify major biological differences—a highly accurate matching process is required.
Gene sequences contain four letters (G, C, A and T) for the four nucleotides, and protein sequences contain 20 amino acid characters. Because sequences are ordered strings, accurate comparisons must determine whether two strings align, as well as the letters they share. (For instance, in plain English, STOP and POTS share the same letters but cannot satisfactorily be aligned, while POTS and POINTS can, if a gap is created between the O and T in POTS.) Smith-Waterman uses “dynamic programming” to find the optimal alignment. This requires massive amounts of simple parallel computation, as well as heavy bit manipulation, and commodity scalar processors are extremely inefficient at these operations.
A conventional processor running Smith-Waterman requires thousands of unique steps to compare each piece of data. The number of instructions devoted to performing actual comparisons is a fraction of those devoted to determining the next comparison point and the surrounding logic. In fact, a scalar processor may devote only one instruction in 100 to comparisons—an efficiency rate of only 1 percent.
An HPC system using an FPGA coprocessor can provide several advantages that accelerate this algorithm. First, unlike general-purpose processors designed to support many different types of codes, FPGAs allow for a custom instruction set that closely mirrors the application. FPGAs also offer huge amounts of inherent parallelism, and they can be programmed to build thousands of compare units side by side and perform thousands of comparisons every clock tick. In addition, hardware computation is inherently more efficient than software at bit manipulation.
The Cray XD1 Approach
To understand fully how the Cray XD1 accelerates Smith-Waterman, it is necessary to understand the system's unique FPGA coprocessor architecture (Figure 1), as well as how the application itself functions.
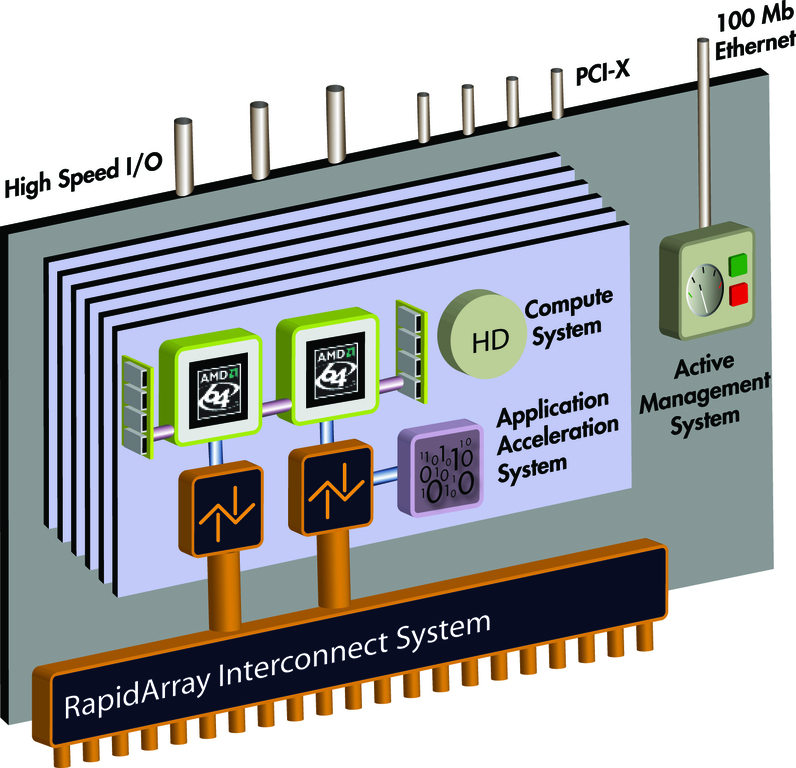
Figure 1. Cray XD1 System Architecture
Smith-Waterman formulates matches by first creating a scoring matrix and calculating each cell according to the value of cells above and to the left. Once this matrix is created, the algorithm calculates a maximum score, traces back along the path that led to the score and delivers a final alignment (Figures 2 and 3).
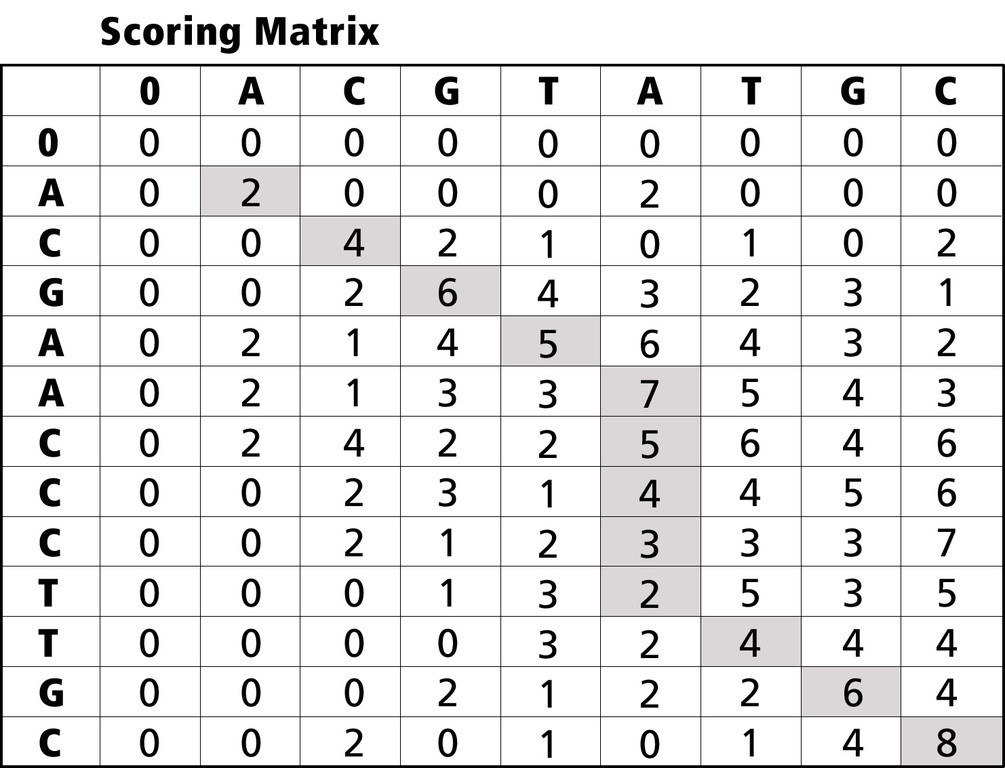
Figure 2. Scoring Matrix

Figure 3. Smith-Waterman Formulation
To accelerate this operation, the Cray XD1 partitions the algorithm between the system's FPGA and Opteron processors. The system uses the FPGA for filling the scoring matrix (which involves parallel computation) and sends back traceback information to the Opterons to regenerate the matrix (a serial operation). Effectively, the system's HPC Optimized Linux operating system calls the FPGA solely for the kernel of the Smith-Waterman application. But the massive amount of parallelism available with the FPGA coprocessor delivers results 25 to 40 times faster than conventional HPC architectures. Below is an example of the system interacting with the FPGAs:
/* Tilt the arrays by copying them to the FPGA. */
static void tilt (int fp_id, u_64 *trans_matrix, int row_len)
{
int i = 0;
u_64 status = 0;
/* Initialize the FPGA to accept a new stream of arrays. */
fpga_wrt_appif_val (fp_id, TILT_START, TILT_APP_CFG, TYPE_VAL, &e);
/* Copy the matrix to the FPGA. */
memcpy((char *) fpga_ptr, (char *) trans_matrix,
row_len*sizeof(u_64));
/* Poll to see if the FPGA has completed tilting the arays. */
while (1) {
fpga_rd_appif_val (fp_id, &status, TILT_APP_STAT, &e);
if (status & TILT_DONE) break;
}
/* When the FPGA has finished, all the transposed data will have */
/* been written by the FPGA to the transfer region of DRAM. */
/* Copy the data from the transfer region back to the array. */
// for(i=0;i<row_len;i++) {
// trans_matrix[i] = dram_ptr[i];
//}
return;
}
Advantages of the Cray XD1 Heterogeneous Architecture
With the application acceleration afforded by the Cray XD1, users can achieve much more timely results using the best algorithm available—instead of settling for tools that deliver less-accurate solutions more quickly. And, because the system uses the FPGA coprocessor solely for the kernel of Smith-Waterman, it can be updated easily as the rest of the application evolves. In addition, unlike dedicated hardware solutions that have been available to investigators, the Cray XD1 is a true, general-purpose HPC system. It is not limited to running a single code, and it can be applied to other bioinformatics applications just as easily as Smith-Waterman. In short, the Cray XD1 provides an effective, affordable and investment-protected solution for delivering unprecedented performance on critical life science applications.
Although many exciting avenues of exploration are underway today in the field of heterogeneous computing, we are not yet at the point where this model will take over as the dominant HPC system architecture. The barriers that remain (primarily, difficulties programming for and porting existing code to heterogeneous systems) are significant. However, Cray and others in the HPC community are already making strides in these areas.
As with any new technology, widespread adoption of heterogeneous systems will depend on an analysis of the gains that can be achieved versus the effort required to realize them. In the long term, we believe that the performance advantages offered by heterogeneous architectures for some applications will be too compelling to ignore.
Amar Shan is a senior product manager at global supercomputer leader Cray Inc. Shan joined Cray in 2004 when Cray acquired OctigaBay Systems Corporation and is responsible for setting product direction for Cray next-generation products and the Cray XD1 high-performance computing (HPC) system—the only Linux/Opteron system designed specifically for HPC applications. Shan holds a Master of Applied Science in Artificial Intelligence from the University of Waterloo and Bachelor of Applied Science in Electrical Engineering and Computer Science from the University of British Columbia.

