
At the Sounding Edge: Introducing seq24
In this month's column, we look at the seq24 MIDI sequencer to see how you can use it in a Linux-based MIDI music production system. Given working ALSA and JACK installations, this system is easy to set up and use, great fun and a valuable production tool. Feel free to follow along while I walk through some of the program's basic techniques and introduce some not-so-basic procedures before taking my leave.
On his seq24 Web site (see Resources), developer Rob Buse describes seq24 as:
a loop based MIDI sequencer...created to provide a very simple interface for editing and playing MIDI loops...that would provide the functionality needed for a live performance, such as the Akai MPC line, the Kawai Q80 sequencer, or the popular Alesis MMT-8...a very minimal sequencer that excludes the bloated features of the large software sequencers and includes a small subset of features that I have found usable in performing.
Like Rob's description, seq24 itself is small and sweet, providing simple interfaces for pattern and song creation. If you've worked with Old School MIDI gear, such as Roland's TR drum machines or the hardware sequencers mentioned above, you should feel right at home with the program. But, even if seq24's design is totally new to you, you soon will be comfortable with it.
Pattern loop sequencers assume a bottom-to-top workflow from the creation of individual patterns to their repetition and linkage to a larger form. seq24 calls this linking stage a Performance. Patterns and Performances can be recorded in real time or in step-time. Almost every aspect of seq24 is intended to function in real time, but it is equally serviceable to those of us who like sequencing note by note.
seq24 is available as a package for users of the AGNULA/Demudi and PlanetCCRMA systems. It also is available in Thac's RPMs for Mandrake and as a source code tarball on the seq24 Web site. I prefer to roll my own, so the version demonstrated here is built from the 0.6.3 tarball. I assume you already know how to install your package of choice, so let's speed along and dive into making some music with seq24.
If seq24 is in one of your application menus, simply click on its name or icon to start the program. If you choose to launch seq24 from an xterm, you can run it with the --help option to view a list of other command-line options. Otherwise, enter seq24 at the xterm prompt to launch the program in its default state. When it starts you should see the screen shown in Figure 1.

Figure 1. Starting seq24
Each bracketed area is a sequence container. Right-click within a container and select New from the popup menu to invoke the pattern sequence editor seen in Figure 2.

Figure 2. The seq24 Pattern Editor
Let's look closely at the various parts of the pattern editor. The top strip includes an entry box for a sequence name, followed by drop-down selectors for meter and sequence length, displayed as bars. The next strip includes quantization settings for note start-time and duration, a zoom view control and settings for MIDI device target and output channels. The next strip contains the all-important Undo button, a toggle for the Tools menu, two controls for sequence key and scale type (major/minor) and a selector for a background sequence to be played while composing the current pattern.
In the event entry grid you can enter, delete and edit note events in a familiar piano-roll display, where the vertical axis represents pitch and the horizontal axis represents time. Notes can be selected individually or in groups, and the few edit procedures include some quantizing and transposition options. By the way, the Snap-to setting applies to edit groups as well as to individual notes.
The blank area under the grid is dedicated to controller and velocity editing. The strip beneath that area offers an event selector for the controller edit area and three buttons for defining the MIDI I/O for the pattern. Don't worry if you can't immediately recall all these features; seq24 provides informative tooltips for almost every aspect of its interface.
It's time to record something with seq24. After opening a new pattern, I select its MIDI output destination and click on the third MIDI I/O button in the lower right to record incoming MIDI data. I hit the Play button on the seq24 main screen, play some notes on my MIDI keyboard and behold, I've recorded a new pattern into seq24. Next, I perform a little quantization by selecting a group of notes and applying the quantization function from the Tools menu. I then do a little velocity editing by clicking right or left within the controller edit area and dragging an edit line to shape the displayed values. Figure 3 displays the results so far.
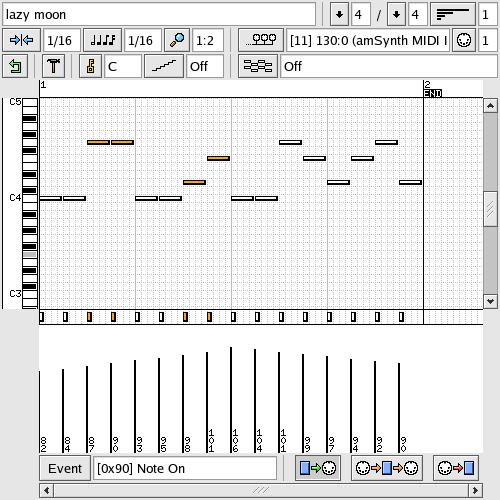
Figure 3. Recording a Pattern
I also like step-entering events into a sequencer using the mouse, the computer keyboard, a MIDI keyboard or a combination of these methods. seq24 has no problem with any of these methods, and of course, it supports real-time recording with any or all of those input devices.
Whether in real time or not, repeat the process to create more patterns. Use the copy command from the expanded popup menu in an occupied sequence container and then paste a copied sequence into any empty container to create a variant of the original. When you have enough patterns to link together into a song form, it's time to employ the seq24 Performance editor.
The Performance editor (Figure 4) also is easy to use. Right-click and hold to bring up the pencil edit cursor, and left-click while holding to enter or delete a pattern. Concurrent patterns are allowed, and patterns can be added or removed in real time. Playback is either normal or defined by the loop points. The loop points are moved by selecting one of the L/R markers with the appropriate mouse button—left for L, right for R—and then clicking with the same button at the new location. The loop points also can be edited in real time.

Figure 4. seq24's Performance Editor
The three buttons in the top-right corner of the editor expand, collapse or expand and copy the material between the L/R markers. They are simple but useful tools for working with larger formal designs and elements of a composition.
Saving your work in seq24 is as uncomplicated as the rest of the program. Select File/Save As, give your work any name you like, with or without any extension (MID is best), click OK and that's it. From that point on, you simply can use File/Save. Reloading your work is equally simple.
seq24's native file format is the Format 1 standard MIDI file format. seq24 also can load a MIDI file and break its individual tracks into sequence containers. This feature is another neat musical extension to seq24's utility, offering new possibilities for material from other sequencing environments.
Despite its evident simplicity, there is more to see in seq24, but the program is easy to learn. Complete documentation is found in a brief text file named SEQ24. Also, starting the program with the --help long help option lists the available command-line options. The tooltips help is well-written and should clarify the interface even for complete beginners.
As a final tease, I leave you with the screenshot in Figure 5 to illustrate seq24 accompanied by some friends and helpers. seq24 manages its MIDI I/O internally (see above), and the synths it drives in the screenshot are all JACK clients. I use QJackCtl's audio connections panel to route the audio data to and from my selected synths and effects processors. In Figure 5, the output ports for QSynth and amSynth are connected to the JACK Rack running a single LADSPA plate reverb plugin. The processed output from the JACK Rack is connected to the ALSA PCM audio output ports. ZAddSubFX has its own effects, so its output is connected directly to the PCM ports.
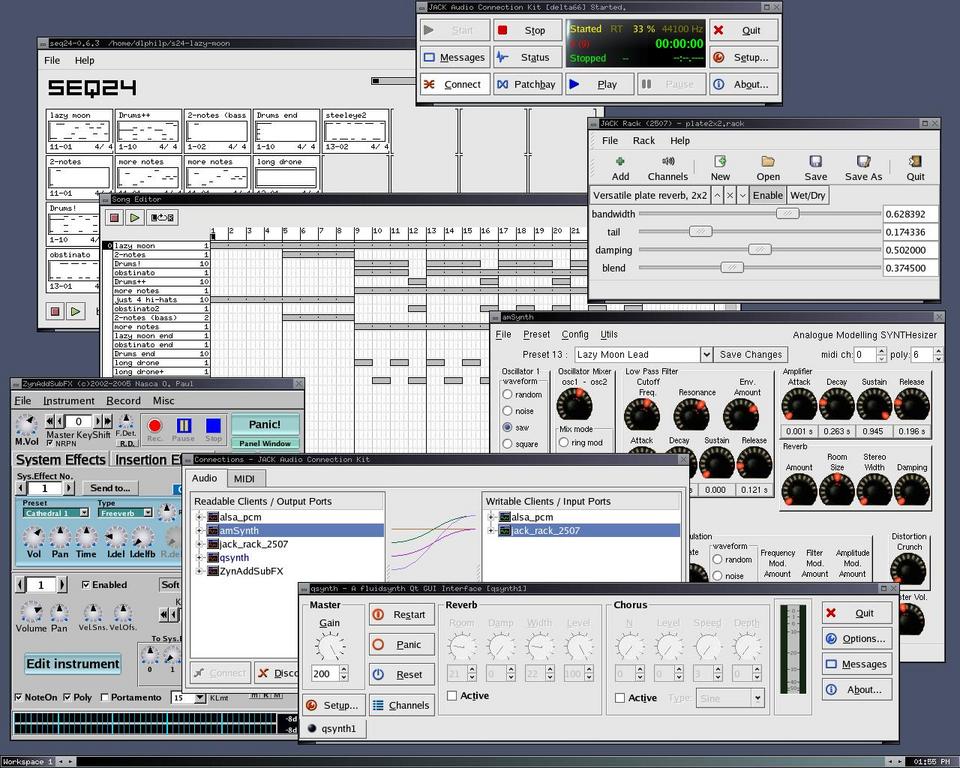
Figure 5. seq24 and Friends
Thus, I have seq24 driving QSynth, amSynth, ZynAddSubFX and my SBLive's EMU10k1 synth (internal connection), with two of these devices routed through a software reverb unit. If you'd like to hear what this system sounds like you can visit this page for some brief examples in the OGG audio format. They're not complete pieces, but they should give you an idea of what can be done with some of the modern Linux audio and MIDI software now available.
seq24 can be invoked as a JACK transport client, giving it synchronization capability as either a JACK master or slave. Alas, my tests failed, which may be due to my JACK version. JACK sync is a cool feature, so I'll keep checking in on this one. Judging from the tarball's TODO file, other likely additions might include a few more edit functions and some randomization routines.
seq24 is not a complicated program. It has been designed for speed, stability and efficiency. Admittedly, it is short on editing functions and long on usability, but its features are well chosen and musically useful. It's also incredibly addictive fun, as befits any serious musical instrument.
Dave Phillips is a musician, teacher and writer living in Findlay, Ohio. He has been an active member of the Linux Audio community since his first contact with Linux in 1995. He is the author of The Book of Linux Music & Sound, as well as numerous articles in Linux Journal.

