
Exploring Ruby on Rails
When I found out that my friend, Doug Fales, finally had gotten around to learning Ruby and was putting together a blog using Ruby on Rails (RoR), I knew it had been too long since I'd left the world of templating engines for satellite imagery and petabytes. It seemed that every blog I read either was proclaiming Rails as the new juggernaut of Web frameworks or was damning it as the scourge of developers everywhere. Now, I generally assume anything that's simultaneously causing so much adoration, protest and reflection must have something going for it, and rumors that Dave Thomas was putting together a book on RoR only fueled my motivation to find out all that I could as fast as I could. So I installed Rails, raced through a few tutorials, started reading the source and called Doug to get the lowdown straight from the horse's mouth.
Linux Journal: Doug, tell us a bit about yourself, what kind of development do you do?
Doug Fales: My job at Mercury Interactive is writing Java code. I'm exposed to lots of different technologies, because the application that I work on is a Web-based monitoring tool. I'm writing Java code that needs to interface with SNMP stuff, JMX stuff or some custom vendor library, but at the same time, since it's Web-based, I'm also writing UIs for the new functionality that we come up with.
LJ: What's the environment?
DF: The laptop that I primarily develop on is Windows XP Pro, and then I have a couple of boxes under my desk--one is SuSE 9.0 Linux and another is a Windows box. We're writing in Java, using IntelliJ.
LJ: How about at home, what kind of tools do you favor?
DF: Well, I just got a G5 desktop for my birthday, so I'm psyched about that. I really love Linux and the BSDs, so that's what I try to develop in. My editor of choice is vim.
LJ: I know you just [started] a blog using Ruby on Rails. Had you done much Ruby coding before that?
DF: No. I was auditing a network security class in the fall of 2004, and because you always were preaching to me about Ruby, I decided to use Ruby for one of the homework assignments, an e-mail client that used a lot of OpenSSL stuff.
LJ: Console or GUI?
DF: It was GUI-based. I used Ruby-Tk.
LJ: Your first Ruby program was a GUI?
DF: Yep.
LJ: Ambitious. Any particular reason you initially chose Rails over some other framework for your blog?
DF: By this point in my career I've seen enough scripting languages and learned enough languages that I'm not running out there to learn a new scripting language as soon as it comes out. It's really got to be something special for me to want to learn it. You were the catalyst for getting me into Ruby, and because the Rails hype was starting to reach critical mass at the same time, that's what drew me into Rails.
LJ: Okay, so you obviously had to set up a Rails environment, and I'm sure people are wondering how much work that was. Give us a quick rundown on what you had to do to get it set up.
DF:Well, I started setting it up on my old 450MHz SuSE Linux box, and I had a late night or two getting things up and running, but, you know, on Linux, a lot of the stuff I needed was already there.
LJ: I want to point out here that there's already a lot of really good tutorials available, including Curt Hibbs OnLAMP articles, both Part 1 and Part two. Amy Hoy's follow-up to these articles also is good reading for anyone out there looking to get going with Rails.
LJ: What's the first step with Rails? What are the first steps to turning some concept into code?
DF: That's a good question, because it brings up an important point about Rails that might be foreign to you if you're coming to Rails from a different framework or a different programming environment. There's a lot of code generation and a lot of the boilerplate code is generated or already exists. So, the first step with Rails is to run the rails command with the name of your application in the directory where you'd like to serve the application. For example, enter
~ > cd /var/www/htdocs/www.mysite.com && rails mycoolwebapp
and boom, this whole hierarchy is created for you.
LJ: Then what?
DF: There are a few main directories in this hierarchy that you will be spending most of your time in as a Rails application developer. The main directory is called app, and it's where your Web application will go.
LJ: So, I can imagine you might have a table representing posts to your blog, something like
create table blog_posts ( id serial, post text, created_on timestamp, primary key (id) );
How do you go about getting a handle on that table in Rails?
DF: After you create your application, you would generate a model called BlogPost.
LJ: Rails is pretty big on MVC, huh?
DF: Definitely; the whole framework (see Figure 1) is based on this paradigm.
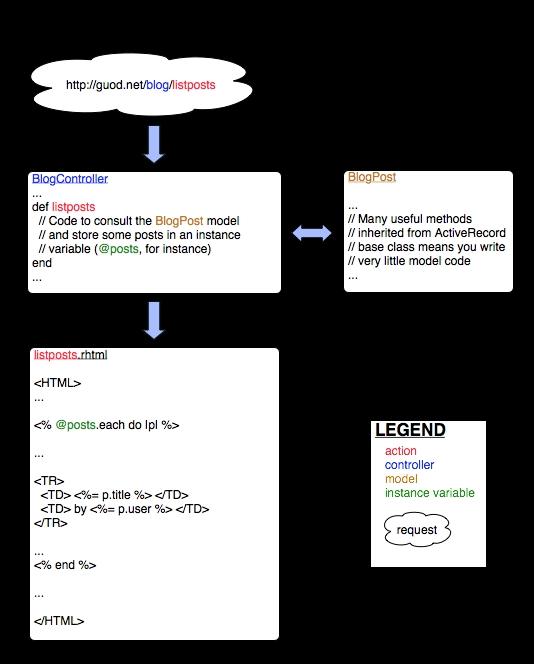
Figure 1. The Rails Framework
LJ: So how do you generate this model?
DF: First, and this is really the only configuration step in Rails, you'd edit the ./config/database.yml file to reflect your database of choice--MySQL, PostgreSQL, SQLite, whatever. Basically this is username and password stuff. Next, there's a script called generate in the script directory. You give this script one argument for what type of object you want to generate, for example model or controller, and a second argument for the name of the object you are generating. In our example it would be:
~ > ./script/generate model BlogPost
LJ: Hmmm. Let me get this straight: you ran the rails command, which is itself a code generator, initially to populate a directory hierarchy with a bunch of stuff in it. And then one of those files, the generate" script, is used to generate more code for this specific application?
DF: Correct.
LJ: How did you configure the table to model-class mapping?
DF: You don't. Basically the class that rails generates is totally empty. It will look something like this
class BlogPost < ActiveRecord::Base end
Because this class inherits from ActiveRecord::Base, it knows how to find its table in the database at runtime.
LJ: But we were talking about a table named "blog_posts"?
DF: Right, and it's named--this another important point that you bring up--it's named after what it contains: blog_posts, plural. And the model that you generate for that table is called BlogPost, singular. Rails has a smart Inflector class that does all this translation, but you can override it if you want.
LJ: I see Rails knows English better than I do. Your class is empty, so how do you configure the database to instance-method mapping?
DF: Again, you don't; ActiveRecord::Base handles that for you. It dynamically responds to methods at runtime, so if you call the method category on an instance of BlogPost, which, of course, represents a single row of the blog_posts table, it knows how to get that column. It knows how to look up the field "category" from that row.
LJ: What if you altered your blog_posts table, say you added a column, something such as the time the post was entered?
DF: If you followed convention and added a field named created_on to the blog_posts table, you'd get a bunch of stuff for free. First, any field in the table automatically has both getter and setter methods dynamically determined at runtime, even if the column is added later. Second, certain column names have special meaning to Rails, and created_on is one of those. A column with that name is handled automatically by inserting the creation time of the row as the transaction time at which it was created.
LJ: How do you know which column names are special?
DF: You'll want to read the API and, failing that, check out the mailing list.
LJ: And these automatic methods to access the table columns, do they return strings because they are so generic?
DF: Nope. Rails inspects the database schema and maps the columns to the appropriate types. So an int comes back as a Ruby Fixnum, a timestamp comes back as a Ruby Time object and so on.
LJ: You still haven't talked about writing any code.
DF: True. Nothing so far requires any [code] to be written.
LJ: Well, your database is pretty boring at this point; you've got only one table. How does Rails handle relationships between tables?
DF: In my opinion, this is where the real magic of ActiveRecord starts. Reflecting on the database to give a model-class getters and setters is pretty cool, but handling inter-table relationships intelligently goes to another level. Comments in a blog are a great example of this. Normally, a blog post has several comments associated with it, assuming your readers aren't too lazy to post them. Likewise, a comment always belongs to a blog post. In the database, then, a common way to implement this is to use a foreign key in one of the tables. For instance, my blog_comments table has a column labeled blog_post_id, because ActiveRecord understands this naming convention. The only other thing I had to do to connect my BlogPost model with my BlogComment model was add two lines of code, one to each of the models:
class BlogComment < ActiveRecord::Base belongs_to :blog_post end
and
class BlogPost < ActiveRecord::Base has_many :blog_comments, :order => "date" end
This, of course, assumes a some schema such as this one:
create table blog_comments ( id serial, comment text, blog_posts_id int, primary key (id), foreign key (blog_posts_id) references blog_posts (id) );
After I did this and played with the code a little bit, I realized how cool it was. Automatically an instance of BlogPost had a new method called comments that would yield an array of the comments whose foreign key, blog_post_id, matched the ID of the BlogPost instance. The same was true of a BlogComment instance; a method named post provided the BlogPost instance associated with that comment via the foreign key.
LJ: So Rails dynamically generates join selects if it has been told two tables are related?
DF: Yep.
LJ: That's almost like configuration.
DF: Well, true, but because it's done in a fully fledged programming language such as Ruby instead of a data language such as XML, it can do so much more. For instance, if we're working with a database that didn't support foreign keys, such as SQLite, and you defined the relationship like this
class BlogPost < ActiveRecord::Base has_many :blog_comments, :order => "date", :dependent => true end
Rails would handle cascading delete for you. That is, deleting a BlogPost would result in all its associated BlogComments being deleted too, even though the underlying database may not enforce foreign keys or cascading deletes.
LJ: But surely well-designed classes could grok XML that somehow dictated cascading deletes?
DF: Yeah, that's true, but it's really nice for the programmer to be able to keep everything--model, view, controller--all in one language. In Rails you don't have to split out state and behavior into separate files; you can describe it all in one file using the same language. Plus, in practice, only a few of these configuration steps even need to be taken, because Rails model-objects are designed to reflect on the database at runtime. It's not an exaggeration to say that your entire controller-class could end up being shorter than a single XML configuration file.
LJ: So I understand that you can use this model-class to sling data around in Ruby and have it magically written to the database. How do you go about presenting it to the user and allowing them to interact with it?
DF: It's probably easiest to start with the controller. Basically, Rails decides what object to send a method to based on the URL. So when a request such as
http://guod.net/blog/postlist
comes in, it ends up calling something like this
BlogController.postlist
LJ: So, the URL is unpacked to decide which method to send and to which controller class to send it to. Aren't there some security issues with that? What if you end up calling some method you didn't intend to expose on your controller object? It seems really unsafe.
DF: That's a good point. It can be unsafe if you're not aware of that, if you add all kinds of functionality as public methods to your controller class, you're exposing all of this functionality to the world. Generally, you put code you don't want to expose to the public in private methods.
LJ: Basically, Rails leverages Ruby's access control and introspection to know what should be exposed to the Web interface. How does it know that? Do you have to configure that?
DF: You can't call just any public method on a controller object, the public methods inherited from the root Object class are filtered and denied. But any public methods that are added to a controller class are automatically available as actions. Instead of configuration you have convention, and that convention is any public method you add to a controller class is an action that can be accessed by a correctly formatted URL. The fact that Rails even can do this is testament to Ruby's dynamism. You can do crazy things like
~ > cat a.rb
class BaseClass
def BaseClass::method_added methodname
puts "<#{ methodname }> should be accessable"
end
end
class DerivedClass < BaseClass
def an_added_method
end
end
~ > ruby a.rb
<an_added_method> should be accessable
and Rails leverages this from every angle.
LJ: You didn't write this controller from scratch, did you?
DF: You guessed it. The generate script also is used to generate your controller classes, web_services and so on. Typically, you simply generate the class and then start editing from there.
LJ: I understand that URLs are mapped to a method call on a controller object, but how does that finally end up spitting out HTML?
DF: The standard Rails HTML generating mechanism is the ERb template. ERb, as you know, stands for embedded Ruby, and it is a simple way to embed small pieces of Ruby code into HTML documents. So for each action in a controller, you typically would have a corresponding "view" consisting of an ERb/HTML template file (.rhtml) with the same name as the action.
LJ: And you have to set up some sort of data structure for the template to access?
DF: Not really. The view has access to the instance-variables of the controller. It's a lot like they are friend classes in that the instance-data simply is available in the view templates, as if it were in the same scope.
LJ: Then, rendering the view effectively works like a method call on the controller object--all of its internal state is available for the view to access?
DF: Pretty much.
LJ: I have some notion now that each table in your database is going to have a model and each page in your blog is going to have a controller and view class associated with it. The arrangement looks, more or less, like Figure 2. I'm wondering how many classes you ended up with, how many lines of code?

Figure 2. The Blog Arrangement
DF: Well, to get something working, it probably was between 400 and 600 lines of my own code and a half dozen controller-classes. But, that includes quite a few things such as authentication and administrative pages. Obviously, that number could be improved upon--I'm a Ruby newbie--but I'm happy with the codebase size.
LJ: Have people been liking your blog?
DF: I think people have liked it; I mean my programmer friends read it. It's nothing special, I'm not going to replace WordPress or blogger.com, but my buddies get a kick out of reading it and posting comments, and my parents are coming around slowly. I think people like it mainly because there are pictures of my daughter up there all the time.
LJ: What about your programmer friends? What has their reception been to you developing in Ruby on Rails?
DF: A lot of my friends have been really interested. Some of my friends who are in grad school have started to embrace Ruby for some of their projects. I even have a friend who wrote an iCal library in Ruby and now is planning on rewriting his own Web site using Rails.
LJ: But some big name developers out there seem to have had a fairly negative response to all the Rails hype. Why do you think that is?
DF: I think fear of any technology is not really based in reality, because what is technology after all? It's just another way of solving a problem. But I hear what you're saying, I've read some comments that I feel totally were not based on the facts. I think that some of it is probably due to people who really are invested in one framework or the other and maybe are afraid that Rails' momentum could threaten their authority or their opportunities if it were to take over a lot of market share in "web-app-framework-land". So there's that, and then there's the whole thing of if this becomes "the way to do it", then they'll have to start learning a whole new language and framework all over again.
LJ: Did you have a tough a time learning Ruby as you were learning Rails?
DF: No, I didn't.
LJ: I remember when you and I were doing a code walk-through the other day, and you said you didn't even know how to assign a hash element. I thought it was pretty amazing that you'd written an entire blog and didn't even know a language fundamental such as that one. It says something about the ways Rails was designed that you don't have to be a guru in the language to do a fairly complex Web application with it.
DF: Yeah, that's one of the things Rails has to offer: Ruby. That's awesome. People miss that point--the language is awesome. It's fun to write in. The Rails framework itself is fun too, and it's very fast to develop in.

