
Easy Database Development Using Rekall
The issue of cross-platform programming will become bigger over the next few years, as companies—particularly small- and medium-sized businesses—see the advantages of migrating to Linux and take the smart road by migrating a few machines at a time. Being able to develop vertical-market applications quickly that run on the multiple platforms a client has will become a competitive advantage for those consultants who are able and smart enough to do so. With Rekall and PostgreSQL, that ability is available here and now.
Last year, I was approached by my homeowners' association about replacing an old Microsoft Access application. I had completed assignments like this in the past using various toolkits, such as a combination of Glade, C++ and Sybase ASE, and then later, Apache, PHP and PostgreSQL. This time I was faced with a number of restrictions: the software had to work under Microsoft Windows as well as Linux; the software had to have a local thick client; and the software had to produce reports.
The database back end was a no-brainer; I used PostgreSQL. Having access to PostgreSQL version 8 under both Linux and Windows is not only a testament to the power of great free software, but it also provides an extremely fertile ground upon which to grow cross-platform applications that are robust and scalable. With a suitable front end, it does not matter if your server is Linux or Windows or how many of your desktops are Linux or Windows. This is great for companies pondering a switch to desktop Linux for some or all of their employees.
For the front end, I wanted a development environment that would allow me to design forms, reports and the databases to which they connect quickly. Cross-platform operation was a must, because the association was interested in migrating to Linux for some of their employees, while keeping Windows on the desktops of those who used proprietary Windows-only applications.
During my search, I ran across several tools that purported themselves to be like Microsoft Access, only better. All of these tools allow access to multiple databases as well as ODBC sources, and they are scriptable using some form of BASIC, JavaScript or Python. These tools included Kexi, OpenOffice.org Base, Kylix, Knoda, Rekall and Glom.
Of those products, the only two that claimed to be production-ready were Kylix and Rekall. So, I investigated them further. After finding out that Kylix does not have built-in support for producing reports, I concentrated my research on Rekall.
Rekall is developed by the British company Series One Consulting. Mike Richardson, the primary consultant at Series One, began writing Rekall in 2001 due to his frustration at the lack of database development tools under Linux. Mike was joined by John Dean, who took charge of Windows and Macintosh development and wrote drivers for Oracle and DB2.
Rekall was distributed commercially by TheKompany as one of its cross-platform development applications. In late 2003, the distribution contract ended, and Series One decided to distribute Rekall themselves. If you decide to check out Rekall, be sure to get it from either the TotalRekall or RekallRevealed Web sites, as these are the versions actively supported.
Rekall is available under two licenses, the GPL and a proprietary license. This is due in part to the fact that it is built using Qt, and at the time it was first developed, TrollTech did not offer the Windows version of Qt under the GPL. Therefore, you can download the Linux version of Rekall from the RekallRevealed Web site as source code and compile it yourself. Or, you can pay 25 pounds (roughly $45) for a download of the Linux, Windows and Macintosh binary installation packages. Additionally, Series One offers database drivers for ODBC, Oracle and DB2, as well as runtime packages, at additional cost.
The next version of Rekall, 2.4, is scheduled to be delivered in several different versions. The GPL version always will be available in source form. Additionally, Series One plans to offer a Professional version that includes two additional features:
Encryption allows you to distribute your applications without worrying about someone copying your source code. The encryption provided by the Professional version of Rekall will allow you to distribute your application and secure it on a per-client basis.
Web application creation allows you to take any Rekall application and make a LAMP-based Web application out of it. This can be seen on the RekallRevealed Web site.
In my application, I found only a couple of drawbacks to using Rekall. First, there is no straightforward way to create menu bars. Second, the applications produced by Rekall are not encrypted.
In a Rekall application, there is a standard menu bar and toolbar with commands that allow the end user to execute queries and complete other tasks. It's fairly feature-complete, so if you want to limit what your users can do, you have to turn the menu and toolbars off completely. If you don't mind hand-editing XML files, there is a way that you can limit which buttons and menus show up or even create your own. However, this is not a supported use, so it would be helpful if the authors would include this in the next version.
All of the code, as well as the XML describing an application's forms, is stored as text either in the filesystem or in the database. If you're developing a potentially lucrative application, it might be best to wait until encryption and Web application creation is complete. Or, investigate technologies such as FreeNX that allow you to deliver the application as a service. Purchasing a runtime library to distribute with your application would allow you to restrict the things your end user could do, as the runtime libraries don't include the development tools. But, doing so would not prevent savvy users from downloading the full version of Rekall and taking the code from your application to use in their own or editing those files to add their own functionality. When the Professional version of Rekall is released, you will be able to scramble your applications on a per-client basis with private key encryption.
Of course, having everything in plain-text XML also is a lifesaver. Recently, I realized that I had a series of component groups, otherwise known as blocks, that were misconfigured. Instead of having to cut and paste or redo the layout of 11 fields in each block, I simply modified the XML defining the blocks to point to the tables instead of the queries, and it worked flawlessly.
After developing for a while on the Linux version of Rekall I downloaded as source, I tested my application on the version I purchased as a Windows install. My application looked identical in both environments. In fact, porting to Windows was a breeze: I simply performed a backup of the PostgreSQL database on my Linux box and copied that file, as well as the Rekall project file, to the Windows box. There, I restored the backup file to the Windows version of PostgreSQL 8.0.2 and ran the project file in the Windows version of Rekall.
The Windows install is reasonably sized at about 7MB. You have to be careful, though, to install the right version of Python before you install Rekall. For Rekall 2.2.3, the current version, you need any Python version in the 2.3 line.
Compiling under Linux was fairly straightforward. Under CentOS 3, the compile produced no errors and installed cleanly. After upgrading to CentOS 4, I received compile errors during the install, but the application did install cleanly. The compile process took about an hour on my relatively old 900MHz Athlon-equipped CPU with 512MB of RAM.
The first time you run Rekall, it presents you with a series of dialog boxes to configure certain behaviors of the development environment. Among these behaviors are the verification of record updates and deletes as well as the layout of the development environment. After this occurs the first time, it doesn't happen again unless the user's Rekall configuration file is deleted.
To demonstrate the ease of development in Rekall, I put together a small application that tracks philosophers and their writings. This example provides a good examination of both the ease of development and the Python scripting capabilities of Rekall. The end goal was an application similar to what you see in Figure 1—a small data-entry window with two tabs, a report and a status bar at the bottom describing the current philosopher.
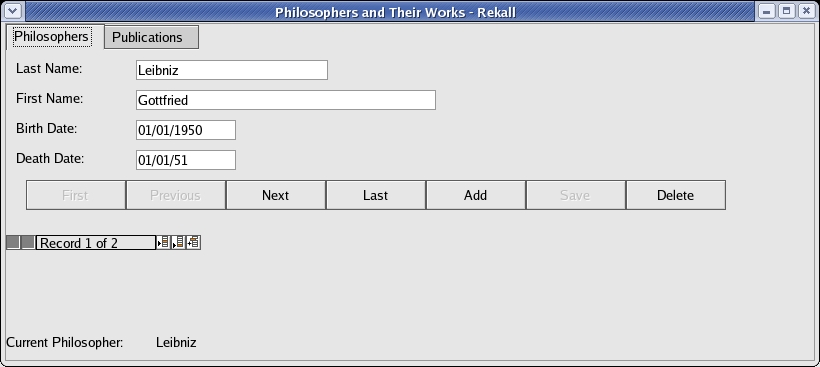
Figure 1. The Completed Philosopher Application
Before you begin, you need to configure PostgreSQL to work well with Rekall. Configure PostgreSQL to support connections from local applications, as is shown in the Configuring PostgreSQL sidebar. After this is done, add a user philosophy_major with a password and create the philosophers database. This all must be done before the initial connection by Rekall, because Rekall does not have the capability to add users or databases. After a reload of the PostgreSQL server, it is ready for you to connect.
Now, we need to create the project. Open a terminal window and make a directory for the project. Then, fire up Rekall by typing rekall on the command line. After installation, the rekall executable should be under the /usr/bin directory.
Starting a project is straightforward. After clicking on the New button, you are presented with a project creation wizard. On the first screen, you enter the directory where your information should be stored, as well as the name of the project, the Database Name). In the next dialog window, tell it where to store the forms, reports and other XML structures. These items can be stored either in the database, in a special Rekall Objects table or as files in the filesystem. After you choose that, select which database platform you're using. You can have multiple data sources, each running a different driver. This particular dialog controls the main database.
The next two dialogs allow you to enter the database host and port as well as the user name/password pair you want to use to connect. Then, upon a successful connection, you specify which database you want to use.
After you select the database, a screen similar to the one shown in Figure 2 appears. Now you can start building your application. The first step in application building is to create the tables. To do so, click on the Tables item in the Objects tree. Then, select the correct server and double-click on Create new table. The table builder, as shown in Figure 3, then appears.
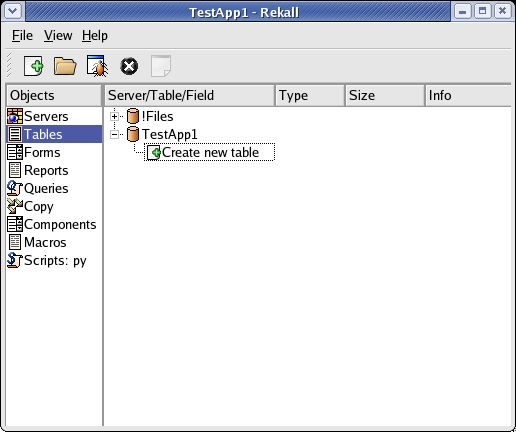
Figure 2. From the main project window, you can drill down to set up tables and create forms and reports.
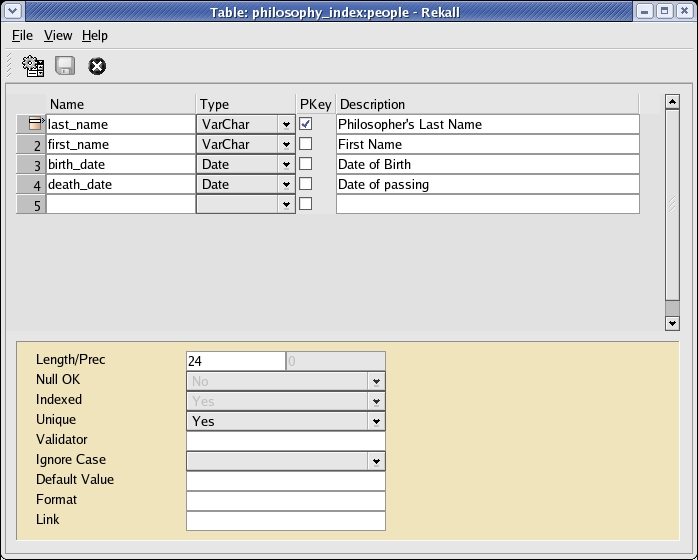
Figure 3. Create a new table using the Table window.
Rekall can't use tables that already exist. It would be an interesting exercise to write a utility to convert database schemas to Rekall definition files. Right-clicking your project name listed in the Tables tree reveals a menu that allows you to import a table definition, and this is contained in an XML file that could be built from SQL table definitions.
Next, it's time to build some forms from the database schemas you've created. Fortunately, Rekall provides some easy tools with which to do so. When you click on the Forms item in the Objects tree and expand the item named after your project, you can create a form or create a form with a wizard. Even when creating complex applications that use things such as tabbed pages, it's helpful first to create each page as a separate form, copy those objects and then paste them into the appropriate blocks on your form.
In Figure 4, you can see how I've used the wizard to create a form based on the philosophers table. You have a large amount of control over your forms, even when you use the wizard. Not only does it ask you for a table and fields to use, you also can specify multiple records per page, field formats and the tools that should be added automatically to the page. In the form in Figure 4, the wizard added the buttons you see along the bottom of the screen, as well as the small navigation tool at the very bottom. Called a Nav. Tool, this widget allows you to navigate through the database on a record-by-record basis.
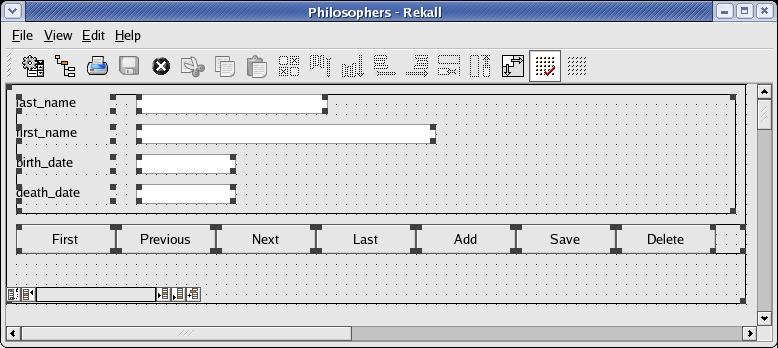
Figure 4. The form wizard does most of the work for you, but you have a lot of flexibility in designing the form.
After creating the forms for Philosophers and their Publications, as seen in Figure 5, I need to combine them into one window. This is where it is advantageous to create a form by hand, so that I can to add components at will. Before I do that, however, we need to examine the concept of blocks.
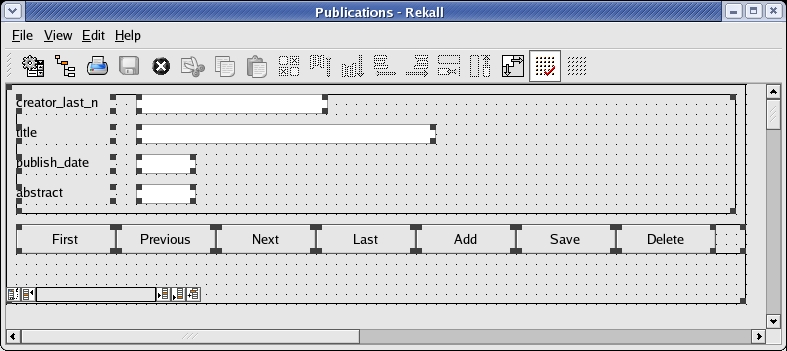
Figure 5. The publications form will be part of a notebook window, with the main Philosopher form shown in Figure 4.
In a Rekall form, data is represented in an entity called a block. There are several types of blocks, the simplest being a table block. Other types of blocks include query blocks and SQL blocks, which display data retrieved from a query. A form can have any number of blocks. These blocks can exist side by side or in any configuration on the same visual plane. Alternatively, they can exist as pages in a notebook by way of a tabbed-page control. This is what I exploit to get to my one-window goal.
To create my notebook, I create a new form without using the wizard. After I select that command, I get the Form Attribute window shown in Figure 6. As you can see, I've configured a basic window. It's not stretchable, there is no status bar and the top-level block type is null— it's called a menu block in the selection dialog. Setting the top-level block type to menu only or null is what allows us to place blocks and controls arbitrarily on the form.

Figure 6. Creating a Rekall Form with a Null Top Block
After going through each attribute by clicking on it, making a selection and pressing the Accept button at the bottom of the dialog, I am presented with a Block attribute window which that much like the Form Attribute page. Because this is simply a menu block, I safely can accept many of the default values, as most values are appropriate only for table or query blocks. That action nets me a blank page, which I can resize appropriately and add the tabber control.
On each page of the tabber control, I simply create a table block corresponding to the correct table. Then, I copy all of the contents from the block contained in the Philosophers form to the corresponding block in the Philosophers tabber page, and I repeat the action for the Publications page. After doing so, I dress up the fields with their correct names, modify the size of the Abstract field on the Publications page and my notebook is complete.
Now, I need to find a way for the Philosopher page to set the key that is used to look up the publications. I do this through the use of the status label at the bottom of the main form, underneath the tabber page control. This label's text value is set whenever a database lookup is performed or a new entry is created. The label is set when the code, shown in Listing 1, is run by way of a callback set by the On Display event for the Philosophers block. When the Publications block is shown, the On Display event is called for that block, which sets a user filter on the data shown in that block. The user filter code can be seen in Listing 2.
Listing 1. The On Display Function for the Philosophers Block
def eventFunc (block, row) :
someMainForm = block.getForm();
currBlock = block;
dataLabel = someMainForm.getNamedCtrl("current_philosopher");
dataLabel.setText(currBlock.getNamedCtrl("last_name").getValue());
Listing 2. The On Display Function for the Publications Block
def eventFunc (block, row) :
mainForm = block.getForm();
currBlock = block;
dataLabel = mainForm.getNamedCtrl("current_philosopher");
currBlock.setUserFilter(dataLabel.getValue());
Finally, I need some way of listing the philosophers I have in my database. Figure 7 shows the report functionality of Rekall.
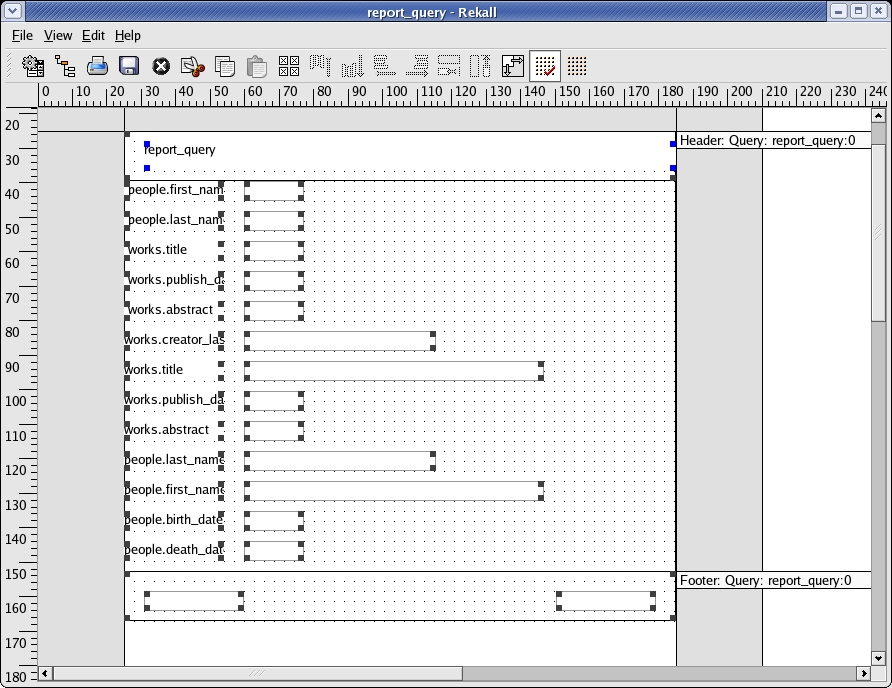
Figure 7. The report design window builds report layouts as easily as designing a form.
Rekall also offers a number of other components, such as reports, queries and data copiers. Each component can be created with the same ease and offers the same versatility as the forms.
As I have demonstrated, Rekall and PostgreSQL offer the ability to complete all kinds of database programming tasks quickly under Linux while providing the cross-platform capability that many consultants need. As companies migrate to Linux for their desktops, products such as Rekall will come into far greater demand.
Configuring PostgreSQL
As it is configured after a default installation, PostgreSQL 8.0.2 authenticates its users by checking their Linux identities. To create a more secure application, you should change this to password authentication. The following steps describe how to do so.
First, modify the password of the database user postgres so that you can log in when passwords are required:
At a command prompt, type su and enter your root password.
Then, type su postgres.
Now, start the psql monitor by typing psql template1.
We modify the password by typing alter user postgres with password 'pgUser89' or some other suitable password.
Exit the monitor by typing \q and pressing Enter.
Second, modify the pg_hba.conf file so that the database accepts md5 passwords for all connections. By default, it's configured to authenticate based on the identity of the current Linux account. On a default installation, this file is found under /var/lib/pgsql/data. This file has lines that look like this:
# "local" is for Unix domain socket connections only local all all trust # IPv4 local connections: host all all 127.0.0.1/32 md5 # IPv6 local connections: host all all ::1/128 md5
To enable passwords, change the trust option on the line for local to md5 and save the file. Then, restart PostgreSQL. On a Red Hat-like system, this can be done by issuing the command /sbin/service postgresql reload.
After this is done, users and databases can be created by using PostgreSQL's built-in tools or by using third-party tools such as PgAdminIII. The PostgreSQL Web site always is the best resource for more information on these topics.
Resources for this article: /article/8271.
Joshua Bentham will graduate soon from Capital University in Bexley, Ohio, with a BA in Philosophy. He has been using Linux since kernel version 1.2.8. His Weblog can be found at www.globalherald.net/jb, and he can be reached at jb42@globalherald.net.

