
Fd.o: Building the Desktop in the Right Places
End users care only about applications that perform the desired tasks. They come to Linux to have the freedom to pick up these applications one by one. To them, integrated desktop means the freedom to choose any mix of programs and the assurance that they work together. A monolithic desktop environment can limit programmers as well. Making sure that your code cooperates with existing applications is essential to good software, if not the main characteristic that makes it useful. Being forced to use one or two development toolchains to achieve this result makes much less sense.
A sore spot of the GNU/Linux desktop used to be XFree86—development progressed too slowly and performance was not satisfying. Many tools, from fontconfig to zlib, were duplicated to avoid external dependencies. If one driver changed, the whole package had to be released again. On top of all this, the XFree86 license changed last year to one that appeared to prohibit GPL programs from linking to any of the new code. Several distributions immediately reacted by not shipping the new version with the license problem.
Freedesktop.org (FD.o) was formed in March 2000 to help developers solve the technical problems outlined above. The goal of this project is to create a base platform upon which every desktop can build. The method is to define independent specifications, complete with working code where needed. Formal standardization is left to other bodies. Following these specs should guarantee real interoperability among applications as early as possible during their development, ideally before it starts. All software will be placed under LGPL or X-style licenses. FD.o hosts a lot of neat projects, but this article introduces the main tools constituting the so-called FD.o platform.
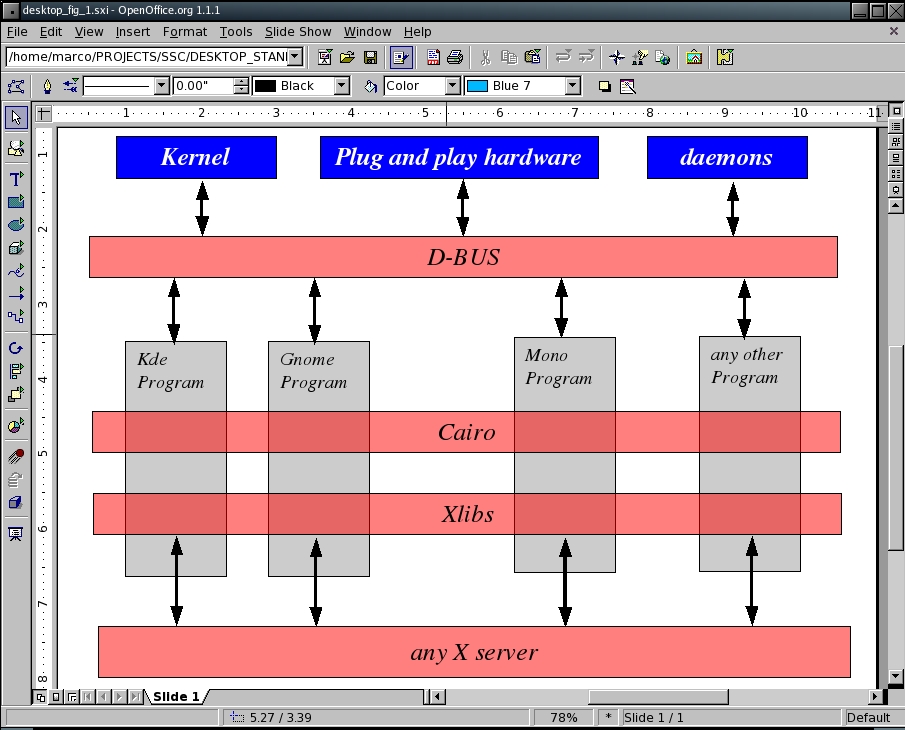
Figure 1. Integration the Freedesktop.org way: servers, libraries and communication protocols that all applications can use, no matter which desktop environment they were born in.
The X Window System is a network transparent protocol for graphical display. GUI programs use X to give drawing commands to the software, called the X server, which actually controls the screen. Until last year, servers and libraries usually were found in monolithic packages. FD.o broke that bundle into parts, however, that now can be developed and packaged separately. The main advantage of this is that programmers and Linux distributions can mix and customize, at will, different implementations of each piece.
Other X improvements include the removal of all in-tree dependencies and the use of autotools as the build system and of the iconv library for all conversions between Unicode and other encodings. The libraries wrapping the X protocol are called Xlibs. FD.o released its first version of them in January 2004. They adhere to the X standard, so they can be used with any X server.
Even after several optimizations, the size of Xlibs may create problems on low-end platforms. Furthermore, some Xlibs request block until they receive a reply, even when it is not really necessary. This can interfere with some latency reduction features in the 2.6 kernels. Xlibs also do a lot to hide the protocol, through caching, layering and similar efforts; these efforts are an advantage in many cases, an overhead in others. Last but not least, support for the creation of X extensions is limited.
The FD.o proposal to solve these problems is the X C Binding, XCB for short. This second library can be a base for new toolkits and lightweight emulation of parts of the Xlibs API. XCB is designed to work transparently with POSIX thread or single-thread programs. The code maintains binary compatibility with Xlibs extensions and applications and might not require recompilation of extensions. This makes slow, gradual migration from Xlibs to XCB easier, without losing functionality. The next step along this path, the Xlibs Compatibility Layer (XCL), should allow existing applications built on Xlibs to take advantage of XCB.
FD.o hosts two alternatives to XFree86. The first one started as a fork of the XFree86 4.4-RC2 code before the license change. This server is called X.org and is used in the same way as XFree86. The other alternative, called Xserver, is the most promising option in the long run. It is the fork of Kdrive, which started years ago as a lightweight, heavily modified version of XFree86. Kdrive is small, partly because it has less code duplication with the kernel. Size reduction also came about by removing some obsolete features and driver modules. The much smaller code size makes it easier to start from Kdrive to build a whole new server.
The version of Xserver available today still is used mainly as a testbed for new extensions and features, such as transparency or OpenGL acceleration. Memory usage is minimized by performing a lot of calculations at runtime instead of always keeping the results in memory.
The goal of Xserver is to reduce slowness as well as the other phenomena that make looking at a screen unpleasant, including flickers. A new X extension, called Composite, allows double buffering of the entire screen. Of course, no server can be smarter than its dumbest client, but the lighter architecture should make it easier to find and fix slow code, wherever it is. The new server makes no impact at the toolkit level, except when the programmer chooses to take direct advantage of the new extensions.
Vector graphics create an image by drawing more or less complex lines and filling in the resulting areas with colors. The corresponding files are small in size and can be scaled at any resolution without losses. Consequently, this technique is interesting for everybody who wants to be sure that what they print is what they see. Unfortunately, X knows how to manage screen pixmaps of text, rectangles and such, but it simply ignores printing or vector graphics. This is one of the reasons why we still do not have 100% consistency between screen, paper and saved files.
The FD.o solution is Cairo, “a new 2D vector graphics library with cross-device output support”. In plain English, this means the result is the same on all output media. Externally, Cairo provides user-level APIs similar to the PDF 1.4 imaging model.
Through different back ends, Cairo can support different output devices. The first one is screens, through either Xlibs or XCB, and in-memory image buffers, which then can be saved to a file or passed to other applications. PostScript and PNG output already is possible, and PDF is planned. OpenGL accelerated output also will be available through a back end called Glitz. In addition, it will be possible to use Glitz as a standalone layer above OpenGL. Cairo language bindings exist for C++, Java, Python, Ruby and GTK+.
The developers of OpenOffice.org also are planning to use Cairo after version 2.0 of the OOo suite is released, possibly even as a separately downloadable graphics plugin. Still being in active development and minus a completely stable API, Cairo is not included yet in official FD.o platform releases.
D-BUS is a binary protocol for Inter Process Communication (IPC) among the applications of one desktop session or between that session and the operating system. The second case corresponds to dynamic interactions with the user whenever new hardware or software is added to the computer. The internals of D-BUS were discussed by Robert Love in “Get on the D-BUS” in the February 2005 issue of Linux Journal. As far as the desktop end user is concerned, D-BUS should provide at least the same level of service currently available in both GNOME and KDE. To achieve this, both a system dæmon called message bus and a per-user, per session dæmon are available. It also is possible for any two programs to communicate directly by using D-BUS, to maximize performance. For the same reason, because the programs using the same D-BUS almost always live inside the same host, a binary format is used instead of plain XML.
The message bus dæmon is an executable acting like a router. By passing messages instead of byte streams among applications, the dæmon makes their services available to the desktop. Normally there are multiple independent instances of this dæmon on each computer. One would be used for system-level communications, with heavy security restrictions on what messages it can accept. The others would be created for each user session, to serve applications inside it. The systemwide instance of D-BUS can become a security hole: services running as root must be able to exchange information and events with user applications. For this reason, it is designed with limited privileges and runs in a chroot jail. D-BUS-specific security guidelines can be found on the Fd.o Web site (see on-line Resources).
Most programmers do not need to talk to the D-BUS protocol directly. There are wrapper libraries to use it in any desired framework or language. In this way, everybody is able to maintain his or her preferred environment rather than learning or switching to a new one specifically for IPC. End users, again, receive gains in interoperability: KDE, GNOME and Mono programs will be able to talk to one another, regardless of toolkit. As with Cairo, the first versions of the FD.o platform don't include D-BUS, because its API is not stabilized yet. But, the developers consider D-BUS to be a cornerstone of future releases. D-BUS also is meant to replace DCOP in KDE 4.
Only time will tell if the first implementations of Fd.o are good enough and if the related specifications are valid. In this context, valid means something complete that can be re-implemented from scratch with totally new code, if one feels like doing so. I am convinced, however, that the approach is valid and has more potential than any other “complete desktop” already existing.
The two most frequent complaints I've read so far are 1) the current desktops would lose their identities, becoming “only user-interface stuff” and 2) FD.o is not standards, simply other implementations. My personal response to the first concern is, even if it happened, would it really be a problem? Most end users wouldn't even realize it, nor would they be concerned at all. They most likely would note the improvements I mentioned at the beginning and be done with it. Making sure that all applications can cooperate, no matter how they were developed, also would make Linux much more acceptable as a corporate desktop, shutting up a whole category of arguments in favor of proprietary solutions.
If protocols and formats stop being tied to specific implementations or toolkits, they can be shared across multiple “desktop environments”. Code stability and lightness would directly benefit from this, as would innovation. Completely new programs could interact immediately with existing ones. I therefore hope that this trend is generalized and that more application-independent standards are submitted to FD.o, covering file formats, sound schemes, color and tasks settings. Imagine one mail configuration file that could be used by any e-mail client, from Evolution to mutt, or one bookmark file usable by every browser from Mozilla to Lynx.
As far as the second objection goes—FD.o is not standards, simply other implementations—that's exactly how free software and RFC work. As long as specifications are written alongside the code, concepts can be validated in the field as soon as possible. For the record, this same thing currently is happening with OO.o and the OASIS Office standard (see LJ, April 2004). The file format started and matured inside StarOffice and OO.o, but now it has a life of its own. The committee currently includes representatives from KOffice, and any future office suite can use it as its native format, starting only from the specification.
Some traps do exist along this path, but as far as I can tell, the developers are aware of them and determined to avoid them. The first risk is to develop standards that for one reason or another work well only on Linux, leaving out the other UNIXes. The other is resource usage: all the magic described here would look much less attractive if it required doubling the RAM to run smoothly. As far as we know today, however, this seems to be an unlikely possibility. In any case, this is the right moment to join this effort. Happy hacking!
Many thanks to Waldo Bastian, Keith Packard, Daniel Stone and Sander Vesik for all their explanations.
Resources for this article: /article/8135.
Marco Fioretti is a hardware systems engineer interested in free software both as an EDA platform and, as the current leader of the RULE Project, as an efficient desktop. Marco lives with his family in Rome, Italy.

