
Event-Driven Programming with Twisted and Python
In the beginning, there were forking servers and then came threaded servers. Although they manage a few concurrent connections well, when network sessions reach into the hundreds or even thousands, forking and threading servers spawn too many separate, resource-consuming processes to be efficient. Today, there is a better way, asynchronous servers. A new breed of frameworks for third-generation languages is taming the once complex world of event-driven programming.
A rising star in the Python community has been Twisted, which makes asynchronous programming simple and elegant while providing a massive library of event-driven utility classes. In this article, I discuss asynchronous event-driven programming and how it's done in Twisted. Because reading about code only gets you so far, I cite examples from a real Twisted application developed for this article: a simple proxy server that blocks unwanted cookies, images and connections. Instructions on how to get the complete source code are in the on-line Resources.
The Twisted Project has been gaining popularity as a powerful and increasingly stable way of implementing networked applications. At its core, Twisted is an asynchronous networking framework. But unlike other such frameworks, Twisted boasts a rich set of integrated libraries for handling common protocols and programming tasks, such as user authentication and even remote object brokering. One of the philosophies behind Twisted is breaking down traditional separations among toolkits, as the same server that serves Web content could resolve DNS lookups. Although the package itself is quite large, applications need not import all the components of Twisted, so run-time overhead is kept to a minimum.
As with Python, Twisted's user base has been expanding from its academic roots to the commercial and government sectors. At Zoto, we're using Twisted in a distributed photo storage and management application, because it enables us to develop scalable network software quickly in a famously productive language, Python. Programming day to day, I appreciate Twisted for its impressive toolkit and supportive community. And as with all community-oriented open-source projects, Twisted is a safe business bet, because its existence doesn't hinge on the continued support of any single company or institution.
Have you ever been standing in the express lane of a grocery store, buying a single bottle of water, only to have the customer in front of you challenge the price of an item, causing you and everyone behind you to wait five minutes for the price to be verified? Plenty of explanations of asynchronous programming exist, but I think the best way to understand its benefits is to wait in line with an idle cashier. If the cashier were asynchronous, he or she would put the person in front of you on hold and conduct your transaction while waiting for the price check. Unfortunately, cashiers are seldom asynchronous. In the world of software, however, event-driven servers make the best use of available resources, because there are no threads holding up valuable memory waiting for traffic on a socket. Following the grocery store metaphor, a threaded server solves the problem of long lines by adding more cashiers, while an asynchronous model lets each cashier help more than one customer at a time.
This isn't to say there aren't benefits to a threaded model. For instance, with microthreads, the amount of resources used by any particular thread is reduced substantially. There's an inherent complexity in asynchronous programming, especially when you need to do many blocking operations in succession. In Python, however, the benefits of threading are diminished by Python's Global Interpreter Lock (GIL). Threaded programming in Python is refreshingly simple, because all internal Python operations are thread-safe. To add an item to a list or set a dictionary key, no locks are required, so as to avoid race conditions among threads. Unfortunately, this is implemented through an interpreter-wide lock that Python's interpreter uses liberally. So, although two threads safely can append to the same list at the same time, if they're appending to two different lists, the same lock is used. Because threaded Python applications suffer a resulting performance hit, asynchronous single-thread programming is all the more desirable for a language such as Python.
Let's start with a simple example of a server that accepts connections on port 1100. For each connection, it sends the UNIX time and closes the socket.
Listing 1. This simple Twisted server sends the time and then closes the socket.
import time
from twisted.internet import protocol, reactor
class TimeProtocol(protocol.Protocol):
def connectionMade(self):
self.transport.write(
'Hello. The time is %s' % time.time())
self.transport.loseConnection()
class TimeFactory(protocol.ServerFactory):
protocol = TimeProtocol
reactor.listenTCP(1100, TimeFactory())
reactor.run()
Addressing the complexity of handling multiple sessions with one thread is at the core of a framework such as Twisted. Network sessions are represented by subclasses of the twisted.internet.protocol.Protocol class, such that each Protocol instance represents a network session. These objects are spawned by Factory objects, which inherit from twisted.internet.protocol.Factory. A singleton, twisted.internet.reactor, handles the dirty work of polling sockets and invoking events. Calling reactor.run() in Twisted simply starts the event loop, and run() exits when the application finishes, the same as an event loop in GTK or Qt.
Our proxy server has two kinds of networked chat sessions: incoming HTTP requests and their respective outgoing proxies. Because HTTP is a chat-like protocol, we can inherit our protocol class from Twisted's LineReceiver, which subclasses Protocol while providing extra functionality useful for chat sessions, such as HTTP. Twisted actually includes classes specifically for making and handling HTTP requests. We are writing our own in part because Twisted's prefab classes don't facilitate proxy serving and also because it's a good programming exercise for this article.
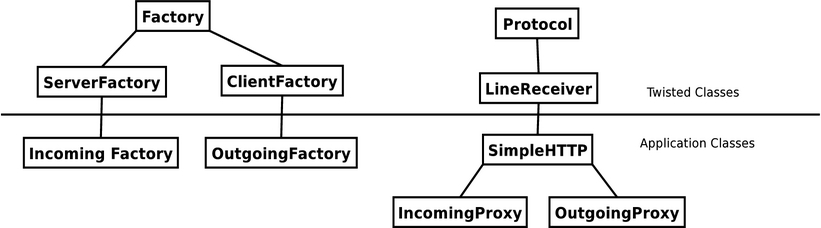
Figure 1. Class diagram for a proxy server. The Protocol classes handle individual connections while the Factory classes create them.
Refer to Figure 1 for the class structure we are going to use. Instances of the Factory classes are used by Twisted to spawn off Protocol instances for each connection made. We create one SimpleHTTP class and inherit from it classes for managing incoming and outgoing traffic. Because HTTP is mostly the same for client and server, we can manage most of the lexical processing in one superclass and let subclasses do the rest, which is exactly how Twisted's own HTTP classes work.
Operations you'd otherwise do with one or two methods tend to require several callback methods in event-driven programming. The rule of thumb is, any time there's a blocking operation you need to wait on, it happens outside your code and, therefore, between two of your methods. In the case of our proxy server, we can break down into separate chunks each part of handling a request. Most of what a proxy server does amounts to reading in data from a browser, making a few changes to that data and sending the modified data to the remote Web server. As of HTTP/1.1, multiple Web hits can be handled over one network connection. In Figure 2, you can see what happens to each request, keeping in mind that multiple requests can be made per HTTP connection. Arrows connecting boxes show which events are spawned and in what order.
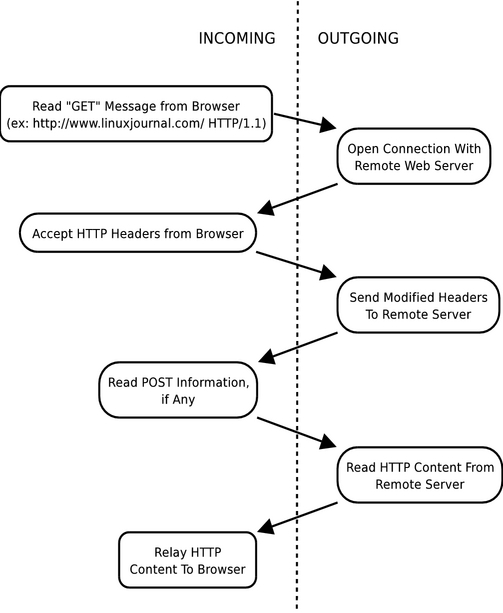
Figure 2. Overall Steps in Processing Proxy Hits
In a blocking program, one might expect to handle opening a remote connection and sending it a line of text like this:
connection = socket.open(remote_server, remote_port) connection.write(get_string) response = connection.readline()
We've all seen this kind of blocking code before, so what is different about the Twisted way? Because we don't want to wait around for the connection to be made in an event-driven program, we simply schedule some code to run when the remote server gets back to us. In Twisted, this kind of deferment is handled by using an instance of the twisted.internet.defer.Deferred class as a placeholder for the result you would expect from a blocking operation. For example, in our proxy server, we accept a Deferred object when we initiate a remote connection (Listing 2).
Listing 2. Deferring operations in Twisted are like putting them on hold until a blocking operation gets back to us.
d = self.outgoing_proxy_cache.getOutgoing(
host, int(port))
d.addCallback(self.outgoingConnectionMade, uri)
d.addErrback(self.outgoingProxyError, uri)
The self.outgoing_proxy_cache.getOutgoing method initiates an outbound proxy connection. It doesn't wait, however, for the connection to be made to return to the caller; it returns immediately. The behavior of all methods to return as soon as possible is what makes a single-threaded server possible. Any and all CPU time taken by a method is spent processing, not waiting for external things to happen.
Notice how as a replacement for the connection object itself, a Deferred object is returned. By calling addCallback and addErrback on the Deferred object, we are scheduling future events to be fired, such that when an outbound connection is ready, the self.outgoingConnectionMade method is called. By passing uri as a second argument to addCallback, we are telling Twisted that self.outgoingConnectionMade also should be called, with uri as an additional argument.
In the event of an error, self.outgoingProxyError is called with a Failure object, which brings us to error handling. Python's traditional error handling is done through exceptions, a concept familiar to other high-level languages, such as Java (Listing 3).
Listing 3. Traditional Error Handling in Python
try:
(offending code)
except ValueError:
(error handling code)
except MyError:
(error handling code)
Although Python's model of exception handling works exceptionally well (pun intended) for synchronous designs, it does not take into account asynchronous design. For example, when we initiate an outbound HTTP connection, Twisted continues processing other events while the connection is made. But, we want to specify behavior to address any problems that may occur at the time we request the connection. Fortunately, the good people making Twisted took this into account. Just as code is scheduled to run when a blocking operation completes successfully, it also can be scheduled to run in case of an error.
Twisted also handles all exceptions raised within the event loop, with hooks for developers to manage and log exceptions. This has an added benefit too: although an exception might abort a specific event from completing, it does not bring down the server, even if you haven't put any exception-handling code in place.
When using some of the Twisted classes, such as the LineReceiver class we're using, you can handle many events simply by adding methods with the correct names to your classes. Each time the protocol receives a line, the lineReceived method is invoked with the text of the line as an argument. Our SimpleHTTP class, which is intended to do minimal processing of an HTTP session, has methods such as these:
startNewRequest: invoked at the beginning of each request.
lineReceived: designed to facilitate chat-oriented protocols. Each time a line of text comes over the socket, this method automatically is called.
rawDataReceived: when sending a binary file or raw streams of data, it isn't reasonable to process information separated by newline characters. To account for this, LineReceiver lets us switch to raw mode transfer, in which case rawDataReceived is called instead of lineReceived.
handleFirstLine: HTTP works by starting each request with a single line. Generally, the client is sending a GET or POST request with a URI, and the server responds with a status code. handleFirstLine is used to handle either of these cases.
handleHeadersFinished: invoked when HTTP headers are sent fully.
handleRequestFinished: invoked when the HTTP request itself has completed.
Writing separate methods for states or actions that occur in the processing of a protocol is how Twisted programmers queue up events. At the beginning of a request, we can specify events to occur at each stage of handling a request. In our earlier example, we decided to call self.outgoingConnectionMade once a connection has been made. Let's take a look at that method, as shown in Listing 4.
Listing 4. Scheduling Events in Twisted
def outgoingConnectionMade(self, outgoing_proxy,
uri):
"""
This occurs when our outbound proxy has
connected. It's a Twisted callback method.
"""
assert(outgoing_proxy, OutgoingProxy)
self.outgoing_proxy = outgoing_proxy
outgoing_proxy.incoming_proxy = self
# Send HTTP command and echo back result
outgoing_proxy.write('%s %s %s' % \
(self.http_command,
uri,
self.http_version) \
+ self.delimiter)
outgoing_proxy.firstline_sent_def.addCallback(
self.outgoingFirstlineReceived)
# Send anything we have queued.
self.flushOutgoingBuffer()
# Add callbacks for when headers are ready
outgoing_proxy.headers_finished_def.addCallback(
self.outgoingHeadersReceived)
outgoing_proxy.request_finished_def.addCallback(
self.handleOutgoingRequestFinished)
Notice that outgoing_proxy represents the connection we are making to a remote server, on behalf of the Web browser we are serving. We're sending the HTTP request by calling outgoing_proxy.write. We're also scheduling the self.outgoingFirstlineReceived method to be called when a response is received from the remote server. The self.outgoingHeadersReceived method is called when the remote server has sent back all of its HTTP headers. Finally, self.handleOutgoingRequestFinished is called when the remote server has finished entirely responding to our outgoing HTTP request.
Although the outgoingConnectionMade method returns before any of this happens, we're lining up events to happen in the future. It well may be that while waiting for a response on one connection, ten other requests are opened and closed—all in the same thread. All information relevant to a connection is stored as instance data on protocol classes. Factories spawn protocol instances, protocol instances keep session states and deferred objects bind future data to event handlers. Completing the puzzle, the reactor manages the dirty work of polling sockets. This is the combination of tools upon which Twisted is built.
You can download for tinkering all 606 lines of the proxy server discussed in this article. Although I wouldn't put the company intranet behind it, I've been using it for a week now to filter out unwanted cookies and images and even to block access to a certain vendor from my desktop. When I started using Twisted, it was easy to wrap my head around the concept of asynchronous programming, a little harder to figure out how to map events to the flow I wanted and harder still to explain it to someone else. Do not be discouraged, however. Although we at Zoto started with almost no Twisted knowledge, we've built a fully functional and extremely scalable clustered application to store and manage on-line photos in less than a year, with only one person (me) working full-time on the server.
Of course, Twisted is not for everyone. Its vastness, although powerful, can be intimidating. For a simple asynchronous chat server in Python, take a look at Medusa. Like Twisted, Medusa organizes asynchronous programming into Factories (called Dispatchers) and chatting classes.
Resources for this article: www.linuxjournal.com/article/7963.
Ken Kinder is currently developing a clustered Twisted server for Zoto in Oklahoma City, Oklahoma. He enjoys hiking, skiing, photography and (of course) Linux. His hometown is Boulder, Colorado.

