
Paranoid Penguin: Taking a Risk-Based Approach to Linux Security
Since I started writing this column four years ago, the nature of Linux software vulnerabilities and threats hasn't changed that much. Buffer overflows, bad configurations (including file permissions) and inadequate input validation still form the lion's share of Linux vulnerabilities. If the same kinds of vulnerabilities keep cropping up, is the whole patch rat race futile? Or, is there a broader approach to Linux security that we can adopt?
This month, I discuss Linux security from a risk-based perspective and illustrate how by using the risk-based approach we can mitigate not only the Linux vulnerabilities we know about, but the ones nobody's discovered or publicized yet.
You may be wondering, what do I mean by a risk-based approach? Isn't all information security about risks? Indeed it is, but this term is actually short for risk management-based approach.
There are only a few ways to handle a given information security risk. We can avoid it by not doing anything that exposes us to that risk. We can eliminate it by addressing its root cause (which is, in practice, seldom within our control). We can mitigate it—that is, do something that lessens the impact of the risk in some way. Or, we can accept it.
One school of thought, now thankfully obsolete, holds that security is a binary equation: things either are secure or stupid, and if one judges a given activity or tool as not being secure, one simply should not do that thing or use that tool. In other words, in this school of thought, risk avoidance is the preferred approach to security.
As most of us acknowledge nowadays, however, absolute security does not exist. No magic combination of software choices, software/system configuration or network topology can make us invulnerable to security breaches. No combination, that is, that you actually can do any work with. Risk in some quantity or another is inevitable in networked computing.
The risk management-based approach to security acknowledges the need to seek balance between risk avoidance, risk mitigation and risk acceptance, by prioritizing risks based on their likelihood and potential impact. Risks that are both likely to occur and expensive to recover from are tagged as being the most important risks either to mitigate or avoid. Risks that either are highly unlikely or extremely cheap to recover from become reasonable candidates for risk acceptance. By the way, when I talk of the cost or impact of a risk occurring, I mean not only monetary cost but also lost time, reputation and productivity.
Figure 1 shows the general relationship between a risk's likelihood, its cost and its acceptability. The precise shape of the curve that defines the acceptable risk and unacceptable risk zones will vary from organization to organization. A financial institution, for example, will tend to have a much bigger red zone than a university network.

Figure 1. Risk Thresholds
Thus, to take a risk-based approach to security is to acknowledge that not all risks are created equal, and therefore, you must choose your fights. To do so effectively, however, requires you to be creative and honest in identifying and assessing the risks in a given undertaking. Denying a risk exists is far more dangerous than acknowledging and accepting that risk and making recovery plans should the worst occur.
This brings up another important aspect of the risk-based approach: risk acceptance should not mean complacency. Any risk that can't be avoided or mitigated must at least be taken into consideration in business continuation and recovery plans. Furthermore, very few information security risks can't be mitigated in some way or another; many types of risks can't be eliminated but can nonetheless be contained or attenuated.
Okay, so Linux security is best handled with a risk-based outlook. What does that look like? Step one is to think about known and potential vulnerabilities in your Linux system. Most of Linux's application and system vulnerabilities fall into one of these categories:
Buffer-overflow vulnerabilities (inadequate bounds checking).
Poor input validation.
Inappropriate file permissions.
Inappropriate system privileges (avoidable use of root).
Sloppy configuration.
Insecure use of temporary files.
Predictable or known default passwords.
Administrative back doors (test or debug accounts).
The first vulnerability in this list, buffer overflows, is arguably the scariest. Buffer overflows frequently lead directly to remote root compromises. Like buffer-overflow conditions, many of these vulnerabilities are the direct result of programming errors such as insecure use of temporary files and administrative back doors. Others are more typically user-inflicted by predictable passwords or sloppy configuration.
No vulnerability, however, actually constitutes a threat unless someone attempts to exploit it. In other words, a threat equals a vulnerability plus an attacker.
Step two is to think about ways that these vulnerabilities might be exploited. Although Linux vulnerabilities haven't changed much over the years, the actors who attempt to exploit them have. They've become both more effective and dumber. The scary truth is, easy availability of exploit code and scripts has made it increasingly easy for unskilled attackers to conduct increasingly sophisticated attacks.
For example, traditionally, conducting a buffer-overflow attack has required considerable programming skill—besides being able to determine where in memory the overflowed data will end up, the attacker must write or procure exploit code, or shellcode written in assembler code specific to the target system's architecture, such as i386 or SPARC. Shellcode is the code that gets overflowed and executed, resulting in a shell, ideally with root privileges, on the target system.
In olden times, the difficulty of identifying offsets and writing working shellcode narrowed the field of potential buffer-overflow attackers considerably. Nowadays, however, if you want to exploit a well-known buffer-overflow vulnerability, all you need to do is perform the right type of Google search to obtain exploit tools, each complete with shellcode for a variety of target systems.
People who write exploit scripts and publish them on the Internet are a big enough problem. But they're not the only actors in the threat equation; if you're the kind of person who enjoys arming script kiddies, it's only a little more work to automate the exploit completely and package it up into a worm or virus.
Viruses, of course, can't propagate themselves; they're always embedded within something else, for example, e-mail attachments or executable files. Worms, which propagate themselves, are much scarier—they're essentially viruses with wings. In fact, if you were to watch your log files during a worm attack, you'd have a hard time distinguishing it from an attack conducted by a human being. A worm is sort of an attack robot.
Thus, attackers either can be humans or pieces of software. The good news is, because they exploit exactly the same sorts of vulnerabilities, the defenses are the same for each. The bad news is, attack scripts, worms and viruses have shortened exponentially the amount of time you've got between the time a vulnerability is discovered and publicized and the time your system probably will be probed for that vulnerability by an attacker.
Now, let's begin matching these threats with defenses. This is where the risk-based approach becomes really important.
If you take an absolutist view of security, defense is simple. You choose software based not on the best combination of functionality, supportability and security, but solely based on security. Because security is your main software criterion, all you need to do is keep it patched, and all is well.
You probably also configure your firewall to trust nothing from the outside and to trust everything originating from the inside, because, of course, all outsiders are suspect and all insiders are trustworthy. In fact, software patches and firewall rules are so important in this view that practically nothing else matters.
And indeed, software patches and firewalls are important. But the degree to which we depend on patches and the way we use firewalls is somewhat different if we take the trouble to think about the real risks they're meant to address.
Consider the scenario I've sketched out in Figure 2. A firewall protects a DMZ network from the outside world, and it protects the internal network from both the outside world and the DMZ.
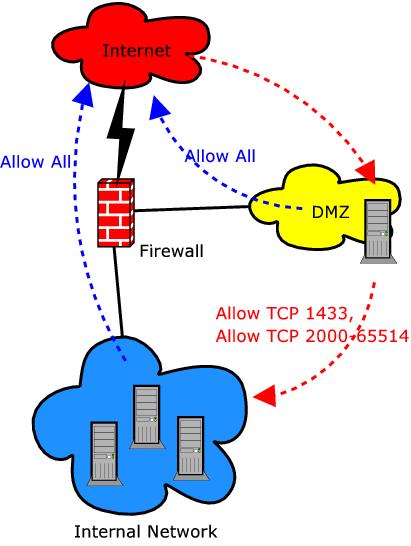
Figure 2. Simple Firewall Scenario
The firewall rules, shown in Figure 2 by the dotted lines, might look like this:
Allow all Internal hosts to reach the Internet via any port/protocol.
Allow all DMZ hosts to reach the Internet via any port/protocol.
Allow all Internet hosts to reach the DMZ via TCP port 80 (HTTP).
Allow the DMZ Web server to reach Internal hosts via TCP ports 1433 and 2000–65514.
On the face of it, this might seem reasonable enough. Internal users need to do all sorts of things on the Internet, so restricting that access is a hassle. The DMZ needs to do DNS queries for its logs, so why not give it outbound Internet access too? And there's a back-end application the DMZed Web server needs to access on the internal network that involves a database query on TCP 1433 plus a randomly allocated high port that falls within some finite range nobody's managed to document. So, the easiest thing to do is open up all TCP ports higher than 1999.
But let's consider three plausible risks:
Internet-based attacker compromises Web server and uses it to attack other systems on the Internet.
Worm infects internal system via an RPC vulnerability, and the infected system begins scanning large swaths of the Internet for other vulnerable systems.
Worm infects the internal system and starts backdoor listener on TCP 6666. Attacker compromises Web server, scans firewall, detects well-known worm's listener and connects to the internal system.
In the first risk scenario, we've got an obvious legal exposure. If our Web server is compromised, and our firewall isn't configured to restrict its access to the outside world, we may be liable if the Web server is used to attack other systems. Restricting the Web server's outbound access only to necessary services and destinations mitigates this risk. In practice, a typical DMZed Web server should require few if any data flows to the outside world—its job is responding to HTTP queries from the Internet, not initiating Internet transactions of its own.
In the second scenario, we have a similar exposure, though the network performance ramifications are probably greater than the legal ramifications (all that scanning traffic can clog our Internet uplink). Again, a more restrictive firewall policy around outbound access trivially mitigates this risk.
The third scenario may seem a little more outlandish than the others—what are the chances of a worm infection on the inside and a Web server compromise in the DMZ both happening at once? Actually, they don't have to occur simultaneously. If the worm sets up its backdoor listener on TCP 6666 but then goes dormant, it may not be detected for some time. In other words, the Web server's compromise doesn't need to occur on the same day, or even in the same month, as the worm infestation if the infected system isn't disinfected in time. As with the other two scenarios, a more restrictive firewall policy mitigates this risk and minimizes the chance of the internal worm infestation being exploited by outsiders.
Besides being mitigated by more restrictive rules, these three risks have another important commonality. You don't need to predict any of them accurately to mitigate them. Rather, it's enough to think “what if my inbound firewall rules fail to prevent some worm or virus from getting in, and unexpected types of outbound access are attempted?”
I can't stress strongly enough that it's important not to focus exclusively on attack prevention, which is what inbound firewall rules do. It's equally important to think about what might happen if your preventative measures fail. In information security, pessimism is constructive, not defeatist.
I also hope it's clear by now that my point isn't that firewall rules are the answer to all your Linux risks. The point is that effective firewall rules depend on you considering not only known threats, but potential threats as well.
So, if firewalls aren't the panacea, what else must we do? Earlier in this column, I identified sloppy configurations as a major category of vulnerabilities; the flip side of this is that careful configurations are a powerful defense.
Suppose I've got an SMTP gateway in my DMZ that handles all e-mail passing between the Internet and my internal network. Suppose further that my organization's technical staff has a lot of experience with Sendmail and little time or inclination to learn to use Postfix, which I, as the resident security curmudgeon, consider to be much more secure. Management decides the gateway will run Sendmail. Is all lost?
It doesn't need to be. For starters, as I've stated before in this column, Sendmail's security record over the past few years actually has been quite good. But even if that changed overnight, and three new buffer-overflow vulnerabilities in Sendmail were discovered by the bad guys but not made known to the general public right away, our Sendmail gateway wouldn't necessarily be doomed—thanks to constructive pessimism on the part of Sendmail's developers.
Sendmail has a number of important security features, and two in particular are helpful in the face of potential buffer overflow vulnerabilities. Sendmail can be configured to run in a chroot jail, which limits what portions of the underlying filesystem it can see, and it can be configured to run as an unprivileged user and group, which minimizes the chances of a Sendmail vulnerability leading directly to root access. Because Sendmail listens on the privileged port TCP 25, it must be root part of the time, so in practice Sendmail selectively demotes itself to the unprivileged user/group—this is a partial mitigator, not a complete one.
Being chroot-able and running as an unprivileged user/group are two important security features common to most well-designed network applications today. Just as a good firewall policy aims for both prevention and containment, a good application configuration also takes into consideration the possibility of the application being abused or hijacked. Thus, the true measure of an application's securability isn't only about the number of CERT advisories it's been featured in, it also must include the mitigating features natively supported by the application.
The risk-based approach to security has two important benefits. First, rather than always having to say no to things, security practitioners using this approach find it easier to say “yes, if” (as in, “yes, we can use this tool if we mitigate Risk X, contain Risk Y” and so on). Second, by focusing not only on prevention of known threats but also by considering more generalized risks, the risk-based approach fosters defense in depth, in which layered controls minimize the chances of any one threat having global consequences (firewall rules plus chrooted applications plus intrusion detection systems and so on).
I hope you've found this discussion useful, and that it's lent some context to the more wire-headed security tools and techniques I tend to cover in this column. Be safe!
Mick Bauer, CISSP, is Linux Journal's security editor and an IS security consultant in Minneapolis, Minnesota. He's the author of Building Secure Servers With Linux (O'Reilly & Associates, 2002).
