
An Open-Source System for Electronic Court Filing
Over the past several years, court technology has gone through many changes. Most notable is the drive to facilitate the electronic filing of documents by using open-source solutions. Many people have led separate projects that attempted to provide a blueprint for proper electronic integration with court case management systems (CMSes). To date, large-scale success has not been demonstrated in the legal electronic filing industry, although many small projects have shown promise. All of this may be about to change, however, as the federal and state court systems start to embrace and support open-source software.
Each year, approximately 90 million cases are filed in the 17,500 courts in the United States. These cases generate more than 1.5 billion documents. Aside from the environmental impact, this creates a mountain of paperwork for court staffs. In addition, storage and indexing costs associated with archiving and retrieving documents are high. Many courts are starting to look toward integrated electronic systems to cut down on the quantity of paperwork and streamline day-to-day operations. Most courts now use some form of computer-based case management system or document management system (DMS).
The idea behind electronic court filing is to allow lawyers and the general public to submit documents to the court over the Internet. Law firms already generate an electronic version of any document they plan to file with a court. When filed electronically, the document automatically is placed in a DMS, and the pertinent case information is placed in a CMS.
The current accepted model of how filings should be generated and passed to a court involves three major components. The first is an electronic filing service provider (EFSP), the organization responsible for constructing an electronic legal filing. There could be many of these organizations in any given legal jurisdiction, all competing for a per-filing fee paid by lawyers and pro se litigants (people who represent themselves in court) who use their service. The second component is an electronic filing manager (EFM). The EFM has a one-to-one relationship with a court. All EFSPs that offer the ability to file documents with a specific court need to communicate with that court's EFM. Court personnel use the EFM to review filed documents to ensure that any court-specific rules have been followed. The final component is an adapter that communicates between the EFM and the court's CMS and DMS systems. This adapter relays the documents and case information associated with the filing to the court's information systems. Figure 1 shows the organization of this model.
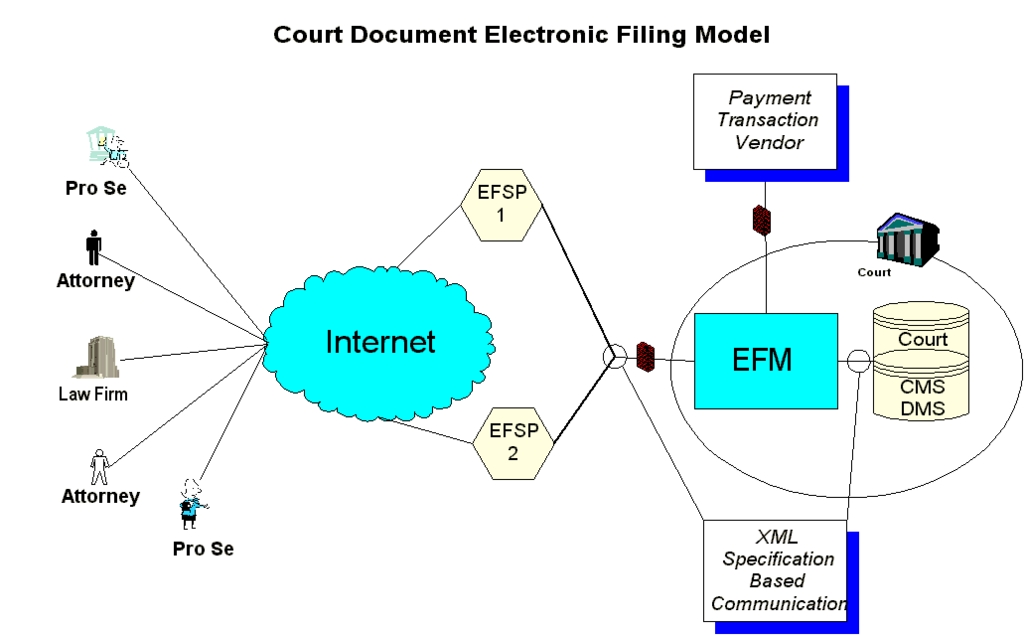
Figure 1. Transferring and Submitting Filings
A major hurdle to providing this type of functionality is that almost every CMS used by courts today has been customized on some level to fit specific needs of individual courts. Many courts even have developed their own custom solutions in-house. These differences require the EFM to CMS and DMS adapters to be rewritten for every court. In response to this problem, many court professionals have pushed for an industry-endorsed standard for transmitting data between legal systems. Winchel “Todd” Vincent III, founder of Legal XML, stated: “Having an agreed-upon specification to use can greatly reduce the amount of work required to provide complicated system integration. It allows for all involved parties to work on the problem together, instead of reinventing the wheel over and over again.” In addition to an industry standard, there also is a drive to provide an open-source EFM.
In November 1998, Legal XML was established as a nonprofit organization. The goal was to provide open, nonproprietary technical specifications for exchanging legal documents and to organize the related information. It attracted participants from private industry, other nonprofit organizations, government and academia. Legal XML originally produced a DTD-based specification, which eventually was used to help courts exchange information by way of XML.
The completeness of the Legal XML 1.0 specification was put to the test when the Georgia Court Automation Committee (GCAC) used it during an interoperability pilot project. This project acted as a proof of concept for the electronic filing approach previously described. The first standards-based electronic filings to occur in the nation were a result of this project. Filings were generated and received through systems run by different software providers, proving the feasibility of interoperability based on open standards. Both federal agencies and state courts actively followed the project.
The interoperability phase of this project consisted of three EFM installations. Two of the EFMs facilitated filings with county superior courts; the other EFM interfaced with a county state court. Three providers managed the individual EFMs. Four companies provided EFSP interfaces that were used successfully to file with all three EFMs. Between January 2003 and January 2004, more than 1,000 filings were processed electronically. The project was considered a success. Since its completion, several law enforcement agencies in Georgia now file electronically on a daily basis.
After the Georgia Interoperability project, integration challenges led to talk of an open-source solution, and the topic started to spread among the electronic filing community. The National Center for State Courts (NCSC) led the way and was one of open source's bigger proponents, releasing an open-source EFM, inCounter, using the standard Linux, Apache, MySQL, Perl/Python/PHP (LAMP) approach. inCounter was designed to be a demonstrative application to showcase electronic filing capability and to promote an open-source solution. counterclaim, Inc., the company this author works with, concurrently released OpenEFM, a 100% Java application.
Open-source software is a good technical solution to the electronic filing problem. In many open-source projects, forming an active development and support community is often difficult. However, a large number of developers currently are spread throughout courthouses across the United States. This loose-knit community can be organized within the US judicial system. These IT staffers share the same challenge of solving similar electronic filing problems. Because courts are noncompeting entities, the standard problems regarding intellectual property should evaporate in favor of collaborative community solutions.
Open source also provides a good economic solution to problems related to courthouse operational costs. Many courts are strapped for cash. Purchasing industry-specific proprietary solutions from large corporations often can be very costly. Although open-source software does not mean free software, it reduces up-front costs. Courts still incur costs associated with installing software, teaching people how to use it and customizing the open-source solution to fit their unique needs. Also, as with any software solution, ongoing maintenance is needed. Today, many large companies, in addition to selling software, also act as consultants to courts, charging large sums of money for services extolling proprietary solutions. Open-source solutions can cut these costs.
Open source is also a great benefit for court personnel, allowing them to evaluate the feasibility of a solution before making a commitment. Nothing prevents an IT technician in any court from downloading the open-source EFM code and playing with it to determine whether the software meets the court's needs. On the other hand, proprietary software often is not available for a complete evaluation until the court has committed to a contract. This can lead to problematic situations and can leave the court with little control over timelines and final costs.
The 2002 biennial eCourt Conference, hosted by NCSC, was a watershed moment, as open-source solutions were spotlighted. During the conference, counterclaim's OpenEFM and the NCSC's inCounter were demonstrated and exposed to the larger legal community. Hundreds of decision-makers from both federal and state courts all across the country, along with foreign representatives, witnessed the power of the open-source model. The information presented led to spirited discussions regarding the virtues of open source within the legal industry.
About the time of the beginning of the Georgia Interoperability pilot project, the Legal XML organization went through several changes. As with any large project, internal organizational issues existed. These issues resulted in the decision by the founder of Legal XML to leave the group. After this event, it was proposed that the Legal XML group move under the umbrella of the Organization for the Advancement of Structured Information Standards (OASIS), a not-for-profit global consortium dedicated to promoting development, implementation and acceptance of electronic business standards. The OASIS Legal XML Member Section is made up of representatives from both commercial software companies and governmental court organizations. The founder of Legal XML, Winchel “Todd” Vincent III, and Legal XML itself, both continue to provide valuable and significant contributions in the area of electronic court filing.
In October 2002, the California Administrative Office of the Courts (AOC) decided it was time to define a standard for electronic filing and data exchange for California courts. This project is called the Second-Generation Electronic Filing Specification (2GEFS). Vincent spearheads this effort, together with a group of participating software companies and selected California courts. Over the course of several months, specifications were produced by a group of knowledgeable participants. Recently, the draft XML Schema-based specifications have been made available publicly for comment by the state of California.
A unique technical aspect that the 2GEFS specifications provides is the concept of a well-defined Schema framework. This notion came from the recognition that courts may need to modify data elements slightly to fit their specific needs. An example of this might be the way a person is defined by the specification. One court may need to include such information as a list of identifiable scars, tattoos and birthmarks, whereas another court may not care to capture this information. The Schema framework approach creates a decentralized framework of strictly versioned schemas. Each schema lives in its own namespace and can be published on multiple servers. This ensures that all past versions of Schemas are available, and XML instance documents representing filings can use older Schemas to validate against as needed. This allows courts to use slightly customized Schemas and put them in their own namespace under their own control.
These specifications also are out for public comment, and several companies are working on incorporating them into court filing software. The specifications are covered under a modified General Public License. Christopher Smith, the current overseer of the 2GEFS Project, had the following to say about its success: “We're very pleased with the specifications we have produced. Aside from being easy to understand and well documented, we feel that they can be a tremendous contribution to the electronic court filing industry. We are encouraging all interested parties to see what California has to offer.”
Proof-of-concept implementations of the 2GEFS specifications have been created, and an interoperability-testing phase is scheduled to last until the middle of 2004. Throughout this project, the state of California is working with a number of local courts to integrate their electronic filing systems.
The Open XML Court Interface (OXCI) initiative was started in March 2000, but it finally got off the ground in mid-2003. Its goal is to develop an open-source version of an EFM. Eleven states have sponsored the initial development and actively take part in the OXCI consortium. The project is being led by the AOCs of Georgia and Washington State. The legal community across the country is anxiously watching the OXCI Project. In January 2004, OXCI was ready to fund development.
OpenEFM, the open-source EFM supported by counterclaim, was used as a point of reference many times by the OXCI team as they worked on an outline for the project requirements and architectural design. After submitting a response to the AOC of Georgia's Request for Proposals regarding the OXCI EFM Project, counterclaim was selected to complete the project development and to provide continuing support. The development of the OXCI EFM is slated to be complete in June 2004, after which three courts will be configured to use the new, open-source system. Once success has been demonstrated, it is likely that more courts across the US will adopt the OXCI EFM.
Vince Harris, leader of this project for the AOC of Georgia, had the following to say about OXCI: “It has taken a lot of work and effort by many different people to get us to this point, but we are excited to be here. With the amount of backing and support the OXCI Project has received, we have a great opportunity to help solve the electronic filing problem. Since the EFM will be available at no cost to the courts, we also feel that our solution has the potential to be very widespread.”
At some future point, all courts will offer some form of electronic filing. In fact, many jurisdictions have passed legislation mandating such services be made available. By educating the legal community about available open-source solutions, there is a great chance that the court community could pool its resources and come together to adopt a solution that addresses its common needs. OXCI is working to provide that open-source solution. The OASIS Legal XML Member Section is in a great position to pick and choose the best features from various specification attempts in order to provide an open industry-endorsed standard to go along with the open-source EFM. With any luck, and a whole lot of elbow grease, an open-source approach may become the standard solution endorsed by our judicial system as the best method to solve the electronic filing problem.
Resources for this article: /article/7492.
Jim Beard has worked in the court software industry for several years. He has participated in a number of different electronic filing projects and is currently involved in the OXCI and 2GEFS Projects. He can be reached at beard@counterclaim.com.
