
Constructing Red Hat Enterprise Linux v. 3
Many people have little understanding of the behind-the-scenes efforts required to construct an enterprise Linux distribution. The fact that this process largely can be taken for granted is actually a compliment. This article offers a glimpse into the methodology we used to deliver Red Hat Enterprise Linux v. 3 (Enterprise Linux v. 3). As you will see, we faced numerous challenges along the way. Then again, if it would have been easy, it wouldn't have been so much fun.
Throughout this article, the focus is on how the release was put together. This article primarily discusses the development of the kernel used in Enterprise Linux v. 3. The kernel is only a fraction of an overall distribution, the portion that controls the underlying hardware and system resources. The challenges faced by the other teams, with projects such as compiler tools, the installer, hundreds of application packages, documentation and testing, are equally daunting. Each of these items was developed by gifted individuals.
Allow me to start by noting that we here at Red Hat have established strong relationships with our key partners in the industry. Although partners' anonymity is guarded here, I'm sure they can identify where they fit in to this story and recognize that it's all in good humor.
High customer expectations have been set by the proprietary UNIX operating systems, and customers planning to migrate from UNIX to Linux do not want to adopt technology that cannot deliver the same level of robustness, quality, support and compatibility. Business users demand stability and reliability. In some cases this means bleeding-edge technology is not appropriate for inclusion in a product. Users also want the ability to run across a wide range of architectures and hardware components, thereby realizing the Linux goals of avoiding proprietary vendor lock-in. Support needs to be in the form of ongoing maintenance for several years, including security and bug fixes, as well as incremental hardware support and valuable, but not destabilizing, feature enhancements.
The ball gets rolling on a new release by identifying the targeted feature set. Next to strong opinions, the second most plentiful commodity at Red Hat is feature requests. They come from all directions, such as insatiable independent hardware/software vendors, demanding customers, both large and small, and Red Hat's worldwide sales and service support organizations. Additionally, as many ideas are generated within Red Hat engineering, ranging from performance and usability enhancements to marketing proposals on how to organize the product set.
Obviously, we don't have infinite developer resources, so the major challenge is to choose the best of these ideas. Another key feature acceptance criteria is conformance with upstream Linux direction, which is necessary for compatibility and to remain true to the spirit of the kernel.org tree governed by Linus Torvalds and containing contributions from around the world.
Here's a few examples of the challenging scenarios we face in requirements gathering:
We ask each of our partners to submit a reasonably sized top-ten list. One partner's requirements came in the form of a binder that was two inches thick. This became affectionately known as the bible. My first exposure to the bible came when it was heaved onto my desk with a resounding thud. When I saw that, I swear that my heart went thud, too.
The more mathematically inclined partners do internalize the concept of a top-ten list. However, most ended up using a tactic that those of you familiar with TCP/IP networking should recognize—the sliding window protocol. The way it works is as soon as any of your features have been accepted, those pop off the top of the stack, freeing up space for features 11, 12 and 13 to all of a sudden become cataclysmic issues.
The following is a representative example feature list from a hardware vendor:
Support more than 32GB of memory on x86.
Support more than eight CPUs.
Support for our new XYZ100 series computers. (This is a thinly veiled multiple feature request; behind it is a series of required device drivers, PCI IDs and installer hooks.)
Updated I/O adapter driver. (This ultimately turns into differences of opinions regarding to which newer version this refers).
Integrated support for the vendor's proprietary baseboard management software. (A perennial list item, which consistently gets rejected to the amazement of the requester.)
Compiler optimizations to match the latest chipsets.
USB support for our CD-ROM drive. (Needed because the drive is brain-dead and doesn't conform to the spec—of course that subtlety is absent in the initial feature request.)
Support for more than 128 disks.
Then, there's typically the following implied requirements:
All of these feature requests apply to multiple architectures, including x86, AMD64 and Itanium 2.
Oh, by the way, we also want this feature backported to the prior Enterprise Linux v. 2.1 release.
Countless external requests ask for either proprietary additions or hooks. In the open-source tradition, this is something we consistently have to refuse.
For Enterprise Linux v. 3, the initial set of requested features was about 500 items. Each of these was entered into our feature-tracking tool called Featurezilla, which actually is a derivative of the Bugzilla bug-tracking tool. Figure 1 shows several items in Featurezilla. To show that the jabs go both ways, one partner has a business manager whose name is Paul, name changed to protect the innocent. He manages a list as a text file, but back at his company, the list is referred to as Paulzilla.
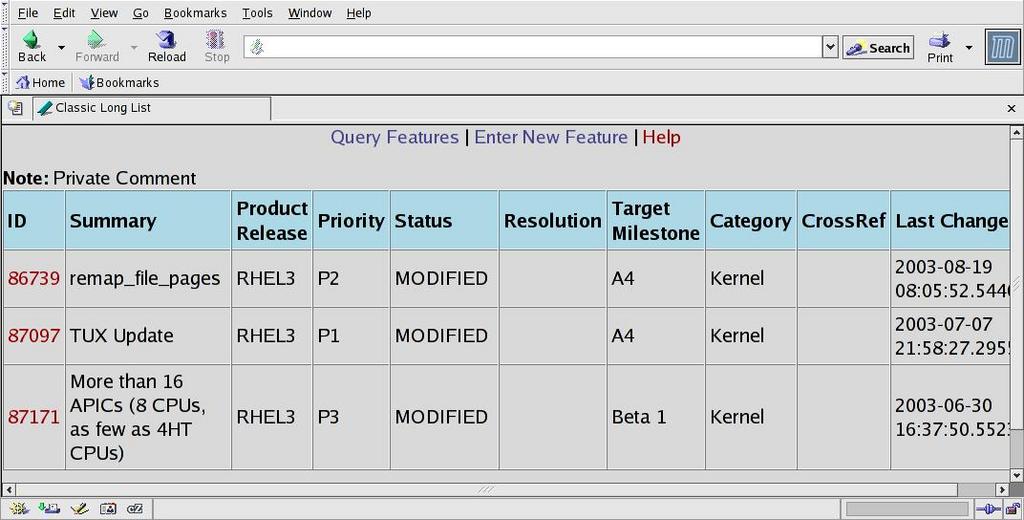
Figure 1. The feature-tracking tool Featurezilla lists feature requests and their status.
We had countless tortuous internal meetings to prioritize and slog through the full set of 500 items. From that prioritized list, the engineering managers went off to try to get the list down to a manageable set that is humanly achievable by their team members. Ultimately, the list is negotiated down to something that vastly exceeds anything reasonably achievable by the development team. But, that's the Red Hat way, and it's only the beginning of the story.
To keep things interesting, in addition to having to develop to an aggressive schedule for Red Hat Enterprise Linux v. 3 development, a large amount of effort also is required to support the Enterprise Linux v. 2.1 maintenance stream. By the time Enterprise Linux v. 3 shipped, v. 2.1 had been out for 15 months. Because we provide a five-year life cycle for releases in the Enterprise Linux family, we simply cannot dump Enterprise Linux v. 2.1 support and maintenance work. The requirements demanded by our partners in the maintenance stream form an interesting paradox. When it comes to the objectives of the maintenance stream, it seems that all partners and high-profile customers speak out of both sides of their mouth. “Don't change anything! I'm using this release in production. Don't upset the apple cart”, is followed by “I really need this feature immediately. Hurry up and give it to me, but don't put anything else in.”
Ultimately, it all boils down to a careful case-by-case risk/benefit assessment. Internally, we review features and bug-fix proposals among the engineering ranks. It is well beyond my literary abilities to convey the strong-willed and passionate debates conducted over incorporating features or bug fixes that straddle the risk/benefit fence.
Some people have the mistaken impression that Red Hat simply pulls together a random collection of bits and pieces from the upstream Open Source community, slaps the Red Hat name on it and calls it a product. Truth be told, Red Hat engineers contribute a substantial percentage of upstream (for example, 2.4 and 2.6) kernel development. The productivity, breadth of knowledge and ability to be on top of a torrent of internal and external communication demonstrated by these kernel developers is stunning. They truly are world class and humbling to be among. But don't tell them that, lest it goes to their heads.

Figure 2. Kernel developers at Red Hat, left to right: Larry Woodman, Dave Anderson and Rik van Riel.
In addition to the sizable upstream enhancements that get pulled back into the Enterprise Linux kernel, a large set of enhancements is developed in-house to meet the product requirements. As an open-source company, all of the kernel enhancements are available to the community at large. The vast majority of these changes do end up being incorporated upstream.
The kernel in Enterprise Linux v. 3 primarily is based on the 2.4.21 kernel, but it has a huge number of features backported from the more recent 2.6 kernel. In recognition that the 2.6 kernel had not yet been stabilized, only key features deemed commercially ready were candidates for the backport into Enterprise Linux v. 3. Here's a little tip on how to really annoy a Red Hat kernel developer: say something like, “So, you guys just ship the stock 2.4.21 kernel; right?”
The most daunting challenges in constructing the Enterprise Linux v. 3 kernel were the requirements that support be provided for seven different architectures and that the kernels for these architectures all must be built from a common source tree. The seven architectures include: x86 (and Athlon), AMD64, Itanium 2, IBM mainframe (both s390 and s390x) and IBM's iSeries and pSeries PPC systems. Although each of these architectures is supported by the upstream kernels in varying degrees, the reality is many of these architectures are developed primarily in isolation. This inevitably leads to integration nightmares.
Another interesting twist to the story is Red Hat's kernel development team literally is spread all over the world. Out of necessity, this has led to virtually all interaction being done on-line. For example, we rarely have team meetings, as time-zone challenges get in the way. Sometimes this on-line communication goes to extremes; it's quite common to use IRC chat sessions to speak with someone sitting at the next desk. Yes, our mothers were right; we are a bunch of geeks.
Just as the sun never sets on kernel development, our near-and-dear partners and customers don't sit still either. One of the few constants in this dynamic environment is that throughout the course of the release development, there is a steady influx of must-have crisis feature additions. We endeavor to make it a trade-off and kick out a lower priority feature in order to keep the workload sane. In the end, however, it never seems to work out to such a sweet balance. The ability of the team to persevere through all these demands is remarkable.
As productive as the Red Hat developers are, some late-breaking features always have to be deferred to a later release or update. These situations cause no end of trauma for our partner managers who have to be the bearers of bad news. It's improbable that our partners ever heard the saying “don't shoot the messenger”. There was one incident when we were two hours from shipping the release and a delivery arrived on the loading dock. It was a new computer platform we needed in order to be able to develop and test support for it. The partner was incredulous that we were unable to accommodate.
Several different levels of testing are performed throughout the development process. It all begins with the developers performing unit testing. This consists of manual, hands-on testing as well as development of automated testing programs. The set of automated tests constantly is being augmented as new problems are addressed. These automated test programs then are incorporated into a test grid that is managed by the QA department. In addition to the internally written unit tests, our test grid includes a wide range of regression tests. Examples include POSIX, LSB conformance, LTP, crashme, gcc suite and diabolical tests provided by our partners. Stress tests also are performed for a range of system functions using such tests as cerberus, lmbench, bonnie, spec and other micro-benchmarks, to name a few. These automated tests are run nightly in order to detect regressions quickly. This is critical in order to isolate the offending code. In contrast, if we waited to perform monthly base-level testing, it would be much more difficult to identify the culprit.
On top of the nightly tests, more time-consuming test scenarios are run less frequently. Examples include installation testing using a wide range of configuration options across the many different languages we support. Hands-on testing rounds out the internal QA coverage. Doing justice to the staggering range of testing done by the hardworking QA team here substantially exceeds the scope of a single article.
After the kernels have passed internal units tests and QA scrutiny, we make them available to our development partners. This vastly broadens the coverage to include external QA and development teams in other companies. Our partners focus testing on their hardware platforms as well as the typical server capabilities their enterprise customers demand.
The last layer of testing includes external beta testers. These beta testers include high-profile customers, as well as the many people in the Linux community who respond to our open invitation to help with testing.
The combination of all these different testing activities yields an extremely stable and well-tested product. It also points out the huge value of the open-source model. It is the combination of testing resources from many different companies and dedicated individuals that scales well beyond the resources a single company could bring to bear to tackle an infinite testing matrix.
Figure 3, composed by Nick Carr, summarizes the development model from requirements gathering, development and testing, culminating in production.
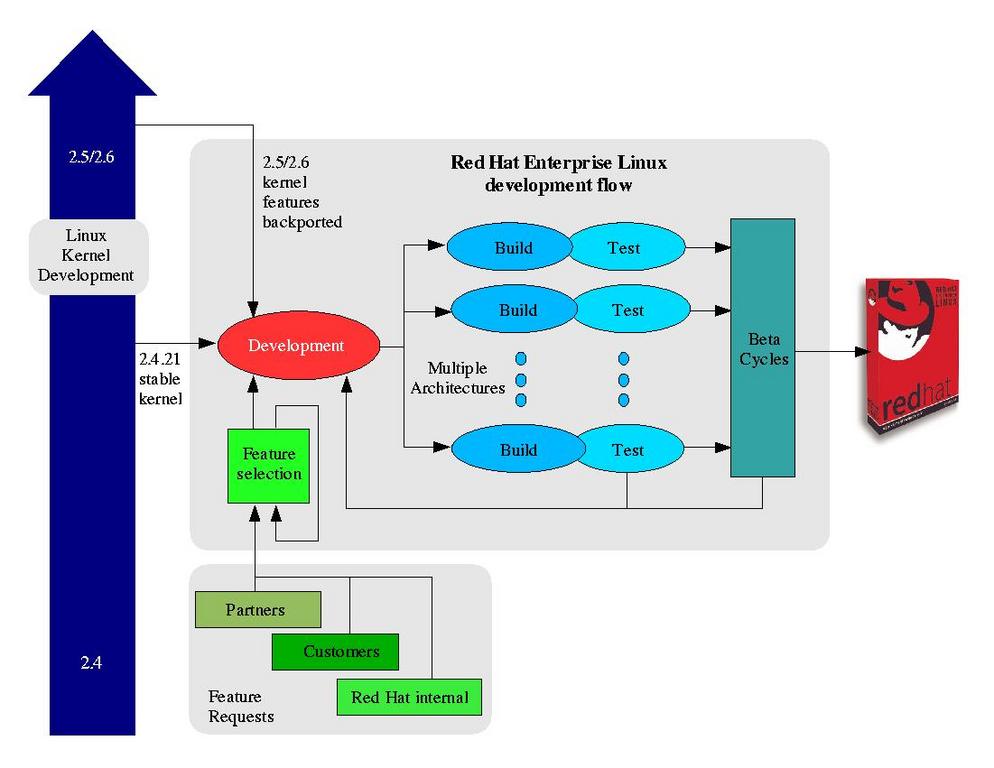
Figure 3. The Development Process, from Requirements Gathering to Release
In the end, the Red Hat Enterprise Linux v. 3 distribution did ship on schedule in mid-October 2003. Having worked for many years for a major IHV on a large-scale operating system engineering team, I have been exposed to both the proprietary operating system development model and the open-source development model. The successful outcome of the Enterprise Linux v. 3 release clearly demonstrates the power of cooperative open-source development. The quantity of features, rapid development time and caliber of participants, both internal and external, is remarkable and stands as a strong testament to the Linux community.
When the release shipped, we all were proud to have contributed to such a tremendous accomplishment. But the time window to rejoice was short indeed. As soon as Enterprise Linux v. 3 finished, it seemed we already were late with the development of Enterprise Linux v. 4. This reminds me of the quote, “Congratulations for winning this battle, that earns you the privilege to come back and fight another day.” Gotta go, more battles to fight.
Tim Burke is the director of Server Development at Red Hat. This team is responsible for the kernel and the set of core applications included in Red Hat Enterprise Linux. Prior to becoming a manager, Tim earned an honest living developing Linux highly available cluster solutions and UNIX kernel technology.

