
Real-World PHP Security
During the past two years, the core PHP developers have done an incredible job of providing the PHP user community with powerful technology that has been able to perform remarkably well in many environments. As Web applications become more popular, Web developers must face an increasing amount of possible security vulnerabilities that have the potential to compromise their work seriously. Many tutorials, books and articles have been published as new techniques are developed. These new emerging threats, however, have not received the focus they deserve.
This article is aimed at professional and open-source PHP developers who must provide a high level of security to their users or clients. The intent of this article is not to provide the developer with a question-and-answer approach but to help the developer identify possible security issues in their own applications during the design process. In the long run, this process enables you, the PHP developer, to respond to new security threats accordingly.
Many articles have covered the subject of secure PHP development, and the same topics usually are covered by every article. Here, I quickly go over those basic concepts because they are important, but I assume you are familiar with this material so I won't spend too much time on it.
PHP provides users with a configuration directive called register_globals that, when enabled, places every variable in the application in the global scope. This means that variables passed to the Web server as POST, GET, cookies and session all are placed in the same basket, providing a convenient way for the developer to retrieve those values.
By design, enabling this directive is likely to affect the overall security of your application, because users gain direct access to the content of any variable you may use in your application. PHP now ships with register_globals turned off by default, and I strongly recommend leaving it at that setting for the sake of security. The exception would be if your server also hosts legacy applications that assume this directive is turned on.
Cross-site scripting (XSS) is a popular technique that allows the user to gain control over the layout, content and overall reliability and security of Web applications. PHP is not the only technology vulnerable to this technique, mostly because it is not really a flaw in the language. Instead, it is more of a concept pertaining to the design of Web applications in general.
Cross-site scripting exists in many different forms, but a popular method is to inject HTML or JavaScript code in form fields in order to make your application display content that otherwise should not be displayed. This concept illustrates the importance of always filtering any kind of input for your application, whether it comes from a user, another site or even from the database. The PHP function htmlentities() is generally a good way of preventing this type of attack.
Having the ability to provide users with a URL they can use to get back to where they are later on is critical for most Web applications. But as a developer, it is important to be able to determine what information the user should be able to access in any possible way. By manipulating the content of the query string, the user gains the ability to modify the content of the variables used by your application.
Preventing this type of event from happening is more complex than simply filtering the input, but this is still a step in the right direction. What is perhaps the most reliable way to secure your applications against this type of attack is setting up a robust data-flow scheme for your application and a solid error-control system.
This type of malicious attack on a Web application can have devastating consequences that go beyond the scope of most other attacks, such as cross-site scripting, because it has the potential to destroy your database and its content permanently and completely.
The concept of SQL injection is quite simple. Most Web applications accept parameters as input from POST and GET variables and from cookies. This input often is used inside an SQL query as a parameter, thus providing the user with dynamic content. If the user has any idea of what your database looks like, they technically should be able to alter the parameters you use to inject SQL commands in to your query.
Let's look at a quick example. Your application accepts data from a form as POST. The goal is to display x records from the database, where users can modify x to fit their needs. Therefore, your form simply has a field called NUM that provides your script with that value. Listing 1 illustrates this process. In this case, a user could forge an HTML form that would send a carefully crafted value that in turn, would empty your table.
Listing 1. Building an SQL Query in PHP Based on POST Variables
<?php
$query = "SELECT id, name FROM `records` LIMIT "
. $_POST['NUM'];
$result = $db->select($query);
?>
Listing 2. A Malicious Form Used to Perform the SQL Injection Attack
<form action="example.com/form.php" method="POST">
<input type="text" name="NUM"
value="5; DELETE FROM `records`">
<input type="submit">
</form>
If the user decides to create a form like the one presented in Listing 2, your end result would look like this:
SELECT id, name FROM `records` LIMIT 5; DELETE FROM `records`
There obviously are simple ways to counter such attacks, but I have noticed that a large number of applications have no facility to protect themselves from this type of attack.
In our particular example, calling the intval() function to convert NUM to an integer would have provided a decent level of security against SQL injection. However, it is important to understand that developers can't think about every single parameter used in all of their SQL queries. Therefore, what you really need to do is streamline this process in your applications.
Because modern Web-based applications commonly tend to gravitate toward a core module or some kind of centralized switchboard system, it becomes easy to implement such a facility application-wise. The details of the implementation of streamlined facilities for your applications are covered later in the article. For now, take note of the following quick tips that will help you build your own solution:
Use regular expressions to filter SQL commands: this method is not appropriate if you intend to accept text from users, but it does a good job of stopping SQL injection by filtering out SQL keywords (Listing 3).
Use assertions: assertions are covered in more detail in later in this article.
Escape strings: if you do not expect to be accepting binary data as input, an important step in securing your input is the use of string escaping. In the example above, escaping the string would not have helped, however; many SQL injection attacks are based on exiting the SQL query prematurely and injecting a new query inside. This is efficiently prevented through the use of functions, such as mysql_escape_string().
Listing 3. A Simple “Harmful SQL Commands” Filter
<?php
function filter_sql($input) {
$reg = "(delete)|(update)|(union)|(insert)";
return(eregi_replace($reg, "", $input));
}
?>
Sensitive information often is stored on database servers and other storage facilities for later retrieval. At this point, it is critical to have at your disposal a facility that allows you, as a developer, to secure that data at storage time and retrieve the information you are looking for when you need it.
PHP offers an extension that allows developers to use the Mcrypt Library (mcrypt.sf.net) to secure data by encrypting it and later decrypting it. The documentation of the Mcrypt extension for PHP is located at www.php.net/mcrypt, and it should be studied carefully before implementation.
The Mcrypt extension supports an impressive array of algorithms, including triple-DES, Blowfish, Twofish and Two-Way. Using the Mcrypt extension is not a very intuitive process if you are not familiar with encryption; it can become quite confusing because of the variety of block algorithms and encryption modes available. Refer to Listing 4 for a sample of what the Mcrypt extension offers and how to use it.
Listing 4. Typical Usage of the Mcrypt Extension
<?php
/* Create your key at random
but keep it handy as you
will use it to decrypt later
*/
$key = "AOQKJLCLIGAKJHSD
<NKLXASLUIHJKHAS
OIUDSgfuyJKLBLKU";
$string = $_POST['password'];
/* First, you must open the encryption module
provided by Mcrypt */
$mod = mcrypt_module_open ('blowfish','','ecb','');
/* You must then create an Initialization Vector
based on a size and a source.
Your source can be custom, but some constants
are available.
Defining the size of the vector depends on the
module you are using */
$iv_size = mcrypt_enc_get_iv_size($mod);
/* The initialization vector will be based on $size
characters from the source /dev/random in our
example */
$iv = mcrypt_create_iv($iv_size,MCRYPT_DEV_RANDOM);
/* The next step is to ensure that your key is not
too big and truncate it if necessary */
$max_key_size = mcrypt_enc_get_key_size($mod);
$key = substr($key,0,$max_key_size);
/* You must then initialize the encryption
mechanism through mcrypt_generic_init */
mcrypt_generic_init ($mod,$key,$iv);
/* You can now encrypt your data through
the use of mcrypt_generic. The function
will return your encrypted data */
$encrypted = mcrypt_generic($mod,$string);
/* Once you have finished using Mcrypt, you
must free the buffers used during the process */
mcrypt_generic_deinit ($mod);
/* Finally, you must close the encryption module
you have used*/
mcrypt_module_close ($mod);
/* Now here is how we can decrypt our data: */
$padded = // see next line
mcrypt_decrypt('blowfish',$key,$encrypted,'ecb',$iv);
/* At this point, our decrypted string has been
zero-padded so we need to remove the extra \0s */
$plain = str_replace("\0","",$padded);
echo "Encrypted string: $encrypted<br>";
echo "Decrypted string: $plain<br>";
?>
Assertions provide the PHP developer with a way to implement error control and preserve the integrity of data. This is not a security-related feature of PHP, and it is implemented in many mainstream languages, such as C or Python, so why am I bringing it up now? Simply put, error control is the first step in providing efficient security for your users or your clients.
Assertions are implemented in PHP through the use of two functions, assert_options() and assert(). The former should be called in your application's initialization or configuration file, and the latter should be implemented anywhere in your code where you need to enforce the validity of your input. Listing 5 demonstrates how assertions can be used to create an error-control system that generates a simple report when an assertion fails.
Listing 5. Error Reporting through Assertions
<?php
/* You can toggle assertions throughout your entire
application by switching ASSERT_ACTIVE to 1 or 0
*/
assert_options(ASSERT_ACTIVE,1);
/* We do want the application to exit when an
assertion fails. (in this example)
*/
assert_options(ASSERT_BAIL,1);
/* In our example, we will do the error reporting
ourselves so we turn off the default warnings
*/
assert_options(ASSERT_WARNING,0);
/* display_error will be the name of our custom
function that will be called if an assertion
fails
*/
assert_options(ASSERT_CALLBACK, "display_error");
$email = strtolower($_POST['email']);
$parts = array();
// Building your regular expression
$regex = "^([.\'a-z0-9]+)@([.\'a-z0-9]+)$";
/* Checking for valid format and splitting
the email address at the same time
Note the special formatting. Everything
is in quotation marks and the error is
commented. We will extract this error
later through regular expressions.
*/
assert("ereg(\$regex, \$email, \$parts); /*
Invalid email address: $email */");
/* This block will not be executed if the
assertion fails so we can safely go on */
$username = $parts[1];
echo "Welcome home, " . $username;
// This is our ASSERT_CALLBACK function
function display_error($file, $line, $error) {
// This block will extract the comment message
$regex = "(.*)/\* (.*)\*/";
$parts = array();
ereg($regex, $error, $parts);
$msg = $parts[2];
// And we can output a nice little report
echo "
<table bgcolor=\"#bbbbee\">
<tr><td colspan='2' align='center'>
<b>Error Report</b>
</td></tr>
<tr><td>File:</td><td>$file</td></tr>
<tr><td>Line:</td><td>$line</td></tr>
<tr><td>Message:</td><td>$msg</td></tr>
";
}
?>

Figure 1. A Sample Report Generated by Listing 5
The PHPUnit Project is a complete unit testing suite freely available to PHP developers and is based on what we have just done. The PHPUnit's home page is located at phpunit.sf.net.
If you have worked on many different Web projects, chances are you have started using a common structure upon which to base your new projects or you have developed your own. There are many ways to centralize data management in your application, and depending on the set of requirements that define your project, some models are more appropriate than others. In the next few paragraphs, I introduce a simple design template that gives the developer a sufficient amount of scalability and flexibility for most enterprise-grade projects.
What you need to do at this point is implement a way to centralize all your input and force it to go through a filtering facility. Doing so gives you the simplicity you need to implement additional functionality in a modular fashion. In our example, we use the following file hierarchy:
/index.php: only file in root.
/lib: libraries, protected by .htaccess.
/lib/config.inc.php: configuration file.
/tpl: templates, protected by .htaccess.
/doc: project and APIs documentation.
/images.
/classes: classes, protected by .htaccess.
As illustrated in Figure 2, your application's core is the index.php file, and it has direct access to any library, template, class or configuration file, but the user never has access to those files.
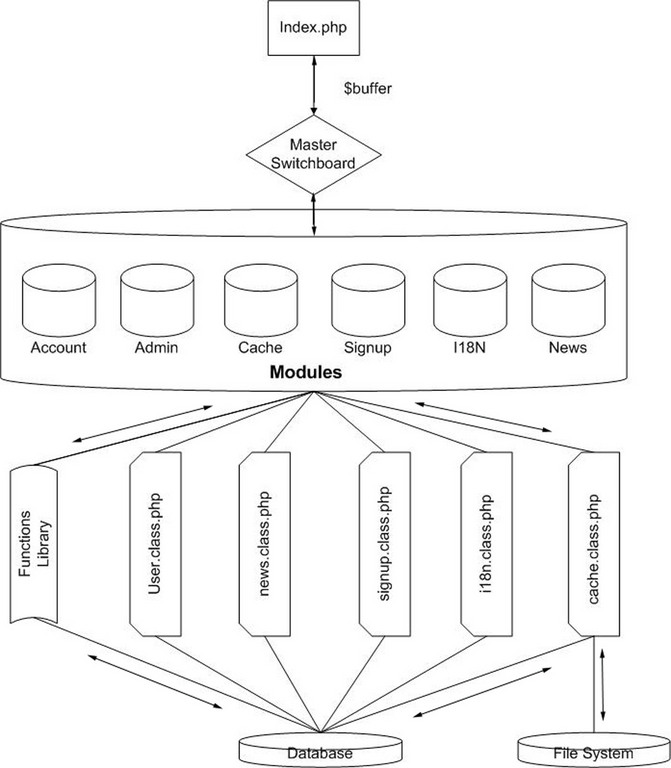
Figure 2. Application Core
Let's follow, step-by-step, the design illustrated in Figure 2 by taking the example of a user logging in to the application.
The user queries index.php with no parameters. Index creates a buffer and passes it over to the switchboard that calls the default module. This module uses a template to display the default page of the application.
The user fills in the authentication form and submits the form. The form redirects its output to something like ?module=account&action=login. The switchboard calls the login function of the account module, which is simply an interface to the user class. The function instantiates an object of the user class. This object is an interface between your module and the database, and it performs the query.
The data is sent back from the database to the object and from the object to the module, which in turn, sets up the appropriate session variables, calls the proper template and uses it to modify the buffer. It then sends the response message to the index.
The data flow in this particular model may seem a little confusing at first, but it really is simple. User input is passed quickly to the appropriate module, and error control is implemented on the switchboard level. Other types of inputs are database access and filesystem access, and they are filtered by their appropriate classes. Every class extends a special skeleton class that provides the input filtering facility, so none of the classes have to worry about this.
This model is efficient as it provides a scalable and robust architecture, but keep in mind that many other interesting models are available. For example, you may want to look at the Phrame Project (phrame.sf.net), which provides an implementation of the Model2 approach, a derivative of MVC (ootips.org/mvc-pattern.html).
PHP's Safe mode is something you should learn to work with whether you are a PHP developer or a system administrator. Safe mode is a set of configuration options that allow the system administrator to alter the behavior of the PHP interpreter by implementing security measures. From a system administrator's point of view, this means you must learn how to implement this feature properly, without making it impossible for developers to set up their applications on your server. From a developer's point of view, you must learn what possibly could get broken in your application if this feature is turned on.
Turning safe_mode on makes sense if you manage a shared server that serves PHP applications and the PHP developers using this server are not trusted. Enabling safe_mode in your php.ini file effectively makes any file-related operation in any of your scripts impossible unless the UID of the owner of the file is the same as the UID of the running script. PHP also gives you the ability to change this policy while safe_mode is on by turning on the safe_mode_gid option. In this case, PHP checks for the GID of the files you are trying to work with instead of their UID.
It also is good practice to not let your users execute any system binary they want; safe_mode_exec_dir comes into play here. This priceless feature lets you tell PHP not to perform any binary execution, through exec() or any other function, unless the binary is located in the safe_mode_exec_dir, such as /usr/local/php/bin.
Once you have familiarized yourself with the restrictions implemented by PHP when safe_mode is enabled, you should be able to develop software that doesn't break when it's run on servers with this directive enabled. Many ISPs use safe_mode. The simple guidelines to follow are:
Try to limit file operations, whether read or write, to the files you have provided with your application.
Do not rely on external software to be installed or executable by your script unless your project is running on only your servers.
System administrators also have at their disposal other powerful tools to ensure the overall security of their systems. These tools include disable_functions that prevent specified functions from being called, as well as options such as open_basedir, which limit any file operation to a specific directory.
The PHP documentation team has provided an extensive amount of literature on the subject. They also have provided documentation for every aspect of safe_mode and related functions and directives.
Resources
Mcrypt Extension: php.net/mcrypt
Mcrypt Project: mcrypt.sf.net
The MVC Paradigm: ootips.org/mvc-pattern.html
PHP Documentation: php.net/manual/en
PHP Security: www.php.net/manual/en/security.index.php
The PHPUnit Project: phpunit.sf.net
The Phrame Project: phrame.sf.net
Safe Mode: www.php.net/manal/en/features.safe-mode.php
Xavier Spriet has been developing software in PHP for the past four years. He is the lead developer at eliquidMEDIA International. You can reach Xavier at xavier@wuug.org.

