
Declic: Linux 2.6 on the International Space Station
In October 2001, three French scientists defined a new project for the study of phase transitions of fluids under microgravity conditions. Declic (Dispositif pour l'Etude de la Croissance et des Liquide Critiques) permits a wide experimental program, operated from the French USOC control centre in Toulouse in close relationship with the other control centers located at NASA and the European Space Agency (ESA). Scientists can do telescience experiments with real-time data sent from the Declic facility to ground, with almost no help from astronauts.
The only astronaut help needed is some exchanges of experiment boxes, the so-called inserts. ALI, one of the inserts, stands for Alice-like insert and refers to the previous experiments, Alice and Alice-2, from the Mir Space Station. Alice stands for Analyse des Liquides Critiques dans l'Espace (analyses of critical fluids in space). A critical fluid is a fluid at a specific temperature and density where the transition between fluid and gas behaves differently compared with the same fluid on Earth.
The French governmental space organization CNES is developing Declic, and it awarded the contract to the European aerospace organization EADS, a joint venture of the German Daimler-Chrysler Aerospace AG, the French Aerospatiale Matra and Spanish CASA. EADS is using four subcontractors for the actual development and is doing the integration tests and project control in Bordeaux. The University of Amsterdam in the Netherlands had experience with several of the previous critical point programmes, therefore we are developing a substantial part of Declic: two thermostat boxes where the experiments take place, the electronics, software for thermal regulation and parts of the data acquisition for scientific research. Two other subcontractors are working on optics, data processing electronics, software for video cameras, data storage and the ISS interface. The fourth subcontractor is developing a complete experiment insert for solidification experiments. Electronics and software for this experiment also are being developed at our institute.
Figure 1 offers a simple overview of the several parts of the Declic facility, which basically contains two large boxes. The first box holds the experiment insert, which is surrounded by optics, video cameras and different sorts of sensors for observing the scientific phenomena. The fluids enclosed in a safe containment inside the insert are stabilized at a high-precision temperature. It's no simple house thermostat; it's a high-accuracy thermal control system that can keep fluids within 10 micro Kelvin of a specific temperature.
The second box (see also Figures 8 and 9) contains the electronics for data handling and temperature control. The electronics and software situated in this box is what I describe in this article. Two important subsystems are located in this second box, the power and data handling system (PDHS) and the central regulation electronics (CRE). The PDHS consists of a CompactPCI industrial Pentium PC running Linux, some microcontrollers and commercial PCI cards. It collects data coming from video cameras and the CRE, stores it on hard disk and interfaces with the ISS computers. Although a real-time link to ground exists, most of the data needs to be stored on hard disk. A removable hard disk will travel by space shuttle to give the scientists their valuable measurement data.
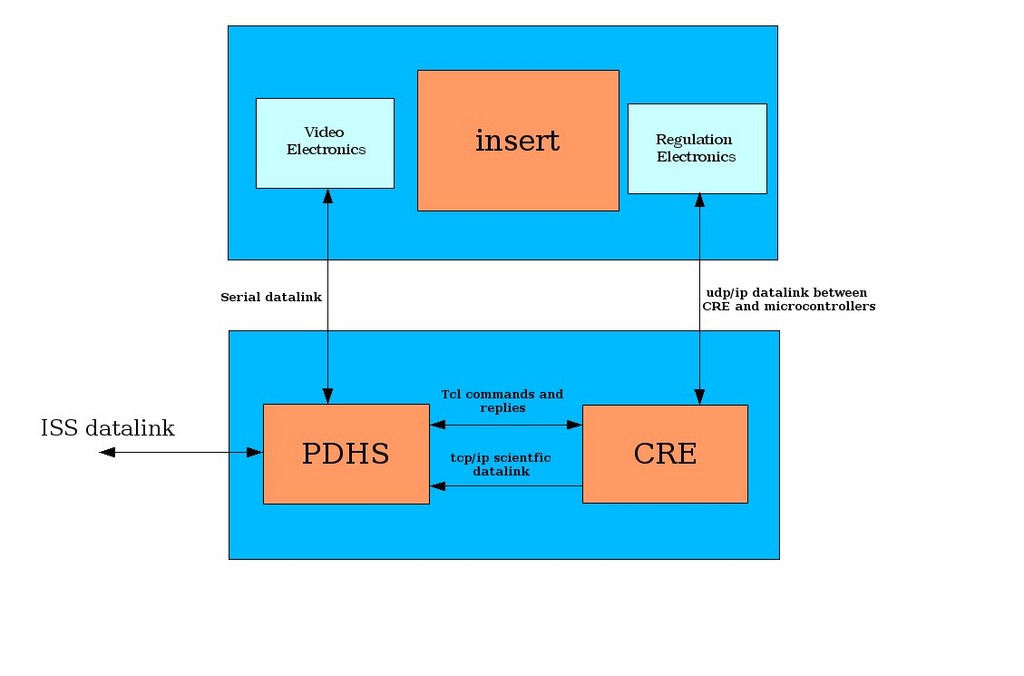
Figure 1. Block diagram of the Declic facility. The power and data handling system is a Pentium-based system running Linux.

Figure 2. The sample cell unit of the ALI insert at the University of Amsterdam. The sample cell contains the liquid to be studied at a critical temperature. The blue box behind the SCU is the insert box.

Figure 3. The ALI insert for study of liquids at critical point at low temperatures. The right side contains the microcontrollers and electronics for thermal control and scientific data acquisition.

Figure 4. Bart van Deenen Doing Thermal Testing of the ALI Insert

Figure 5. ALI Insert Box with Sample Cell Unit

Figure 6. The DSI insert for solidification experiments at COMAT in Toulouse (France). The hole at the top is for accessing video cameras once located inside the Declic facility.

Figure 7. CRE Electronics Box to Be Located near the PDHS

Figure 8. CRE Electronics Box during Testing

Figure 9. The HTI (High Temperature Insert) during manufacturing at the University of Amsterdam; this insert will be used to study water at 373°C.
Temperature control is handled by the CRE. The regulation electronics and software are able to control different types of thermostats inserted in the first box. In the previous experiments, one used fluids with a critical point of about 45°C; this will be done again in the first insert.
Another insert will study the critical point of water, which is near 373°C. At this temperature, water shows an unexpected aggressive behavior, which is scientifically very interesting. Currently, five different experiment inserts are being produced that will be situated inside Declic, all having different characteristics. For the critical point inserts developed in Amsterdam, we have chosen to use platinum resistors for temperature measurements, because it's the only sensor still functional at high temperatures that can maintain the required accuracy. All these sensors are directed to microcontroller boards with analog-to-digital converters of 24 bits. Still, these 24 bits are not enough to reach the high accuracy expected, so all values of the A/D converter first are filtered digitally by an FPGA, a programmable chip. The microcontroller sends the data to the CRE Pentium PC; the CRE CPU gathers all data from different microcontrollers and sends the collected data on a TCP stream to the PDHS.
The complete Declic contains about ten small microcontrollers for dedicated hardware-related tasks, including the activation of heaters, the acquisition of a pressure or temperature sensor and controlling a stepper motor. The microcontrollers we use in Declic have a UDP/IP interface and run the real-time operating system μC/OS-II. Development of the source code for these controllers, however, was initialized on Linux, using an OS emulation layer.
Developing software for microcontrollers often is an annoying process of switching between downloading cross-compiled data over a serial link to a test board, debugging, recompiling your source code and resetting the test board. If you are lucky, the cross-compiler is Linux-friendly; unfortunately, many compiler environments are not. By using the Microsoft Windows emulator Wine, many of the cross-compilers can work together with Linux. In such a situation, you can use all the Linux tools that make software development so much easier. For our system, we chose μC/OS-II as a small real-time operating system able to run on 8-bit microcontrollers. μC/OS-II (often abbreviated to ucos) is distributed in source code form. You can purchase the book from the author and receive the source files of the OS, which can be ported to numerous microcontroller types. All the fundamental real-time OS aspects are there, including semaphores, mutexes and multitasking.
Every ucos function has a GNU C equivalent. For development, we used fake-ucos, a simple set of wrapper functions around standard GNU C equivalents. By using fake-ucos, it's possible to develop your microcontroller code on Linux. Then, you simply exchange the fake-ucos library for the real ucos source code and cross-compile the code for your favorite microcontroller. Of course, you need to extend all hardware-specific code details afterward, but it's certainly a great help in the early phase of a project.
The Declic microcontrollers need to do different tasks, but the process actually comes down to reading something or controlling/activating something—read an AD converter, activate heater x, move stepper motor 1 to location y. The CRE computer, running generic software, needs to know the capability of each microcontroller and the insert characteristics. Each insert is different, and for a future insert it's impossible to know any characteristic. How do we control an unknown set of things and read an unknown set of sensors of unknown type by software we want to keep as generic as possible?
We moved all hardware-specific control elements (AD conversions, activating heaters and stepper motors) into the microcontroller software. The microcontrollers are inside the insert, so each insert has its own hardware microcontrollers and software. A generic C program runs on the CRE main Linux computer for interfacing the PDHS with all the microcontrollers. This program handles the regulation algorithms and a Tcl command interface, which I cover later, and needs to collect all data coming in at different rates from all the controllers. The program is generic because it can control any type of insert, including future ones. High-accuracy thermal control algorithms are dependent on the type of insert; but these parts of the software are written in as a separate module. The command set is insert-independent, because it references only items and the items are described in XML format. An item can be a sensor (something that has a value we can read) or an actuator (something that can be written to). All these items are described in an Insert Definition File in XML format. A short example is given in Listing 1.
Listing 1. Part of an Insert Definition File
<ins_def> <board>
<item>
<pseudo_sensor name="BUILD_VERSION"
max_sample_frequency="1"
device_data_type="CHAR32">
</pseudo_sensor>
</item>
<item>
<sensor name="YSI_PRESSURE"
max_sample_frequency="1"
device_data_type="INT24"
SI_data_type="FP32"
</sensor>
</item>
.....
<item>
<desc>The Dallas board temperature sensor.
</desc>
<sensor name="DAL_ALI_POWER_BOARD2"
dallas="1"
device_data_type="INT16S"
SI_data_type="FP32"
unit="C">
<parameter type="CHAR32" value="">
</parameter>
</sensor> </item>
<item>
<actuator name="PWM_OTSF"
reg_actuator="1"
upper_limit_SI="8.8"
device_data_type="INT16U"
SI_data_type="FP32"
unit="W">
<parameter type="FP32" value="65.0">
<desc>Resistance of heater</desc>
</parameter>
<parameter type="FP32" value="30.0">
<desc>power supply voltage for this
channel</desc> </parameter>
</actuator>
</item>
.....
</board>
...
</ins_def>
The Insert Definition File describes the insert from a software point of view. It consists of a description of all sensors and actuators (items) that can be controlled by a certain microcontroller board. Every item can have a device and an SI value. The device value represents the raw data from, for example, an AD converter, while the SI value is the human-readable converted value, such as Watts, Ohms or degrees Celsius. In this way, we are able to write a Watts value to a heater, and it's up to the controller to figure out what exactly should be written to an FPGA to get the heater to produce this number of Watts. The microcontroller uses the parameters for these calculations, which make the source code independent from such hardware characteristics as heater resistance or power supply voltage. When we read the XML file, the items get numbers in two different ways: an incremental counting for all items of the insert and a local counting for the items controlled by a specific microcontroller board. The scientist has a simple list of all available items that can be controlled with a set of Tcl commands.
In past experiments on the Russian Mir station, all experiment timelines had to be stored on a computer. Experiment control existed by switching on the system and executing a series of commands. The experiment command list had few possibilities to act on specific occurring phenomena or experiment phases. In an early stage of the Declic development, the French company EREMS, responsible for the PDHS development, came up with the idea to use Tcl for the interface. Scientists now are given a complete programming language to formulate the experiment. They can execute commands, store values from read commands in variables and make decisions using the Tcl language for configuring the next executed command. The science script is located on one of the PDHS hard disks and started from the ground. For example, a Tcl science script can contain Tcl statements to bring the experiment to a specific temperature, start the video if the insert has reached a stable temperature and start the acquisition of some interesting sensors.
When writing a science Tcl script, the scientist doesn't need to know much about the hardware; a simple list of items with their numbers is enough. Reading a certain temperature sensor can be done in this way by executing the Tcl command cre_get_values -item 34. The science script executes on the PDHS, and a CRE command results in passing the Tcl command to the CRE computer. The CRE knows that sensor 34 is actually the third sensor on a Platinum sensor controller board. It sends a binary equivalent command to this board, cre_get_values -item 3. The controller makes a data acquisition of the sensor and responds with the value. This response once again is sent back to the PDHS and the running Tcl script.
Now, suppose you want to add an item to the Insert Definition File—how do you keep this XML file consistent with the microcontroller software? It's easy for a Linux system to interpret XML files, but small 8-bit controllers certainly cannot do such things. Adding one item to the Insert Definition File, however, can change all item numbers by one, making the local item numbers no longer consistent with the software implementation. The solution is found in generating C code and header files automatically from the XML file. Putting both files into the Makefile keeps everything consistent. Listing 2 gives a small example of such a generated C file.
Listing 2. Excerpt of a C File Generated from an Insert Definition File in XML
....
char item_names[]={
"BOARDVERSION",
"BOARDID",
"DAL_ALI_POWER_BOARD1",
"PWM_OTSF",
....
"U_FPE"};
void init_items(void){ t_item *items;
item = g_items[ITEM_NR_BOARDID];
item-> item_type=pseudo_sensor;
item-> itemnr=0;
item-> device_data_type=11;
MALLOC(item-> device_value, void, 32);
item-> SI_data_type=0;
item-> SI_value=NULL;
item-> in= NULL;
item-> out= NULL;
...
In Listing 2, the last two entries are pointers to functions that perform the actual acquisition for this item when it's a sensor; it also performs the action for an actuator.
We saw that a single Tcl command results in a multistage command transmission between different Declic subsystems. It's possible to acquire multiple sensors with a single Tcl command, even if they are distributed over several microcontrollers. This results in the arrival of several packets on the CRE computer that need to be collected and sent as one TCP packet to the PDHS. In such cases, a responsive Linux kernel is crucial.
The central CPU of the CRE uses the new 2.6 kernel. It is compiled into a Net-bootable image: the CPU boots using the bootp and TFTP protocols for LAN booting. The image is located on the hard disk of the PDHS, which is booted in a normal way from hard disk. All the microcontrollers boot in the same way. When data transfers take place between microcontrollers and the CPU, a responsive operating system is necessary: we don't want to have the system interrupting the transfers for more than 20ms as sometimes happens in kernel 2.4.
The requirements are soft real time here, and 2.6 fulfills these requirements. All we need is a kernel that immediately triggers a C thread in the main CRE application when data arrives from a microcontroller. The microcontrollers have hard real-time requirements, because they need to be responsive to such hardware events as hardware counters and interrupting devices. Our major application running on the CRE central processor has no such demands. When we started to run the application, using Linux with a 2.4 kernel with several microcontrollers sending data, we encountered timeout problems for packets that were not received in time; although the contents of these packets showed they were sent with correct timestamps. The major improvement with the 2.6 kernel is the low latency of system interrupts.
Linux nowadays is a common tool for space-related projects, whereas several years ago, proprietary systems, such as VRTX, QNX or VxWorks, were leading. In addition, this past year even led to FlightLinux, a standard Linux distribution adapted to spacecraft environments. Open-source software is of crucial importance for these kinds of projects, and our experience with Linux has proven that it has a great future in space.
Resources for this article: /article/7621.
Taco Walstra is a software engineer at the University of Amsterdam. He enjoys rock climbing and playing different types of lutes. He can be reached at walstra@science.uva.nl.

