
Developing for Windows on Linux
Like most people who read Linux Journal, I am a rabid fan of all things Linux, GNU and open source. I run Linux on all of my personal machines, program on them, play on them and evangelize to others whenever possible. But, a large portion of the programming jobs out there involve writing applications for an operating system from Redmond, Washington.
For my job, I've had to write some smaller applications for the Microsoft Windows platform. Because speed of execution was an issue, I was going to have to write them in C, directly using the Win32 API. It occurred to me that if I was going to be using a standard language such as C, I might be able to develop in my nice and cozy Linux home.
This article is a short guide on developing an application for Windows completely within a Linux environment. I give a short introduction to Windows programming and step through compiling and testing a sample program. I also discuss Wine to simplify porting Windows source code to Linux.
For those of us raised on the wholesome nutrition of a UNIX-style process abstraction, the Windows model might seem downright heretical. The Windows model is a preemptive, multitasking, multithreaded, message-passing operating system. I'm limiting myself here to NT and its derivatives, 2000 and XP. All processes are considered threads by the operating system. This makes the process context slightly lighter than the traditional heavyweight process model used in UNIX-like operating systems. As a consequence of this everything-is-a-thread model, however, everything sits in global memory address space. With the correct permissions and the correct address, one program could twiddle another program's bits.
Another consequence of this is data structures created by the kernel don't sit at any fixed address. This means it is up to the user program to lock down the associated memory before using any global data structures, such as graphic contexts. You also must remember to unlock these structures once you are done with them, or they may help cause memory fragmentation.
Listing 1, available from the Linux Journal FTP site (see the on-line Resources section), is a basic Hello World program. Most of it is boilerplate, and only the portion within the switch statement is of any real interest. It does seem like quite a bit of code for a basic program, but that is the problem with using a low-level API. A good comparison on Linux would be writing code for X using Xt.
Instead of a main() function, a Windows GUI program starts at WinMain(). It's in this function that your program does all of its initialization. Part of this initialization includes defining the window class for the main window and associating a callback function for it. Next, create the main window and show it on the desktop. Control then passes to the message loop, and the callback function processes the messages that are sent to the main window.
A good quick introduction to writing Windows programs is available from winprog.org (see Resources). The authors of this Web site offer a good FAQ and a fairly good tutorial covering all of the basics. Of course, the bible for Windows programming is the massive book Windows Programming, by Charles Petzold. If you can't find what you need in this tome, you always can use it to beat the information out of your friendly neighbourhood Windows guru.
One of the amazing things about GCC is that it has been ported to so many different platforms and operating systems. A great gift that comes from this is the ability to compile binaries on one platform that are destined for a completely different one. I regularly compile binaries for Solaris or Windows on my Linux laptop. This is an amazing advantage, allowing development to occur in a familiar, comfortable environment.
The purest way to set up is to go back to the source (see Resources). This way you can compile code with the exact settings and for the exact platform you want. Thankfully, this work has already been done. The good people at the MinGW Project maintain a port of GCC for compiling Windows binaries. This includes all of the associated files, such as the headers. The sources are available here along with binary tarballs. These programs also have been packaged for RPM-based and deb-based distributions. If you are running Debian, you can use apt-get to retrieve the mingw32 and mingw32-runtime packages. If you are running testing or unstable, you also should grab mingw32-binutils.
Most of the compilation options in GCC are available here in MinGW, along with a few extras. If you simply compile a program without any extra options, it can be run from the console. This is what you would do if you wanted to write a small, simple program that did not need a GUI. Because this is Windows, we want a GUI program, so we write all of the required boilerplate we saw above and add the -mwindows option to the compilation command. This sets up the macros and library links you need in order to compile a standard Windows executable. If you decide to write a more complicated Windows program that uses some other Windows' feature, you need to add in the libraries explicitly that you want linked.
In Windows you can define resources for your program. These include such items as menus, bitmaps and text strings, among others. These resources are defined in a separate file and need to be compiled separately before being linked to your executable. That job falls to the program mingw-windres, which creates an object file you subsequently can link to your executable.
To compile our simple example program shown in Listing 1, we use the command:
mingw-gcc -o example1.exe example.c -mwindows
Replace the command mingw-gcc with whatever the package maintainer called the compiler executable for your package. Presto, you now have a Windows program ready for the world. Or is it?
Wine is the other great boon for developers who need to write programs for the Windows platform. The massive amount of work that has gone into Wine by its developers is phenomenal. This great program allows you to run Windows programs from within Linux. The upshot to this is we now can run our freshly compiled program and see if it actually works as advertised. To do this, use the command wine example1.exe, and you should see the window appear on your desktop (Figure 1). When you set up Wine, you have the options of windows being managed by your window manager, not managed or displayed on their own desktop. This affects how the window looks when you run it. What you see in Figure 1 is an unmanaged application.
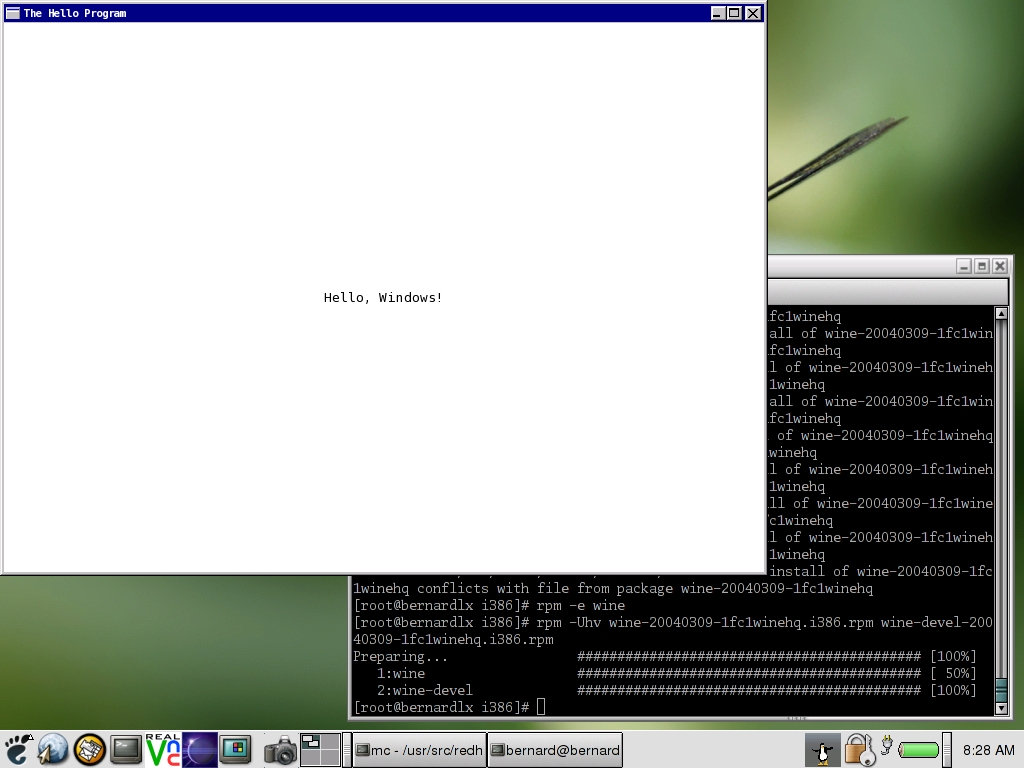
Figure 1. The Example Application Running Unmanaged under Wine
If you weren't lucky enough to have typed your program perfectly, you may need to do some debugging to figure out what has gone wrong. Wine can be a great asset here. The option --debugmsg [debugchannel] outputs the results from one or more debug channels within Wine. Examples of the available debug channels are:
relay: writes a log message every time a Win32 function is called.
win: tracks Windows messages.
all: tracks all messages.
Don't use all unless you really need it. The amount of output quickly can overwhelm even the most detail-obsessed programmer. A complete list of available debug channels can be found on the Wine site.
We now have a wonderful, working, bug-free program that runs under Windows. Considering that all of the work was done under Linux, wouldn't it be nice if we also could have our program run under Linux? The good folks at the Wine Project have come to the rescue again. Part of the project includes winelib, a library that provides the interface to Linux for your Windows source code. In order to use this functionality, you need to install the wine-devel package for your distribution. If you installed from source, the required files already should be available.
Included in the wine-devel package is a Perl script called winemaker. This script is designed to go through your source files and directories and make the required changes to get it to compile correctly against winelib on Linux. Things it checks include filename case and line ending characters. In addition, it replaces file path back slashes with forward slashes and does many other things. By default, it backs up any source files it needs to change. It converts your project to winelib, making all kinds of automagic changes. To compile, you simply run:
winemaker . ./configure --with-wine=/path/to/wine make
to create a Linux executable. The dot you see above is there on purpose. You hand in the path where winemaker can find the source files it needs to analyze; here, the files are in the current directory.
In our case, our sample doesn't have any project files, and winemaker thinks this is a bit of a problem. We can do the steps involved simply by hand. Instead of executing mingw-gcc to compile our program, we use winegcc with the exact same command-line parameters. This creates a file ending in .so and a shell script to handle the program execution. We now have our Windows source code compiled and running under Linux.
I hope I've been able to convince some of the Windows developers out there that they can work effectively from within Linux. With GCC allowing compilation of an executable for Windows, and Wine providing great support in running and debugging, there is no real reason to boot up Windows in most cases. The only reason would be if your favourite IDE didn't run correctly under Wine, but then you always could volunteer to fix that problem, right?
As this was only a short introduction, I did not cover support for MFC or the creation of DLLs. Both of these topics are discussed in more detail at WineHQ and the MinGW site.
Resources for this article: /article/7555.
Joey Bernard is a systems architect for CARIS, a GIS company in Canada. He's never actually done any GIS work, mostly just Oracle, UNIX systems programming and some Windows programming.

