
My Other Computer Is a Supercomputer
In November 2002, I was called by Mitch Davis (Executive Director of Academic Technology, ITSS, Stanford University) and Carnet Williams (Director of Academic Technology, ITSS, Stanford University) regarding an aggressive, high-profile project. While I was Director of Network Operations at the Stanford Law School, I had the pleasure of working with both Mitch and Carnet during their respective terms as Associate Dean/CIO of Stanford Law School. They told me Dr Vijay Pande, the principal investigator behind the Folding@home Project, wanted to purchase a large commodity cluster, and they sent my name to Vijay as someone who could manage projects effectively to completion. Instinctively, I agreed. We discussed more details of the project, and right before I hung up, I asked, “How big will it be?” They responded, “300 dual-processor nodes.” I thought, “600 CPUs...that should do some damage.”
While Mitch, Carnet and Vijay worked with Dell and Intel to negotiate the purchase of the cluster, I sent an e-mail to Vijay Pande, stating that I could assist him with the network and hardware side of the project and that I hoped to learn more about the software side during the process. The last line in my message said, “I want to be part of something great.” Vijay responded promptly and welcomed my assistance. We set up our first meeting to discuss the scope of the project.
At that initial meeting, it seemed most things were up in the air. Everyone knew equipment was coming, but no real plans were in place. Vijay said he knew that authentication and filesystem choices had to be made, and of course the opportunity to use existing Stanford services was considered.
Vijay also mentioned running PBS, MPI and MOSIX. I knew very little about any of these, but took notes and, back at my desk, did a Google search for those names along with the words “beowulf” and “cluster”. I came across a presentation about building a cluster using an open-source distribution named Rocks from an organization called NPACI (www.rocksclusters.org). The presentation was excellent. It answered so many of my questions, such as, how would we put together such a cluster, how would we manage software on nodes, how would we configure the master node and how would we monitor nodes. Basically, the presentation was a framework for how we would build our cluster. I printed copies of the presentation and brought them to our next meeting. The idea of using a packaged solution was well received.
During the time these two meetings were taking place, the cluster was being racked and stacked by Dell in Stanford's Forsythe Data Center, which took seven days. I was able to download a copy of Rocks version 2.3 and run through the installation process on what is defined as the front-end node in Rocks nomenclature. This task was simple, and I was quite impressed at this point. At our third meeting, my role in the project had expanded from being involved only with hardware and the network, to handling software also, as I already had brought up the front end with Rocks successfully. I felt confident that I could handle the rest of it as well, but at this point I didn't realize the true scope of the project. I was embarking on building the largest-known Rocks cluster.
The first issue I ran into was trying to install compute nodes. A Rocks utility called insert-ethers is used to discover compute nodes' Ethernet MAC addresses, assign them an IP address and hostname and then insert this information into a database, during a negotiated process using PXE and DHCP. Following the node insertion, the node is built and configured as defined in a Red Hat Kickstart file, completing the PXE boot process. Unfortunately, I had problems with the network interface cards in the Dell PowerEdge 2650, as the Broadcom Ethernet controllers did not appear to be supported in Rocks. I sent my issue to the Rocks discussion list, and I also called Dell for support and opened a ticket for service under our Gold support contract. The Rocks developers quickly provided an experimental version of their cluster distribution that contained updated drivers, which solved the problem, and soon I saw my suggestions and observations incorporated into the maintenance release of Rocks version 2.3.1.

Figure 1. Iceberg in the Forsythe Data Center
The final issue, which was discovered at scale, was the inability to have more than 511 active jobs. My users were screaming about the 100 idle processors, because many of the jobs run on Iceberg are short-lived, one- to two-processor jobs. While working with the Rocks Development team, we looked for a defined constant in the Maui scheduler code. I eventually found it, and under the guidance of the Rocks team, recompiled and restarted Maui. The front end now can schedule as many active jobs as there are processors.
By late December 2002, with the last of the hardware and software issues resolved, we turned our sites toward putting Iceberg on the TOP500 Supercomputer list (www.top500.org). The TOP500 is a biyearly competition that ranks 500 entries by sustained performance for a linear equation solver, Linpack. On the November 2002 list, there were 97 commodity clusters, so we felt confident we could put Iceberg on the list.
Taking a run at the TOP500 list proved to be more work than we anticipated. Rocks comes with a prebuilt Linpack executable that can attain good performance on a Pentium 4 cluster, but I wanted more. My account representative put me in contact with the Scalable Systems Group at Dell. We collaborated on tuning Linpack on the cluster and did work such as linking Linpack against the Goto BLAS (basic linear algebra subroutines) library written by Kazushige Goto (www.cs.utexas.edu/users/flame/goto). Additionally, Dell suggested an improved interconnect topology. Prior to the TOP500 run, all 300 nodes were distributed over 16 100Mbit Ethernet switches (Dell PowerConnect 3024). We found that Linpack, like many highly parallel applications, benefits from an improved network interconnect (in other words, one with lower latency and/or higher bandwidth). Dell loaned us a Gigabit nonblocking switch to replace some of our 100Mbit switches.
The above enhancements improved our performance, and we submitted the results for the June 2003 TOP500 list. Iceberg sits at #319 and, in my estimation, could be higher with a faster interconnect.

Figure 2. Running Linpack to Qualify for TOP500
From the beginning, Iceberg's permanent home was to be in the James H. Clark Center, which is named for the man who started Silicon Graphics and Netscape and who is the predominant funding source for the Bio-X Project. By August 2003, it was time to move. The move from the Forsythe Data Center brought many great things, one of which was a clean installation of Rocks. I really pushed for this because having a solid and stable infrastructure is key in maintaining a cluster of this size while maintaining a low total cost of ownership.

Figure 3. Iceberg in its new home. From left to right: Vijay Pande, principal investigator for Folding@home; Steve Jones, Iceberg architect; Erik Lindahl, postdoc; and Young Min Rhee, research scientist.
Through the lifetime of Iceberg at the Forsythe Data Center, we found that both choices on the configuration of software and hardware could be improved. The downtime incurred during the move allowed us to make modifications to the physical design. We decided to go with a front-end node and move the home directories to another node with attached storage. Once again, Rocks came through. It was as simple as using insert-ethers and selecting NAS appliance as the type of node being inserted. We chose to use link aggregation to exploit the dual Gigabit Ethernet network cards in the NAS appliance fully. After a few modifications on the front-end node to connect users to the new appliance and moving the backed-up data to the new appliance, we were operational once again.
Folding@home on Iceberg
We use Iceberg as a debug platform for Folding@home, which is a distributed computing project to study protein folding, misfolding, aggregation and related diseases. Volunteers contribute spare processing time to the project, and currently about 80,000 CPUs are active.
For the Folding@home research study, I exclusively use Iceberg to simulate small projects, where a project is a set of simulations of one protein coupled with a specific method. Writing a script that mimics what Folding@home does with clients was the key to this work. For a run, typically I use 10–20 CPUs at a time.
For other large projects, I used Iceberg for the starting portion only. We usually calculate 10–50ns of simulations in chunks of 1ns. I could use Iceberg for the first 1ns and then move it to Folding@home and continue there. We can rapidly iterate upon new methods in the controlled, stable environment that Iceberg presents. As we develop new projects, we use Iceberg to validate the results, and once we are confident with the new methods, we unleash the new project onto the 80,000-CPU distributed computer.
—Young Min Rhee of the Folding@home Project, folding.stanford.edu
Computational Biology on Iceberg
The Iceberg Dell Supercluster has been a complete revolution to our research. We have been using supercomputing centers for decades, but we always felt limited by relatively restrictive queues, too-small runtime quotas and difficulties in adopting the system to our needs. The last couple of years we have been building our own Linux clusters with 50–100 CPUs, but off-the-shelf hardware leads to higher support and administration costs, not to mention the fact that the cluster is sometimes idling, such as when we are busy writing papers. The new Dell cluster at Stanford is an extremely cost-effective solution to this; by having a shared resource, there are hundreds of nodes available when we want to test a new model overnight, but our cost is only the average number of nodes we are using. We are not only in complete charge of the hardware, but the resources also are an order of magnitude more powerful than anything we've used before or after the installation; we spend only about an hour a week on administration.
Computational biology usually involves extremely heavy calculations on sequences or protein structures. Some of the most common applications involve finding matching patterns between families of sequences or structures and simulating the motions of atoms in biomolecules. Pattern matching it is no big deal for a handful of sequences, but our current project, together with the Department of Energy, relies on large-scale prediction of accurate models for the proteins in the Shewanella bacterium (famous for its ability to eat radioactivity and toxic waste). This involves hundreds of thousands of sequence profiles of which we need to make all-vs.-all comparisons. It used to take weeks of carefully planned runs on our local cluster, but now we literally are able to test an idea overnight and submit a new version of the experiment the next day.
The molecular dynamics simulations of atomic motions are also as impressive. The simple idea is to calculate the forces atoms exert on each other and then use Newton's equation of motion to determine new positions a very short time later (a step is usually 2 femtoseconds, that is 2 × 10-15 of a second). A single iteration in the simulation is fast, but billions of steps are required to study biological reactions. For this reason, we have optimized our code manually to use Intel's Streaming SIMD Extensions instructions, available on the Pentium 4 Xeon CPUs to speed up our programs Gromacs and Encad by a factor of 2–4, which made it possible to simulate proteins like the Villin headpiece (Figure I) for more than a microsecond, using only two weeks of time on ten of Iceberg's nodes. Actually, with the optimized code, even the individual Dell/Intel Xeon processors are faster than the top-of-the-line IBM Power4 or Alpha CPUs (chips that are found in other supercomputers), at less than one-tenth of the cost. This is by far the best computer investment we ever made, and we will not hesitate to expand it in the future.
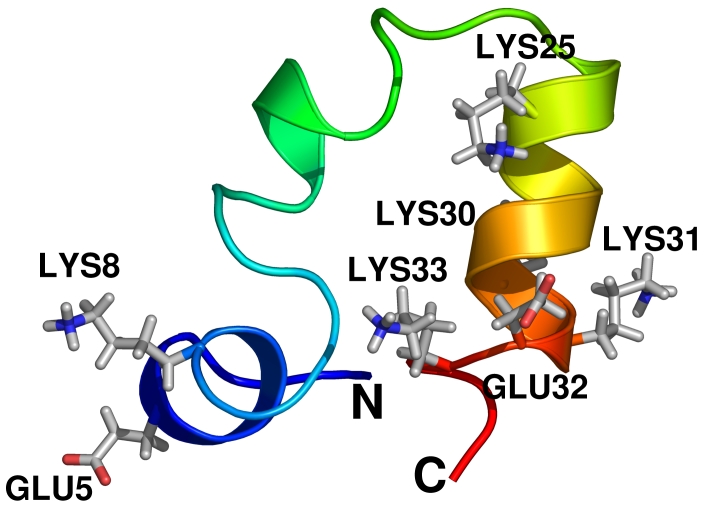
Figure I. The Villin Headpiece
The Villin headpiece is a very small protein consisting of about 600 atoms. However, the cell is always surrounded by water (red/white rods), which brings the atom count up to about 10,000. Every single atom interacts with the closest 100–200 neighbors; the interactions have to be calculated every single step, and then we repeat this for a half-billion steps to generate a microsecond of simulation data. The data for Figure I was generated from a two-week run on ten of Iceberg's nodes.
—Michael Levitt and Erik Lindahl of the Department of Structural Biology, Stanford University School of Medicine
The goal of any high-performance computing cluster should be to bring it to a stable and working state as quickly as possible, and then run it until the hardware dies. This allows the users of the system performing research to have a stable system to use on demand. Making changes to the system for the sake of making changes is not how to handle a computing system of this scale. In my mind, this is what is provided by using the cluster distribution that we've chosen on which to standardize. The only administration work should be monitoring queues, filesystem sizes, reviewing logs for errors and/or activity and monitoring hardware to determine whether replacement is needed. With the combination of Rocks and a support plan from Dell, using Silver support on the compute nodes and Gold on the front end, we will enjoy three years of worry-free performance and parts replacement. Our goal is to generate funds by billing for compute time that will allow for the replacement of the cluster within the three-year period. And when the new cluster arrives, we'll install Rocks, and we will be off and running for another three-year cycle.
The current plan is to charge for usage on Iceberg with the idea that the revenue generated will cover the purchase of a replacement cluster in three years. This replacement most likely will be Iceberg-II, with the same node count, but a 1U form factor rather than 2U in order to maximize our floor space. Iceberg will stay on-line as separate cluster and decrease in size as hardware fails.
Additionally, we are in the planning stages of acquiring a new 600-node cluster that we plan to bring up in the next 6–12 months. This cluster will be housed at an off-site location. We are in negotiations with a research institute that has expressed interest in housing the cluster and providing specialized services (generated power, UPS, power, HVAC and so on) free of charge, in exchange for processing time on the cluster. Other options are being considered as well. Outside the scope of Iceberg, I'm looking into building yet another cluster for commercial purposes. I'd like to think this would be the largest Rocks cluster when completed, in addition to claiming a top-20 seat on the TOP500.
The right mix of an infrastructure person and researchers who actually run jobs on the cluster managing the system, along with empowering interested users in different labs that utilize the system, has been the key to keeping costs at a minimum for maintaining Iceberg. We have delegated tasks now so that firewall management, scheduler configuration, user administration, hardware maintenance and general cluster administration tasks are consuming only a small amount of any person's time. The average time spent administering is an hour a week. This speaks to the design of the system and the choices made in keeping the total cost of ownership of a 302-node supercomputer at the same price as ten nodes.
Steve Jones (stevejones@stanford.edu) left his position at the Stanford Law School in order to pursue a position as a security strategist for an Internet service provider, while consulting for a security startup. He's in the process of moving to Maine where he'll be working as the strategist for another school and starting yet another company. In his spare time, he'll also be managing a 302-node cluster dubbed Iceberg.

