
Linux in Air Traffic Control
Many people say Linux isn't ready for air traffic control, but in reality, it is ready and already is being used. Recently I was involved in a project that ported the FAA's Common ARTS software (www1.faa.gov/ats/atb/Sectors/Automation/CommonArts/index.htm) to Linux.

A Controller in Atlanta
When most of us think of air traffic control systems, we usually see round screens with a sweep. Some people know what the RADAR antenna array looks like. Between the RADAR antenna and the display are a few computers to make things easier. The Digital Signal Processors (DSPs) are in the antenna building, and automation systems are used as well. This article describes how the automation system works, and where Linux was used.
The Automated Radar Terminal System (ARTS) got its start back in 1964 on Univac computers. The system eventually went nationwide in 1973. The original computers have been upgraded and continue to be used today. Many of the larger sites moved from the Univac computers to microprocessors during the 1980s. All of the legacy ARTS software was ported or rewritten in C to run under the real-time LynxOS during the move to microprocessors.

Full digital ARTS display. The ACDs (right side) are replacing these vector displays. All the knobs are now menus on the display.
The move to LynxOS was fortuitous, as it provided a POSIX base to which further porting could be done. Using LynxOS also allowed developers to choose which microprocessors to use. Initially, the software ran on Motorola 68K CPUs, and it currently runs on PowerPCs.
The Common ARTS system is a highly distributed, networked, multithreaded, real-time system. Absolute reliability is a requirement. Dual networks are used, and under normal conditions, two backups are assigned to each specific task. The software is designed such that some functions of one subsystem can be taken over by another subsystem.
The RADAR data comes in over serial lines to each of the track processors (TPs). Normally, four serial lines go from each RADAR to each TP. The data on the RADAR include the raw RADAR signal, a transponder beacon (each aircraft should have a transponder that returns an ID and an altitude in the beacon each time the RADAR pings the aircraft) and weather data. The same antenna array usually receives all three signals. Any of the RADAR and beacon data can go down any of three serial lines, with weather transferring on its own serial line.
The TP is divided into at least two subsystems, the serial message assembly and the actual track processing. Serial message assembly converts each message type (raw RADAR, beacon and weather) into a network message. Track processing involves correlating RADAR and beacon messages (targets) into a single track. A track is the known history of the aircraft. Targets can be RADAR, beacon signals or both. Once a target is correlated to a track, another track message is put on the network.
Messages usually are broadcast on the network. They are sent using UDP on both trunks, and each message has a unique packet ID. Each computer on the network listens to both trunks and keeps a record of the packet IDs it has heard from each unique network ID. If there is a gap in packet IDs, a chassis may request a rebroadcast. Duplicate packet IDs are ignored, assuming it was the message on the other trunk or some other chassis requesting a rebroadcast.
Each system must broadcast heartbeats on the network. If a heartbeat is missed, it is assumed the system is down, and one of the other systems sends a message to have a standby system take over.
The next processor to deal with the network messages is the common processor (CP). The CP does many things, such as matching flight plans to tracks, sending conflict alerts (CAs), minimum safe altitude warning (MSAW) and monitoring some of the Common ARTS system heartbeats. The biggest thing the CP does is determine airspeed and direction of a track.
CA uses the speed and direction to look at other tracks to determine the possibility of a conflict. If a conflict is detected, the CP broadcasts a CA message indicating the aircraft in conflict. When aircraft are traveling at 300KTS—about five miles a minute—it is important to be looking a minute or two ahead.
MSAW uses a site-adapted map to learn terrain in the area. The terrain can be hills and mountains as well as towers and buildings. For transponder-equipped aircraft, the MSAW system looks at the altitude and the position and determines if the aircraft may be too low. If an aircraft is determined to be too low, an MSAW message is broadcast.
The last major system in the back room is the system monitor and control (SMC). The main purpose of the SMC is to monitor and control the other systems. It is a gateway to the SMC display PC, a GUI for monitoring the network and its current state. Current state indicates the systems that are on-line, off-line, standby or idle. If a heartbeat is missed, the SMC instructs a standby system to take over. A system operator can instruct a manual switch at anytime, load new software or reboot systems from this PC. The SMC also is used for recording all the data that crosses the network.
What most of us think of when we think of air traffic control are the displays: a room full of round vector displays and guys in white shirts watching them. More and more sites are using large 20"-square color displays. The new color displays are 2048×2048 pixel, X window displays. The design of the display processing software (DPS) is such that parts of it can be used by any display type, the color square display, like an ARTS Color Display (ACD) or the round vector display, like a Full Digital ARTS Display (FDAD).
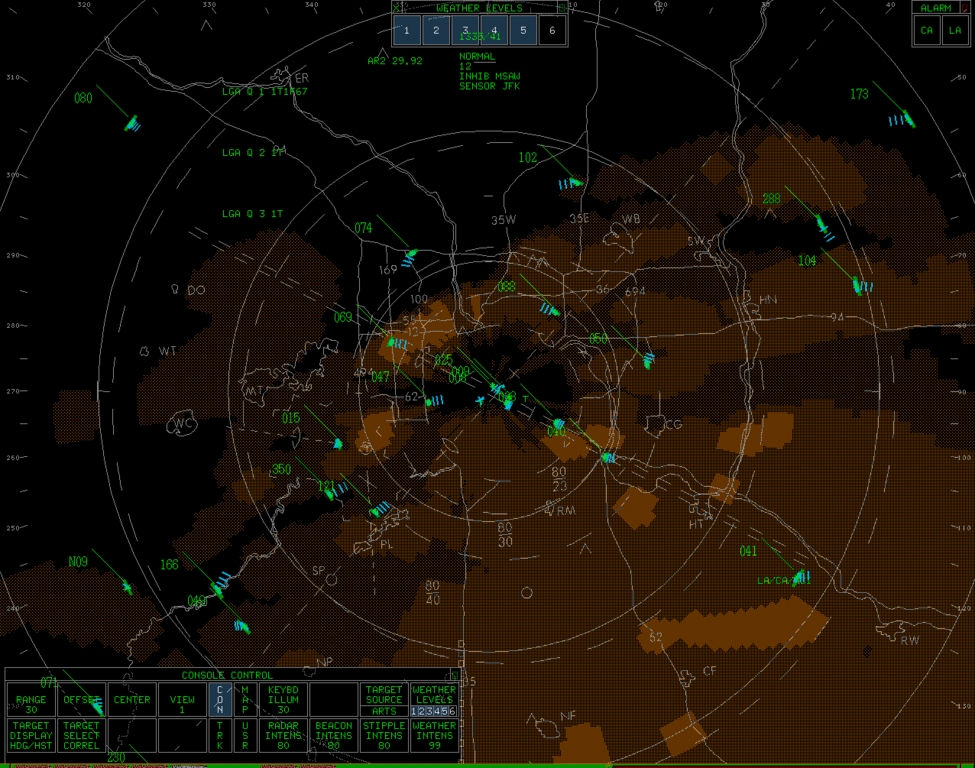
Actual screenshot of the 8-bit VGA Linux DPS software. Compared to the ACD display, only the all-brown weather is different. The blue history trails look similar, and the green beacon and RADAR images are the same. The menu is transparent to the map, but not weather.

A real controller watching an ACD.
The DPS receives the broadcast messages and displays appropriate images depending on the state of the system. In normal operation, the display includes a track indication, a direction history indication, a full or partial datablock and the state of the various systems.
The flight plan information message from the CP is displayed in the full datablock near the aircraft for which the TP created the track. The broadcast SMC overall state can be displayed as well. The network can use one or several hundred displays.
In addition, each system can be run on one or more CPUs. If the CPU is powerful enough, all the systems and subsystems can be run on a single CPU.
Initially, the reason for the port to Linux was to allow developers to test and debug the systems at their desks before testing on the target hardware. The target hardware is Motorola OEM boards in a VME chassis running LynxOS. The systems are relatively expensive, so neither the FAA nor Lockheed-Martin wants to have a bunch sitting around. Instead, several test systems are used almost full-time for integration testing and development.
Because the IS department gives developers a Microsoft Windows NT PC, an attempt was made to port the software to NT. Most of the port was completed when I started working for the company. For testing some things, NT worked fine. An adapter layer was used to make the POSIX threads, file I/O and graphics behave like the target system, so it wasn't good at testing those features.
When I started contracting at Lockheed-Martin, I was placed in the messaging layer group, the group that maintains the communications, threading and file I/O for the system. Basically, none of my testing could be done on the desktop, and I had to use the target hardware. Initially, a side project was working to see if it was possible, and I was given one old (200MHz Pentium) PC for development purposes.
Most of the code compiled just fine, although there were some issues with POSIX standards. LynxOS 2.4 and 3.0 used an older standard, whereas Linux uses the current one. I initially was doing the development on Red Hat 7.0 with a 2.2 kernel, and it didn't support named semaphores or named shared memory segments. In a distributed system like ours, it is easier to use standard names within a processor than some other communication mechanism to know where the shared memory and semaphores are. I did cobble together a named shared memory compatibility layer, and I found a Russian site with a named semaphore compatibility layer.
During development I moved to Red Hat 7.1, which was supposed to support named shared memory, but there was an incompatibility between glibc and the header files. I was able to look in the source to find this problem, and I posted a note to the kernel mailing list. Someone beat me to it, though. To keep things stock, allowing anyone to pick up any Red Hat version without this fix, I left my cobbled-together version in the code.
The target hardware was all big endian (Motorola 68K and PPC) and the Linux PC was an x86 little endian, so I needed to do some byte swapping to make the whole system work. Many of the files are stored in binary (maps, adaptation, and so on) format. The networking layer already had a byte-swapping mechanism built in, and it worked great.
Once I had all the messaging code compiled and running, I needed an application. The FAA agreed to fund the further development of the TP, CP, SMC and DPS systems for desktop testing and debugging. The systems all ported well, but the DPS had some issues with X displaying. Normally the large 2048×2048 pixel display is run on special hardware with two or three pseudo-color physical planes. If the maps and menus are drawn on the bottom plane, the weather on another plane and the aircraft on the top plane, the whole display doesn't need to be redrawn if an aircraft moves. To make this plane idea work, the color map was split into three parts. Being pseudo-color (8-bit) limited the number of colors in each plane. The map and menu plane got one color (white), the weather got another color (brown) and the primary display plane got 78 colors.
So, we needed to have more color table adjustments, as normally the primary display used 250 colors. The large display has an animated fading history trail that emulates the fading phosphors on the vector display. It takes 128 color cells to make the animation work. For this application I made one cell and no animation. It looks amazingly good. Between finding all the reds that were similar, greens that were similar, and yellows and blues and whites and grays, I trimmed the table down to the 78 available.
Once all this was done, I was given a two-plane video card to see if the system would still work. A change to one compile-time flag had the whole thing working. The two-plane card puts the weather maps and menus on the same plane.
Two things happened about this time. I delivered the Linux code to the FAA, and a couple other developers were tasked with getting Linux working on the target PowerPC hardware. The FAA found a few updates I hadn't kept up with in the baseline of the code, and we were able to work together on that. The other developers found most of my #ifdefs were specific to Linux and not the machine architecture. Therefore, I was able to hold back my changes to the FAA and make the proper #ifdefs when the FAA finally took it.
The PowerPC Linux Project was an attempt to improve the data recording tasks that the SMC handles. The current system uses consumer-grade, off-the-shelf optical disks that aren't suitable for 24/7 writing. The new system incorporates SAN disks, which are more suitable to air traffic control needs. Although technically a success, the project is on hold for now.
In the spring of 2003, the FAA began using the Common ARTS on Linux for a noncritical subsystem, an inexpensive gateway system feeding ARTS data to other systems. Full certification may happen eventually.
Tom Brusehaver is a coder grunt who has been writing code since before the PC. He mostly does contract work these days, preferring embedded systems. He is married and has grown kids, two cats and a dog. He is building an airplane when the weather is nice.

