
Upfront
cfg2html: members.tripod.com/rose_swe/cfg/cfg.html
This utility will go over your system and extract a lot of information, enough information that you should be able to rebuild the system almost exactly as it was. That's probably a little more detail than I'd be comfortable with putting on a web site, but great to print out and put in your system's notebook (your systems do have notebooks, right?). Requires: BASH and standard UNIX tools.

—David A. Bandel
Shortly after the kernel's Halloween feature-freeze, Guillaume Boissiere decided to put together some statistics on the incorporation of features into the 2.5 tree. He examined almost the entire history of the 2.5 development cycle, starting in early 2002. He created seven possible status categories for any given feature: planning, started, alpha, beta, ready for inclusion, pending inclusion and fully merged. His first progress chart (Figure 1) shows the percentage of features in each category. The second progress chart (Figure 2) shows the actual number of features in each category, changing over time. Without making any claim to complete accuracy, the graphs are interesting, if for no other reason than to observe how seriously most developers took the drive toward feature-freeze. Note also the hump of work done over the summer, followed by a complete end to new feature planning. That hump of activity corresponds roughly to the time when the decision was made to freeze by November.

Figure 1. The Percentage of Features in Each Category
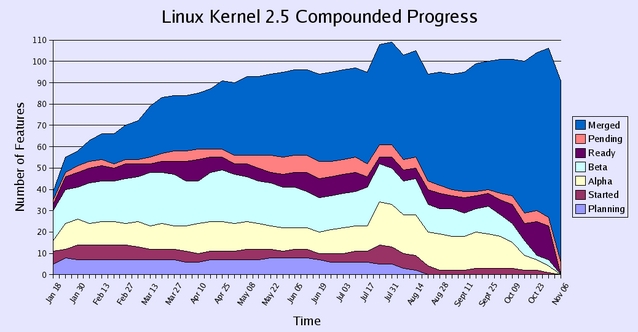
Figure 2. The Actual Number of Features in Each Category
To facilitate the movement from feature-freeze to actual 2.6 (or 3.0) release, the Open Source Development Lab (OSDL) donated labor and equipment to maintain a Bugzilla bug-tracking database for the Linux kernel at bugzilla.kernel.org. Support for this was initially strong among developers, but it tapered off a bit when big guns, like David S. Miller, found duplicate entries and frivolous reports made the system, at least in its original form, more trouble than it was worth. No one wanted to give up on it, however, and a concerted effort seems to be underway to bring the bug database to a usable state.
In more debugging news, Linus Torvalds indicated for the first time he might be willing to accept patches into the kernel to support a kernel-based debugger. Traditionally, Linus' stance has been that real programmers debug from source files. While not actually explaining the reason for his change of policy, he now seems to think that a kernel debugger running across a network would be a good feature to let into the kernel. Don't look for it in the next stable series, however, as he was careful to make this statement after the feature-freeze had passed.
A new read-only compressed filesystem, along the lines of cramFS, emerged in late October and targets the 2.4 kernel. SquashFS claims to be faster and to produce tighter compression than either zisoFS or cramFS. The author, Phillip Lougher, wanted to address some of the limitations of other compressed filesystems, particularly in the areas of maximum file size, maximum filesystem size and maximum block size.
And speaking of filesystems, does anyone remember xiaFS? In 1993 it was regarded, along with ext2fs, as a serious contender for world domination. In fact, the two filesystems leapt into public use within a few weeks of one another. For a while it even looked as though xiaFS had taken the lead. By 1994, however, it had essentially dropped off the map, and a few years later it was actually dropped from the official kernel tree. In 2000, Linus remarked that it would be fun to have it back. Finally, just after the Halloween freeze Carl-Daniel Hailfinger asked if this offer was still good. Linus said sure, and even offered to make an exception to the feature-freeze, if Carl could deliver the patches.
—Zack Brown
Percentage of movies released between 1927 and 1946 that are currently unavailable: 93
Number of government desktops converted to Linux in Spain's Extremadura region by November 2002: 10,000
Number of government desktops expected to be converted to Linux in Spain's Extremadura region by November 2003: 100,000
Downloads of Extremadura's own Linux distro, Linex, from outside the district: 55,000
Dozens of countries with laws encouraging free software: 2
Number of free software laws or policies pending in those countries: 70
Number of Linux management tools in IBM's Tivoli in 2001: 2
Number of Linux management tools in IBM's Tivoli in 2002: 20
Percentage of IT managers employing Linux “in some capacity”: 39
Number of different Linux-based PDAs: 23
Number of servers in a Linux cluster installed at the University of Buffalo in September 2002: 2,000
Number of servers in another Linux cluster installed at the University of Buffalo in November 2002: 300
1: Jason Schultz, in a letter to Lawrence Lessig
2-6: Washington Post
7, 8: Information Week
9: Goldman Sachs Research, IDGnet
10: LinuxDevices.com
11, 12: Boston Globe
Setting the mood for this month's issue is our cover photograph of Mark Hansen and Ben Rubin's Listening Post, currently featured at the Whitney Museum of American Art in New York (www.whitney.org). This remarkable installation runs on four computers and as many operating systems (including Linux, of course) and expresses the collective voice of the Internet, transforming on-line communication into a multimedia installation.
According to the Listening Post web site, “statistical analysis organizes the messages into topic clusters based on their content, tracking the ebb and flow of communication on the Web. A tonal soundscape underlies the spoken text, its pitches and timbres responding to changes in the flow and content of the messages.”
I was lucky enough to “view” the Listening Post when it was in Seattle in November 2002, and my first impression was an almost eerie sense of humanness the piece unveils—a poetry not typically associated with computer technology. In a dark room complete with pillows on the floor, a wall of tiny screens depict glowing green text gathered in real time from thousands of public on-line communication channels. These bits of text are accompanied by a computer-generated voice with a British accent, randomly speaking different messages as they flash by. I was particularly struck by the “I am” series; real-time messages beginning with the string “I am” spoken into the darkness: “I am tired.” “I am happy.” “I am Norwegian.” Hundreds of people communicating the most basic aspects of themselves at that precise moment from who knows where to who knows who, while my imagination worked double time wanting to fill in the rest of their stories.
Capturing the ephemeral nature of the Listening Post is difficult; however, Ben Rubin, one of the creators of the Listening Post, best describes the piece in his artist's statement:
Anyone who types a message in a chat room and hits “send” is calling out for a response. Listening Post is our response—a series of soundtracks and visual arrangements of text that respond to the scale, the immediacy and the meaning of this torrent of communication.
Every word that enters our system was typed only seconds before by someone, somewhere. The irregular staccato of these arriving messages form the visual and audible rhythms of the work. The sound-generating systems are constructed almost as wind chimes, where the wind in this case is not meteorological but human, and the particles that move are not air molecules but words. At some level, Listening Post is about harnessing the human energy that is carried by all of these words and channeling that energy through the mechanisms of the piece.
Listening Post represents the most significant outcome so far of my collaboration with Mark Hansen, the only artist I know whose medium of expression is statistics. Since we began working together, my conceptual vocabulary has grown to include notions like clustering, smoothing, outliers, high-dimensional spaces, probability distributions, and other terms that are a routine part of Mark's day-to-day work. Having glimpsed the world through Mark's eyes, I now hear sounds I would never have thought to listen for.
Visit the Listening Post web site (www.earstudio.com/projects/ListeningPost.html) for exhibition dates and further information.
—Jill Franklin
The Linux NetworX Evolocity super cluster built for Lawrence Livermore National Laboratory is the number five supercomputer in the world, according to the Top500 Supercomputing List, and it's tops among Linux-based supercomputers.

Here are some facts about it:
2,304 processors.
Can process 5.694 trillion calculations per second (teraFLOPs) running the Linpak benchmark and up to 11 trillion calculations per second using other measures.
Is the size of a full tennis court.
Cooling requires 109 tons of air conditioning, enough to cool 22 homes.
Uses nearly nine miles of cable.
Weighs 35 tons.
Is 8.6× more powerful than Deep Blue, the IBM computer that beat Garry Kasparov in 1997.
Has the same amount of processing power as 11,200 PCs.
Can do in one day what would take an average PC 25 years.
Could assemble the human genome in 18 days, compared to the 150 days it took Celera.
Has 5× the memory required to hold the entire Library of Congress.
Is 5.6× more powerful than the computer used by Pixar to create the movie Monsters Inc.
(Source: Linux NetworX)
—Doc Searls
Note: www.0x49.org
I had a tough time choosing between a couple of extremely good utilities I reviewed three years ago. These included Downloader for X, which I use regularly, gnotepad+ and xglobe. But I had to go with Note. There's nothing incredibly special about Note other than it does exactly what it says—keeps notes for you. It works by keeping your notes in a binary, DBM or about any Perl-supported SQL back end. Notes can be edited, deleted or moved into subfolders (topics). Your notes database also can be either in plain text or encrypted form. This makes it ideal for storing passwords or other sensitive information. Requires: Perl, Perl modules: IO::Seekable, DBI::mysql (or other DBI-specfic module, optional), DB_File (optional), MD5 (optional), Crypt::IDEA (optional), Crypt::DES (optional), Crypt::CBC (optional).
—David A. Bandel
N-View: www.n-view.de/index_en.html
For those of you who've used tkined, the network monitor N-View will not be a stranger. However, N-View is quite a bit faster and easier to use. You can have multiple tabs with different subnets. Its biggest drawback, requiring JRE, can be overcome by simply using the package with JRE included. N-View will also mail you if a particular system is suddenly unreachable, though that's not much good if that system is your e-mail server. Requires: Java.
—David A. Bandel
I've visited a whole lot of government organizations. Virtually every government agency I've visited has Linux somewhere in the enterprise....The question is: Does anyone know about it?...I suspect at least half of those who say they don't use it have it in their enterprise but don't know about it.
—Robert Hibbard of Red Hat
We haven't developed the vocabulary to credit the open-source dynamic for what it is rather than a puzzling aberration of hackerdom. Once we have the vocabulary—a way of measuring quality vs. cost—we'll elevate open source to the pinnacle it deserves: the most productive process in an economy obsessed with productivity.
—Britt Blaser
Tower Toppler: toppler.sourceforge.net
Here's a great little game, especially for your preteens. The object: get to the top of the tower. The problem: all kinds of things are trying to knock you down. Some of the things you can destroy, and some you simply have to avoid. The game has excellent graphics, and play is extremely smooth. A number of levels and towers are available, but at the rate I get knocked off, I'll be on the beginner tower for a while. Requires: libSDL, libpthread, libz, libstdc++, libm, libX11, libXext, libdl, glibc.

—David A. Bandel
email: zbrown@tumblerings.org
