
A Linux-Based Steam Turbine Test Bench
Despite the fact that mathematical models and the incredible growth in computer power allow one to imitate and calculate almost everything now, there are some areas where real experiments are still very important and can't be replaced with computer models.
One of these areas is the design of low-pressure steam turbines (LPMTs). LPMTs are an important part of any power plant working on a steam or combined gas-steam cycle and generate up to 20% of the power plant's energy. Unlike high- and middle-pressure turbines, where steam has well-known properties, the LPMT works with nonstructured, nonsymmetric wet steam. No fully proved mathematical models exist yet for this kind of flow. Real experiments are crucial for design of the turbine flow path and improvement of the turbine computer models.
There are only a few such test benches in the world. One of them is a part of the Central Boiler and Turbine Institute in St. Petersburg, Russia, where I have worked for the last seven years. Imagine a hall 18 meters in height and 700 square meters in area filled with pipes, wires and measurement equipment. There is a cyclopic construction in the centre (see Figure 1), which is the casing of the model turbine with two huge exhaust pipes. During the tests, it consumes 40 tons of steam per hour, using live steam at a pressure of 30 bars and a temperature of 400°C on the bench inlet, about 4 bars and 200°C on the model turbine inlet and deep vacuum, as low as 30 mbars absolute, on the exhaust.

Figure 1. The turbine under test is in the center, surrounded by steam pipes and test equipment.
During our joint project Tanja with Alstom Power, the information infrastructure of the test bench was renewed. Now it includes three main parts: 1) a high-accuracy scientific measuring system, called Data Acquisition System for flow path measurement, or DAS-Flow; 2) a technological measuring system, called Data Acquisition System for Operational Personnel, or DASOP; and 3) workstations for researchers and engineers.
The DAS-Flow system originally was supplied mostly by our customers. It provides the capabilities to measure more than 200 pressures and 50 temperatures along the flow path. A separate part of this system allows us to investigate the distribution of pressures inside the turbine with 12 movable probes. Each probe can be moved in two directions, axis and angle, by stepper motors through a remote-control system. All the pressure measurements are based on PSI-9000 series pressure transmitters from PSI, Inc. These transmitters provide very high-measurement accuracy: below 0.01% for a few reference pressures and below 0.1% for the rest. The system performs the measurements only from time to time, under stable conditions. It's not designed for dynamic pressure measurements.
The DASOP system was built by ourselves to provide on-line control of the whole bench during the test. It works in real-time mode, collecting data from more than 150 pressure, temperature, speed of rotation and vibration sensors. This data is presented for operational personnel on two monitors and a serial terminal in the control room (see Figure 2) and includes information about the current state of water, oil and steam systems of the bench. DASOP also provides a safety control, with some warning and emergency levels.

Figure 2. DASOP shows operational and safety information in real time.
All the computers we use, except one IBM RISC workstation, are normal PCs, ranging from 386s up to Pentium 4s and Athlons.
When I came to the Tanja Project in 1995 I had a lot of practice building data acquisition and evaluation systems based on Russian clones of the Digital PDP-11 running the RT-11 or RSX-11 operation systems. In 1994, I started to play with my first PCs and quickly realized that DOS is not suitable for our tasks because of its single-task and single-user nature. During that time, my brother Mike brought me my first Linux distribution, Slackware as I recall, based on a Linux kernel version somewhere around 0.99. I discovered right away that I could solve almost all of my tasks by studying the sources of similar programs and using them as prototypes. My first data acquisition system was finished in 1994. It was ncurses-based, and it still works for my former employer without any maintenance from me.
At the beginning of the Tanja Project, we had only the DAS-Flow system supplied by our customers. It was a zoo of operating systems. We had MS-DOS, Microsoft Windows 3.11 and NT, QNX and AIX. The positive side was the fact that all the computers were joined on a local TCP/IP network.
Thinking about the development strategy for the whole system and keeping my experience in mind, we decided to stay on Linux as a base for the development of our technological measuring system, DASOP, and for the core of our network. The main reasons were the following:
The availability of a wide range of ready-to-use applications and the source code of the applications for studying and templating.
Great stability and reliability on cheap PCs, which is one of the top requirements for our applications.
We have a very limited budget, so the zero cost of Linux was important.
A very friendly community available through Fidonet echoes and Usenet newsgroups.
What do we have now? The core of our IT structure is six PCs running Linux. Over more than six years there have been no cases of failure, we have measured uptimes in years, and there have been only two reasons for rebooting: hardware upgrades and long power outages our UPS couldn't handle.
We started with Red Hat, and we still have two computers running Red Hat 4.1 Vanderbilt and Red Hat 5.0 Hurricane. Then we switched to a Russian localized RPM-based distribution named KSI and came to Debian last year. For the moment, our main server and my development machine work under Debian/Woody. We are very satisfied with Debian, and I think that this year we'll switch all our Linux boxes to Debian.
All computers are connected to the local network, split into three segments (see Figure 3). The first segment includes all the DAS-Flow computers; the second, the DASOP computers and office computers; and the third looks to the outer world via the leased line. The third segment includes only one computer, which acts as our gateway to the Internet, with a firewall based on ipchains and mail server.
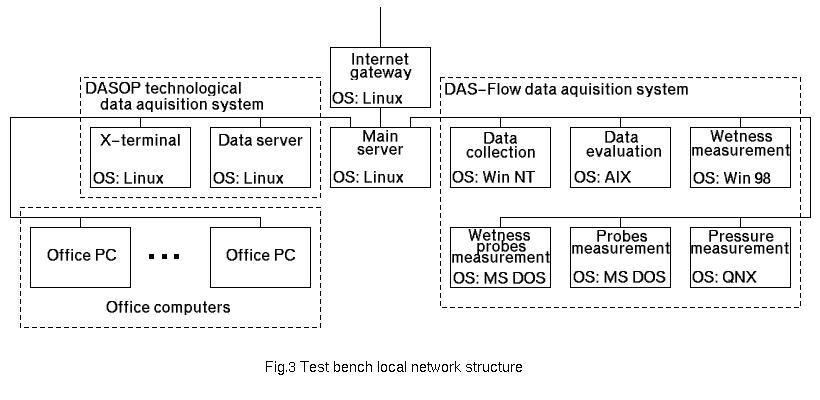
Figure 3. The Test Bench Local Network Structure
In the “middle” of the network is our main server. It acts as file- and print-server for all the computers, but this is not its main task. During the tests, we collect a large amount of data. All this data, as raw, measured values and later as evaluated parameters, is automatically stored in a MySQL database. An Apache web server provides a powerful interface to the database for all users—our local researchers and our customers abroad—through HTTPS.
Any registered user needs to have only a browser to access the database, search the data and get results in a text or graphical form. PNG, CGM and PDF formats are available. We use mostly PHP, as an Apache mod_php module, for generating data-driven pages. Almost all graphs are generated on the fly using the gnuplot program via Perl CGI scripts, which select the parameters from the database, pipe them to gnuplot and then pass the generated image to Apache. We wrote more than 50 different CGI scripts to provide users with all possible kinds of plots, where the user can select everything—what parameters to plot, search conditions, kind of characteristics to plot, auto or manual axes scaling, kind of smoothing and approximation and other choices.
I have to mention specifically the important role of gnuplot in our project. In my point of view, it's one of the greatest scientific plotting utilities with a wide range of capabilities and output formats. It's still under active development, and I'm always trying to use the latest development versions, which are quite stable even for my production environment. I also use the well-designed JpGraph PHP classes for generating certain plots, especially some kinds of fast search results.
Another important part of the software we developed is the technological data acquisition system DASOP (see Figure 4). It has a modular structure and includes the data acquisition module, data evaluation module, socket communication module and application modules.
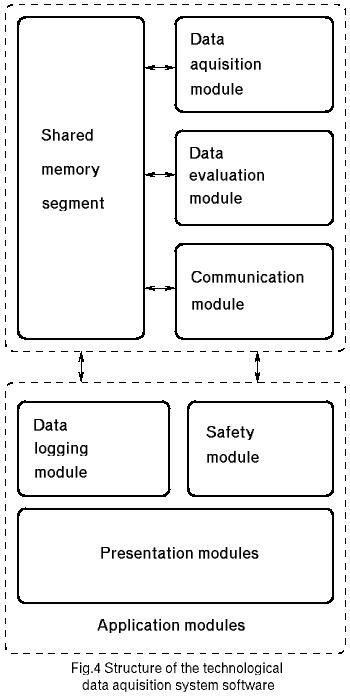
Figure 4. The Structure of the DASOP System
The data acquisition module works with a Programmable Data Controller (PDC) connected by an RS232 interface to a PC. It gets about 150 values from the PDC every second and performs some manipulations with PDC digital I/O if needed. All the measured data is placed in a shared-memory segment as a two-dimensional array, where each column is a full set of all parameters' raw values. The number of columns is fixed, so we always have a fixed number of last-measured datasets in memory.
The evaluation module, which is synchronized with data acquisition modules through a mechanism of semaphores, gets the last measurement set from the shared memory, makes some on-line evaluations and places evaluated data in the same column, extending its length.
The socket communication module provides access to the shared-memory segment for the remote application modules. There are several application modules. Some of them can be run locally with direct access to the shared-memory segment with measured and evaluated data; another can do it remotely via the communication module. Application modules include data logging modules, a safety control module and data presentation modules.
Data presentation modules provide different kinds of graphical presentation of the data in real time. Some examples are parameters over time plots, bar plots (where the color of the bar shows the state of the parameter—normal, warning or emergency) and panels looking like real external devices.
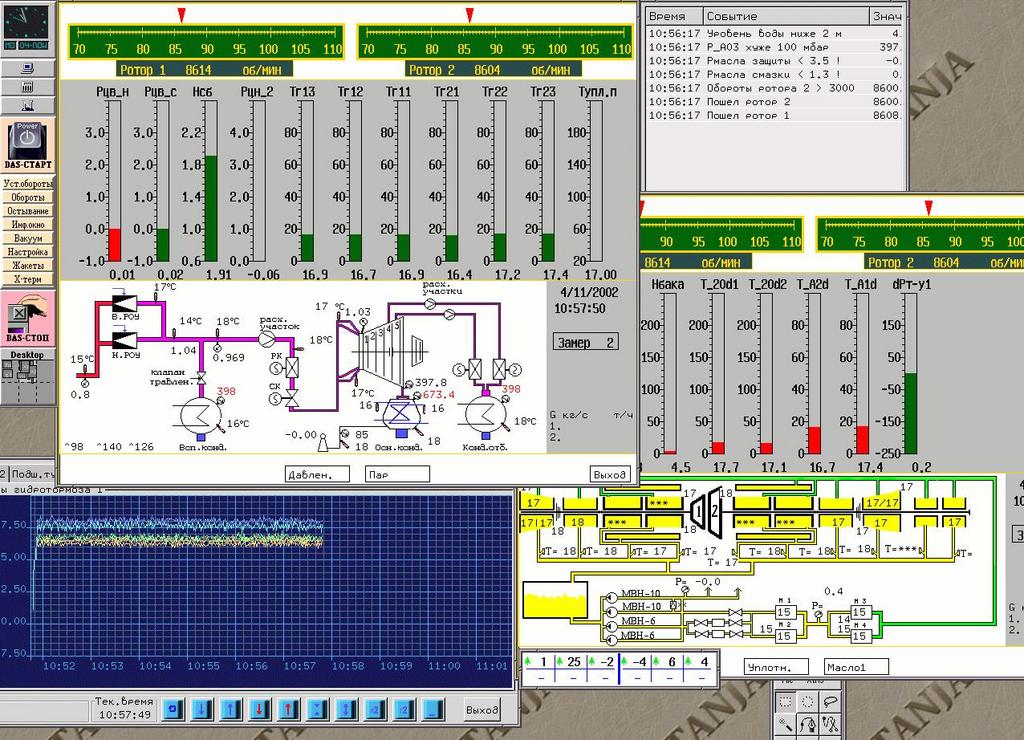
Figure 5. DASOP Data Presentation Modules
Because of our scheduling requirements we do not need hard real-time operation. Soft real time is enough for us, so we use the normal Linux kernel for our hardware. Data acquisition, evaluation and communication modules are written in plain C and work on the same PC. Safety, logging and some of the presentation modules work on that PC also. Part of the presentation modules work on another PC, which works as an X terminal for the first one. Both PCs, with their monitors, are located in the control room of the test bench to provide all the information to operational personnel. Some presentation modules work on the researchers' PCs, getting information via the communication module.
The development of presentation modules has changed over time. At first, they were ncurses-based programs for the Linux text console. Later, I switched to X, using only standard X11 and Xt libraries. The next step was trying Motif, which we bought from SuSE. The open-source GTK appeared one or two years later, and I switched to it. Over the last two years, almost all presentation and other modules have been written in Tcl/Tk, with an extensive use of the BLT extension. I found Tcl/Tk useful for fast GUI development, serial and socket communications and data presentation.
Several years of software development and use in a real industrial environment showed us (and our customers) that open-source solutions are effective from any point of view—cost, time, reliability or function set. Our next steps will be replacing the rest of the proprietary software in our project with open-source software.

Alexandr E. Bravo was born in 1959 in Leningrad, which is now again (as it was 300 years ago) St. Petersburg, Russia. He graduated in 1982 from Polytechnic University with the specialty “Automation and Telemechanics”. He has worked with Linux since 1994.
