
The IP Security Protocol, Part 2
In Part 1 of this article, we talked about security issues related to sending and receiving IP packets and the function of IP Security, or IPSec. We also discussed different levels of security and security protocols. In Part 2, we move on to encapsulating security payloads and key exchange mechanisms.
IPSec ESP format, specified in RFC 2406, provides confidentiality, authenticity and integrity. The original packet is transparently encrypted by the IPSec layer before being sent and decrypted on the receiving side. An eavesdropper capturing packets in any intermediate node will not be able to recover the original contents of the packet (or, at least, he should not be able to do it in a reasonable amount of time).
Encryption algorithms usually employed for ESP include DES (mandatory for any IPSec implementation), IDEA, Blowfish and RC4. Other encryption algorithms may be adopted as well, maintaining the basic IPSec infrastructure and the ESP packet format.
The ESP header includes the same common IPSec fields found in the AH header (SPI and sequence number), which are used to associate the packet with the proper "IPSec session". Encrypted payload follows the header and is followed by the ESP trailer, which includes an optional variable length padding that helps conceal the original data length and a Next Header field, which is used to determine the upper layer protocol.
The ESP trailer also may be followed by an integrity check value, as in the AH header, in case authentication besides encryption is required. This is usually the case since using encryption without authentication is quite dangerous (see Resources). Encryption protects your data from being eavesdropped, but it does nothing to prevent a malicious user from passing himself off as a legitimate peer and send you fake data. In this case, IPSec encryption even could have a negative effect, as it might cause a false sense of security.
There is a slight difference between the authentication provided by AH and the one provided by ESP. The former also applies to the IP header data, most notably the source IP address, whereas the latter only includes the packet payload.
IPSec, both with AH and ESP, can be configured to work in two very different ways: transport mode and tunnel mode. With transport mode, AH or ESP is applied only to the packet payload, while the original IP header remains untouched. The AH or ESP header is inserted after the IP header and before any layer 4 header. In tunnel mode, AH or ESP is applied to the entire original IP packet, which is then encapsulated into a completely new IP packet with a different IP header.
Let's see what this means from a practical point of view. In transport mode the packet maintains its original IP header, thus allowing intermediate routers to recognize it properly (think of quality of service provisioning, for example). On the other hand, an eavesdropper can see the flow of data between the two communicating hosts, and depending on the context, he still can extract a great deal of information from this knowledge. The eavesdropper would not be able to understand the packets' contents, hence the privacy of the communication would be preserved.
Tunnel mode actually provides IP-over-IP transport functionality. In other words, one IP packet is piggybacked on another one, potentially going towards a host that is different from the final destination. In general, using an "outer" IP layer to deliver packets belonging to an "inner" IP layer makes it possible to have two separate IP networks with different topology and addressing schemes, superimposed one over the other.
When in tunnel mode, IPSec offers complete protection from any kind of analysis, because an attacker would be able to learn only the IPSec tunnel endpoints (which are written inside the "outer" IP header), without being able to determine the actual communicating hosts (whose IP addresses are written inside the encrypted "inner" IP header). The drawback is the impossibility for intermediate routers to apply special packet handling techniques to manage the protected traffic, since they too are not able to recognize packet flows properly.
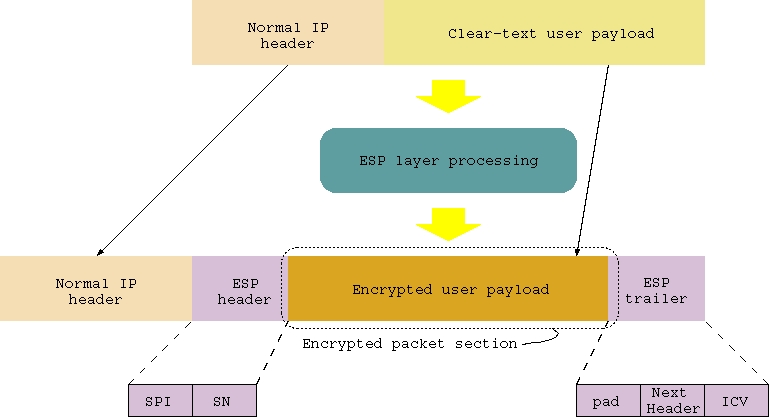
Figure 2
and
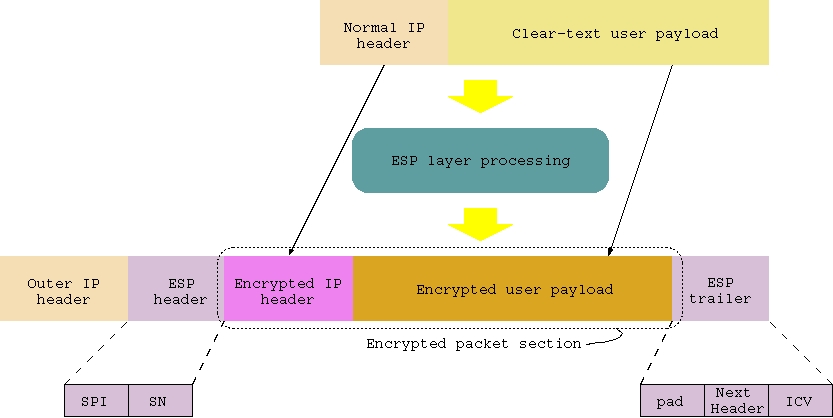
Figure 3
show the difference between an ESP packet in the two modes.
When in transport mode, IPSec must run on each of the communicating peers. In fact, the two must be able to correctly handle the additional headers and manage the IPSec fields. Tunnel mode instead may be used between two routers, acting as the ends of a protected tunnel, which would transparently apply AH or ESP to the packets flowing between them. In this case, the communicating peers would be unaware of the presence of IPSec.
Different networks can be connected by using security gateways running IPSec in tunnel mode, without having to install and configure IPSec software on each host in the LAN. For this reason, tunneling is currently the most widespread IPSec mode, because it allows for the seamless deployment and integration of secure communication services. Needless to say, this is a key component in the building of Layer 3 VPNs.
Up to now, we have been talking about IPSec relationships between two communicating peers, taking for granted the existence of some kind of trusted liaison between them. In IPSec jargon, this relationship is called a security association (SA). For each IPSec instance (i.e., each peer it is communicating with), a host or gateway keeps an SA that collects all the information related to the instance itself. For example, it may contain the following:
IPSec mode (either tunnel or transport)
negotiated encryption algorithms
SA granularity (which depends on the selector, described below)
An SA is uniquely identified by three parameters:
SPI (Security Parameter Index)
destination IP address
security protocol (either AH or ESP)
The SA represents a monodirectional, secure logical channel working with a single security protocol. If a bidirectional data exchange is required (normally it is), two SAs are needed. Also, if both AH and ESP are required for communication, two SAs for each direction are needed.
For each network interface enabled to "talk" IPSec, two databases are maintained: the SA database (SAD) and the security policy database (SPD). When a packet is being sent, the IPSec layer looks for its destination address in the SAD. If an entry is found, the relevant information is extracted and used to properly protect and encapsulate the packet.
On the receiving side, the arrival of a packet triggers a search by the SPD, which identifies the policies that should be applied to the packet. The key used for the look up in the SPD is called the packet selector. In IPSec terminology, this is information extracted from the packet (e.g., IP source and destination addresses, TCP or UDP ports and so on) sufficient to define the packet flow belonging to the SA. Depending on whether the selector is fine- or coarse-grained, an SA may be applied to all the packets exchanged between two peers (regardless of L4 protocols and ports) or to a specific packet flow. For example, if you wanted to define an IPSec channel for receiving HTTP data from a specific IPSec-enabled web server, the selector would be (<destination address: your IP>, <source address: web server's IP>, <L4 protocol: TCP>, <source port: 80>).
Three policies may be applied to a received packet, depending on the result of the SPD search:
discard the packet
bypass IPSec and process the packet normally (IPSec is not used for this packet flow)
apply IPSec according to what is specified in the SAD
According to these procedures, each packet going through an IPSec-enabled interface is subject to IPSec policies. In particular, packets that do not contain any IPSec fields are filtered. When no entry is found in the SPD for a particular packet's selector, the default behavior is to discard the packet.
As we have seen, the whole IPSec architecture is based on the presence of some common secret keys on both peers. Before any secure communication may begin, such keys are used to establish the SA. Keys may be manually configured on the peers (e.g., a passphrase may be agreed between the security administrators), or they may be automatically distributed using the IKE procedure. The keys may range from simple two-host shared secrets to digital certificates issued by official certification authorities. Hence, IKE can scale from a simple point-to-point data exchange mechanism to a complex network of encrypting hosts.
The IKE procedure creates a secure tunnel between two peers and then uses it to negotiate the SA. Note, this tunnel has nothing to do with the data tunnel that will be used eventually to exchange IPSec packets. More specifically, the IKE procedure in split into two phases. In Phase 1, the two peers establish a secure channel over which configuration data can be safely exchanged. In Phase 2, the IPSec SA is actually negotiated.
The first operation of Phase 1 is the authentication of the remote peer. As noted above, encryption without proper authentication can be extremely dangerous. Different authentication mechanisms can be employed, ranging from shared secret keys (manually configured) to public key cryptography. In the latter case, key exchange is based on the Diffie-Hellman algorithm reinforced with the usage of public key signatures.
The most straightforward application of IPSec is having two hosts that need to exchange private data over an unsecured IP network (be it the Internet or a LAN). In this case, transport mode ESP IPSec can be employed. The most common IPSec application is the interconnection of remote LANs over the Internet, usually in order to set up a corporate VPN. For this kind of application, since many hosts are involved and configuring IPSec on each one would be awkward, tunnel mode ESP IPSec can be deployed on the LANs gateways. As already noted, this is completely transparent to the hosts.
Another interesting application is the road warrior case. Suppose an employee needs to remotely access a file server on his corporate LAN. IPSec may be configured to use AH, in tunnel mode, from the remote host to the LAN gateway (outer SA). Furthermore, another SA (inner SA) would be set up between the remote host and the local file server, using ESP in transport mode. The outer SA would guarantee the road warrior's authenticity, whereas the inner one would keep data encrypted even within the LAN. This can be useful if some employees are not completely trusted; most computer crimes are committed from within the attacked LAN--not from the outside.
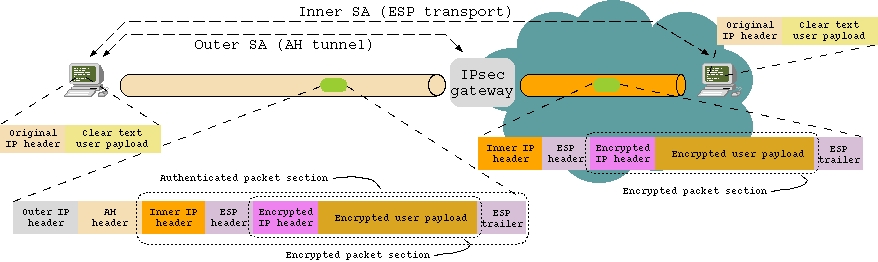
Figure 4 illustrates the road warrior case, highlighting the packet structure in each part of the path.
IPSec importance is growing, but unfortunately its operation imposes a significant burden on the encrypting devices. While this may not be a serious issue for common WAN interconnections, based on T1/E1 links (1.5/2 Mbps), it actually limits the adoption of IPSec in those contexts where preserving bandwidth is an essential requirement and link capacities are around 34/45 Mbps (T3/E3 links) or higher (Fast or even Gigabit Ethernets running at 100/1000 Mbps). Furthermore, certain applications may suffer from the increase in latency (i.e., the time required to pass through an IPSec network device) due to the extra processing.
Applied Cryptography, by Bruce Schneier, is an excellent and deep introduction to cryptography issues and algorithms.
Cryptonomicom, by Neal Stephenson, is a good novel romance deeply related to cryptography.
IETF RFCs 2401-2411, RFC 2451, and others (available from www.ietf.org), specify the IPSec architecture and its components.
"OpenSSL Programming", Linux Journal, September 2001. Eric Rescorla gives an introduction on how to use SSL in your own programs.
"Problem Areas for the IP Security Protocols", Proc. 6th Usenix Unix Security Symposium, July 1996. Steve Bellovin explains, among other things, why using confidentiality without authentication is dangerous.
"The 101 Uses of OpenSSH: Part II", Linux Journal, February 2001. Mick Bauer introduces the basic concepts of public key cryptography.
Gianluca Insolvibile has been a Linux enthusiast since kernel 0.99pl4. He currently deals with networking and digital video research and development.
email: g.insolvibile@cpr.it

