
Introduction to Internationalization Programming
In the old days when only a few people used computers, they were, for the most part, English speakers. Today, computers are widely available, and differences in languages, traditions and cultures need to be reflected in the world of programming. This article introduces the GNU gettext system.
The idea of using the same program but changing its properties according to the cultural traditions of different peoples is called internationalization. However, because programmers like to make words shorter, instead of typing 20 characters they type only four: i18n. I18n means programming designed to handle many languages.
Once you've written an i18n program, you may want to add a new language. This is not an i18n problem. In general, you need a person who will translate messages from the program for a specific nation. This problem is called localization, or i10n. I10n refers to the implementation of a specific language for an internationalized software, or in other words, the creation of localized objects according to the specific region's rules.
Although each organization and company that designs and distributes software tries to implement this in its own way, in general, the i18n idea is simple. Software should be created with two parts in mind: common and nation-dependent. This second part is known as localized objects.
Hopefully, standards will make life more comfortable. The basic concept of locale was introduced by the ISO (International Standard Organization) with the C standard in 1990, which was expanded in 1995. POSIX also has rules for i18n, so the term POSIX locale is used together with National Language Support (NLS). Formally, NLS is not a part of POSIX but has some functions that help when using the POSIX locale. X11 has its own i18n implementation, but the common way for programmers is to move the X11 i18n/i10n “up a level” into the POSIX/NLS locale. [Other software has its own i18n and i10n. See “Bridging the Digital Divide in South Africa” for one way to handle it].
What should we take into account when speaking of locale? Of course, the name of the language, but that is not enough. Everybody knows there are differences between American and British English, so we also have to know where the particular language is used, or in other words, the territory, taking into account individual traditions and cultural rules.
Every language has its own system of writing, and sometimes even several. Languages have alphabets, or character repertoires, but computers deal with digits. So, a character should be associated with a digit. This kind of association is called a coded character set (CCS). There are plenty of them, and each has its own name, such as ASCII, ISO-8859-1, KOI8-U. Instead of CCS, the term charset is often used. There is no special standard for the name of a charset, so ISO-8859-1, ISO8859-1 and iso8859-1 all refer to the same thing. There are some definitions from IANA, the organization that also is responsible for the registration of charsets (see Resources). As you probably know, the X11 system has its own system for charset naming, and their document “Logical Font Description Conversion” (described in Jim Flower's article, see Resources) provides a good name and alias charset creating system.
Charsets are important. Some countries have several different charsets for the same language! In the Ukraine, for instance, the same text may be displayed nicely in koi8-u but may be absolutely unreadable if a terminal uses the Ukrainian charsets iso8859-5, cp1251 or Unicode. In those cases, we would have to convert the text from one charset into another.
In order to take all of this into account, the POSIX locale defines some things that all together are called locale categories. They are shown in Table 1. Knowing them is important; C functions work differently with different locales! Categories are reflected in shell as environment variables with the same name. An example of using LC_ALL is shown in Listing 1.
Listing 1. Example of Using LC_ALL
The syntax to build a locale name looks like this:
language[_territory][.codeset][@modifier]
where language is represented by two lowercase letters, such as en for English and fr for French; territory is represented by two uppercase letters, such as GB for United Kingdom and FR for France, and in these two cases, euro would be the modifier. So, you can change your locale by setting the corresponding environment variables. See Listing 1, where we use the programs date, cat and our example program, counter. Note, we use only language and territory; we cannot change the charset for the terminal with this command. Now imagine that the program messages are written in one charset but are output in another. POSIX does not have functions to determine the current charset, but XPG has nl_langinfo(). In some distributions, the man page for this function may be missing (Debian does not have it, but SuSE and Red Hat do). In any case, you can obtain additional information from /usr/include/langinfo.h. To determine the current charset, use the following code:
#include <locale.h>
#include <langinfo.h>
...
setlocale(LC_ALL,"");
printf ("Current charset = %s\n",
nl_langinfo(CODESET));
To convert from one coding into another for the correct output, you
can use the conv() function. For more details, consult
“Introduction to i18n” (see Resources).
In order to provide output information, a message catalog for that locale was created. This means that all software messages are kept separately from a program that may have (and must have) its own catalog. NLS provides a set of utilities for creating and supporting such catalogs, as well as functions for extracting information according to three keys: 1) program name, 2) current categories of locale and 3) pointer to a particular message to be output.
There are two general realisations of the NLS mechanism:
X/Open Portability Guide XPG3/XPG4/XPG5 with the functions catopen(), catgets() and catclose() and the gencat utility.
SUN XView with functions gettext() and textdomain(). The GNU Project has its own fully compatible release called GNU gettext.
Usually programs, as well as system libraries, use one (or even two) NLS systems.
Although XPG5 is included in the UNIX specification version 2, and all versions of UNIX systems support it, with Linux, GNU gettext is the most popular solution.
The POSIX locale has the following components:
Locale API, i.e., subroutines like setlocale(), isalpha(), etc.
Shell environment variables to manage locale categories.
The locale utility to get information about the current locale; see man locale for more details.
Objects of localization. The default directory for their location is /usr/share/locale/.
If you are going to write a real i18n program, it would be wise to think that you know nothing about a specific language and take charsets into account. Ideographic languages have many more than 26 letters: Japanese has about 2,000, and Chinese has about 5,000. To deal with such characters, the POSIX locale has multibyte and Wide Class (wchar_t). The latter is done for Unicode. To convert one into another, functions like mblen(), mbstowcs(), wctomb(), mbtowc() and wcstombs() are used. However, using Unicode is beyond the scope of this article.
Producing real multilingual software is a complex task. Hopefully, the GNU gettext system that now conforms with SUN XView, will help you write i18n programs.
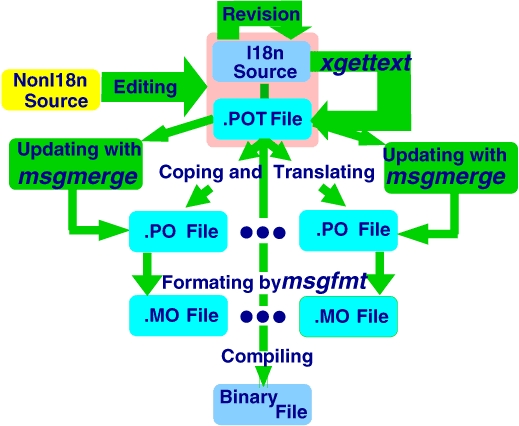
Figure 1. Producing an i18n Program
Figure 1 represents all necessary steps for producing an i18n program:
To create an i18n version, you have to edit a non-i18n program. If you use a special editor mode you will create an additional file at the same time, called a POT file, where PO stands for portable object, and the letter T is for template.
If you merely make a revision of an existing i18n program, or if a POT file does not exist, you have to use the xgettext program to produce it.
Copy the template file into ll.po, where ll refers to a certain language.
Translate messages into the language ll.
Create a ll.mo file with the msgfmt program (mo stands for machine object). Sometimes you can see gmo files (g stands for GNU).
Compile your source; put the binary program and ll.mo files into the right place. This and the previous steps are better accomplished with a Makefile.
Before looking briefly at all the steps of a simple program, please read these golden rules of internationalization:
1) Put the following lines into the non-executable part of your program, and mark messages in the source file as _("message") instead of "message" in the executable part of the program and N_("message") in the non-executable part. Pay attention to the output to guarantee passing the strings declared as constants through gettext, i.e., in the non-executable part:
#include <libintl.h> #include <locale.h> #define _(str) gettext (str) #define gettext_noop(str) (str) #define N_(str) gettext_noop (str)
2) Start your program by setting the locale:
setlocale (LC_ALL, "");3) Indicate the message catalog name, and if necessary, its location:
bindtextdomain(PACKAGE,LOCALEDIR); textdomain (PACKAGE);PACKAGE and LOCALEDIR usually are provided either by config.h or by the Makefile file.
4) To check a symbol's properties and conversion, use calls like isalpha(), isupper(), ..., tolower() and toupper().
5) To compare strings, use the strcoll() and strxfrm() functions instead of strcmp().
6) To guarantee portability with old versions of locale, use a variable of type unsigned char for symbols, or compile your program with the -funsigned-char key.
Let's make a simple internationalized program in which these rules are ignored (Listing 2). The program outputs an invitation to type, reads a string from the terminal and counts the digits in it. The results of this counting are output in the terminal, then the program exits.
Because the program is small, we can change it easily according to the rules with your favorite editor; if the program is large, it is better to use special tools. Editors like (X)Emacs or vi with po mode can create a counter.pot file at the same time that you are changing the program source!
The changed file is shown in Listing 3. Lines 4-8 are added according to rule 1. Definitions from the locale.h file may not be necessary; they may be included within the libintl.h definitions. Writing gettext and gettext_noop many times is annoying, so we will use macros, as defined in lines 6-8. Using gettext_noop is an example of pre-initialized strings at the compile stage. A possible solution is shown in our program where using gettext_noop allows the strings to be recognized by gettext at the time of executing.
Listing 3. I18n Version of the Program Shown in Listing 2
Without line 15 (rule 2), the program will not understand your locale and will use the C locale. Note that sometimes it is necessary to set special categories of locale, such as LC_CTYPE and LC_MESSAGES. See man setlocale and Table 1 in this article for more information.
Table 1. Categories of Locle and Shell Variables
Lines 16 and 17 were inserted according to rule 3. Usually the parameters of these calls are provided in either a Makefile or a special file (like config.h) that holds configuration information, but in this program we put in the names directly. According to line 16, searching will be started in the current directory. If the line with the call is omitted, Linux will use the default location, /usr/share/locale.
The call textdomain() must be presented in any i18n program. It points the gettext system to the filename with i10n messages.
Lines 19, 25 and 26 where changed according to rule 1. Lines 19 and 25 are simple: instead of using strings directly, we call them through gettext to use a message catalog. Line 26 demonstrates the exception. We cannot transform strings defined in the non-executable part through gettext because there the values are initialized before running the program by the compiler. The problem is solved according to rule 1. We marked the strings with N_ in line 12 to make them recognizable by xgettext; we used _(mess) instead of mess in line 26, as with normal strings. We do not need to do more, because of the function isdigit (see rule 4).
Now the program is internationalized. Compiling and running it, however, produces exactly the same result as the previous non-i18n one. Messages from the counter.pot file have to be translated into a specific language.
There is another way to create an initial .pot file. Once you have an i18n program, you can use xgettext. This scans the source files and creates corresponding strings for translation. In our case, we can invoke it like this:
xgettext -o counter.pot -k_ -kN_ counter.c
where -o is for output file name and -k_ -kN_ is to extract strings that start with corresponding symbols. Consult info xgettext to get more details.
Typically, a programmer works on the source code, and a translator deals with the corresponding .po file, which may be created with the copy command from the .pot file or directly from the source with the xgettext program.
Glance over a .po file, and you will see it has a header and entries for translating. Here is an example of an entry:
# This is my own commentary #: counter.c:25 #, c-format msgid "You typed %d %s \n" msgstr "Vous avez tapé %d %s\n"
It's simple. You translate phrases from msgid and put the results into the msgstr fields. If a line starts with #:, it is a reference to the source; if it starts with #, it shows an entry's attributes. You can add your own comments in lines starting with two symbols: # (the pound sign and then a white space).
After copying the template .pot file information (.po) or creating a new one with the xgettext command, you can start translating. Generally, this job can be done by another person using his or her favorite editor. (X)Emacs is not a bad choice for this job, but KBabel, part of KDE, is an even better one. If you are going to participate in a team of translators, it is highly recommended that you use KBabel. Describing KBabel is beyond the scope of this article, but you can read more about it in “The KBabel Handbook” (see Resources).
Translation is a kind of art. Writing a correct phrase can be difficult, and you sometimes may doubt your ability with a particular language. So, you may want to leave some entries untranslated, or having translated them doubtfully, mark them as “fuzzy”. With KBabel or (X)Emacs, you easily can find such entries and edit them again later. Do not worry; only fully translated entries will be compiled later by msgfmt and become usable in programs. This simply means that an entry may be marked “translated”, “untranslated” or “fuzzy”, and as software changes quickly, there is also an “obsolete” attribute.
Languages are flexible. English messages are not always perfect either. In our case, the message “You typed 0 digit” is incorrect. GNU gettext can manage translating problems like word order, plural forms and ambiguities, but you have to use extra functions that hold more arguments than gettext().
Once you have translated the file, you should convert it into a .mo file that gettext will use if you run the program with the corresponding locale. Do not forget to put this file in the right place, in our case:
mv counter.mo fr/LCMESSAGES/
Now the counter can speak French! (See Listing 1.)
Programs evolve, and if their source code is changed, the corresponding .po files also have to be updated. Using only xgettext in this case is not an ideal solution. All translated messages will be lost, because it overwrites .po files. In this case, you should use the program msgmerge. This program merges two .po files, keeps translations already made (if the new strings match with the old), updates entries' attributes and adds new strings. Of course, these new strings will be untranslated entries. A typical call is simple:
msgmerge old.po new.po > up-to-date.po
In this article, the input method is not described, although it is also important. Generally, non-X11 software doesn't need to worry about i18n input methods, because it is the responsibility of the console and X terminal emulators.
For input in X11, three methods exist: Xsi, Ximp and XIM. The first two are old-fashioned; the last one is the de facto standard. Their descriptions are beyond the scope of this article; however, the source code for the rxvt program provides an excellent example.
Modern tools provide their own special subroutines for input of internationalized strings, using gettext for output messages. To make program code 8-bit transparent for internal proposals, Unicode is used. Qt, for instance, works in such a way, providing additional functions for input and output of i18n strings correctly (see Resources).
You also may want to look at the source code of mutt, which is a good i18n program (www.mutt.org). This program supports aliases for charsets.
Using Unicode in your programs is described by Tomohiro Kubota (see Resources). Happy i18ning!

