
DSI: A New Architecture for Secure Carrier-Class Linux Clusters
Editor's note: This is the full version of the article "DSI: Secure Carrier-Class Linux" found in the July 2002 print edition of Linux Journal.
The telecommunication industry's interest in clustering originates from the fact that clusters address carrier-class characteristics such as guaranteed service availability, reliability and scaled performance, using cost-effective hardware and software. These carrier-class characteristics have evolved with time to include requirements for advanced levels of security. However, few efforts exist to build a coherent distributed framework to provide advanced security levels in clustered systems.
At Ericsson Research, our work targets soft real-time distributed applications running on large-scale carrier-class Linux clusters. These clusters must operate non-stop, regardless of hardware or software errors, and must allow operators to upgrade hardware and software during operation, without disturbing the application that run on them. In such clusters, software and hardware configurations are under the tight control of administrators. Communications between the nodes inside the cluster to computers external to the cluster are restricted.
In this article, we present the rationale behind developing a new architecture named the Distributed Security Infrastructure (DSI). We describe the main elements of this architecture and discuss our preliminary results.
DSI supports different security mechanisms to address the needs of telecom application servers running on Linux clusters. DSI provides applications running on clustered systems with distributed mechanisms for access control services, authentication services, integrity of communications and auditing services.
Many security solutions exist for clustered servers ranging from external solutions, such as firewalls, to internal solutions, such as integrity checking software. However, there is no solution dedicated for clusters. The most commonly used security approach is to package several existing solutions. Nevertheless, the integration and management of these different packages is complex, and often results in the absence of interoperability between different security mechanisms. Additional difficulties also arise when integrating these many packages, including the decreased ease of system maintenance and upgrades and the difficulty of keeping up with numerous security patches and upgrades.
Carrier-class clusters have tight restrictions on performance and response time. Therefore, much pressure is put on the system designer while designing security solutions. In fact, many security solutions cannot be used due to their high resource consumption. The currently implemented security mechanisms are based on user privileges and do not support authentication checks for interactions between two processes belonging to the same user (even if the processes are created on remote processors). However, for carrier-class applications, there are only a few users running the same application for a long period without any interruption.
Applying the above concept will grant the same security privileges to all processes created on different nodes. This would lead to no security checks for many actions through the distributed system. The granularity of the basic entity for the above security control is the user. For carrier-class applications, this granularity is not sufficient. Therefore, DSI is based on a more fine-grained basic entity: the individual process.
As part of a carrier-class cluster, DSI must comply with carrier-class requirements, such as reliability, scalability and high availability. Furthermore, DSI supports the following requirements:
Coherent framework: Security must be coherent through different layers of heterogeneous hardware, applications, middleware, operating systems and networking technologies. All mechanisms must fit together to prevent any exploitable security gap in the system. Therefore, DSI aims at integrating together different security solutions and adapting them to soft real-time applications.
Process level approach: DSI is based on a fine-grained basic entity, the individual process.
Maximum performance: The introduction of security features must not impose high performance penalties. Performance can be expected to degrade slightly during the first establishment of a security context; however, the impact on subsequent accesses must be negligible.
Pre-emptive security: Any changes in the security context will be reflected immediately on the running security services. Whenever the security context of a subject changes, the system will re-evaluate its current use of resources against this new security context.
Dynamic security policy: It must be possible to support runtime changes in the distributed security policy. Carrier-class server nodes must provide continuous and long-term availability, and it is thus impossible to interrupt the service to enforce a new security policy.
Transparent key management: Cryptographic keys are generated in order to secure connections. This results in numerous keys that must be securely stored and managed.
DSI introduces original contributions in the area of security on clustered systems. However, some parts, such as Access Control Service and the use of security contexts and identifiers, owe much to existing propositions, like Security Enhanced (SE) Linux.
DSI has two types of components: management and security services.
The DSI management components define a thin layer that includes a security server, security managers and a security communication channel (Figure 1). The service layer is a flexible layer that can be modified or updated through adding, replacing or removing services according to the needs of the cluster.
The security server is the central point of management in DSI, the entry point for secure operation and management and intrusion detection systems from outside the cluster. It is responsible for the distributed security policy. It also defines the dynamic security environment of the whole cluster by broadcasting changes in the distributed policy to all security managers.

Figure 1: DSI Architecture
Security managers enforce security at each node of the cluster. They are responsible for locally enforcing changes in the security environment. Security managers exchange security information only with the security server.
The secure communication channel provides encrypted and authenticated communications between the security server and the security managers. All communications between the security server and the outside of the cluster take place through the secure communication channel. Two nodes (to avoid a single point of failure) host the security server, and different security service providers, such as the certification authority, are hardened to maximize security. All connections from and to these nodes are encrypted and authenticated.
The security mechanisms are based on widely known, proved and tested algorithms. For the security mechanisms to be effective, users must not be able to bypass them. Hence, the best place to enforce security is at the kernel level; all security decisions, when necessary, are implemented at kernel level, the same as for the main security manager component, which has stubs into the kernel. In the Linux operating system, these stubs are implemented through load modules.
The DSI architecture at each node is based on a set of loosely coupled services (Figure 2).

Figure 2: DSI Services
The security manager controls different security services on the node. This service-based architecture has the following advantages:
The service implementation is separated from the rest of the system. By keeping the same API, the service implementation can be changed without affecting the application. However, an API for accessing security services is provided at user level for applications with special security needs (Figure 3).
It runs only predefined services according to the needs, performance issues or security environment. In addition, services can be replaced during runtime without major drawbacks on the running application. This enables the architecture to be modified and to resist changes throughout the system's lifetime.
It is possible to add, remove or update different services without administrative intervention. This reduces configuration errors due to the numerous security patches that need to be applied manually.

Figure 3: The Service-based Approach of DSI Inside Each Node
The security manager discovers the different services. Each service, upon its creation, sends a presence announcement to the local security manager, which registers these services and provides their access mechanisms to the internal modules.
There are two types of services: security services (access control, authentication, integration, auditing) and security service providers, which run at the user level and provide services to security managers.
The security server is the reference for all security managers and has the authority to declare a node to be compromised. It subscribes to all updates to keep its cache of different security contexts up to date, which makes it the ideal candidate for running Intrusion Detection Systems (IDSs). It has a local certification authority, as it certifies public keys for secondary certification authorities run by the security managers.
The primary tasks for security server include auditing, triggering alarms and warnings inside and outside the cluster, managing the distributed security policy and propagating security operation and management information.
The security manager enforces security on each node. It is primarily a lookup service to register different security services and service providers and connect them together. All communications between security managers and security servers pass through the secure communication channel.
The security manager is instantiated at boot time with digital signatures to make certain it is not replaced with a malicious security manager. Upon its creation, it joins the DSI framework and exchanges keys with the security server. Each security manager must publish any change to the security contexts of its local entities involved with remote entities and subscribe to changes in the security contexts of remote, related entities (see Section 8).
The primary tasks for security managers include key management, access control, process authentication, audit levels management, alarm publication, as well as maintenance and update of the locally stored distributed security policy.
The secure communication channel provides secure communications for the security components inside and outside the cluster. Within the cluster, it provides authenticated and encrypted communications among security components (Figure 4). It supports priority queuing to send and receive out-of-band alarms and is coupled to the security manager by an event dispatching mechanism.
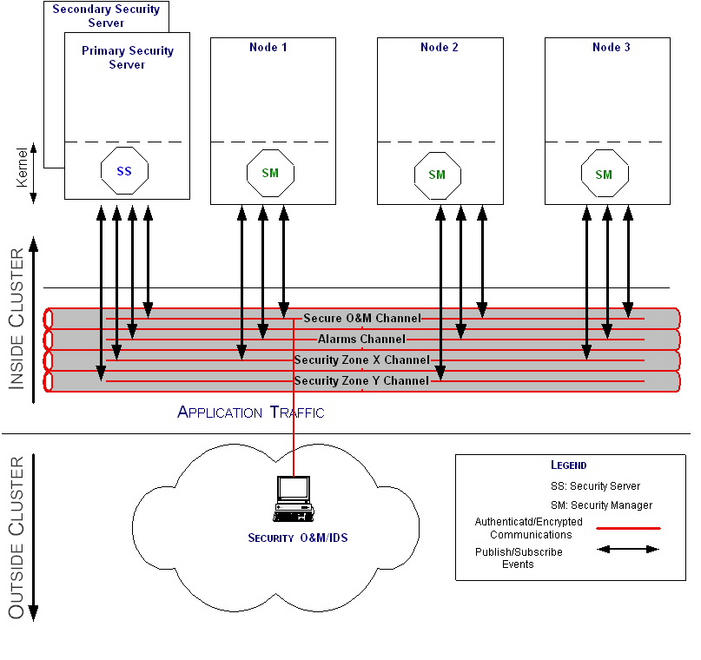
Figure 4. SCC is based on event-driven logic and different channels.
For large-scale clusters, an event-driven approach based on subscription to events from defined channels reduces the system load compared to the polling mechanisms. Further more, the benefits of this approach are:
It does not present a single point of failure.
It gives the possibility of event filtering, therefore less bandwidth is used and less time is needed for treating irrelevant information before discarding it.
The secure communication channel provides channels for alarms and warnings, security management, service discovery and distribution of the security policy. It also provides a portability layer to avoid dependency on low-level communication mechanisms.
For efficiency, a security identifier (SID) is defined as an integer that corresponds to a security context. All entities in the cluster have a SID. This SID is added at kernel level and cannot be tampered by users . It can be transferred across processors by security managers and interpreted through the whole cluster. Once the security context for a subject is needed outside the local processor (for instance, if this process accesses a remote object), its SID is sent to the security manager of the node containing the object. The SID propagation inside the cluster is based on SelOpt open source [6]. To avoid retransmissions, security managers rely on caching mechanisms. The security manager of the accessed node subscribes through SCC to the event of a possible change in the security context of the access initiator entity.
Security configuration must be kept simple. Following this approach, DSI relies on a centralized security policy stored and managed on the security server. However, to maintain the cluster's scalability, read-only copies of the policy are pushed from the security server to the individual security managers through the SCC. This Distributed Security Policy (DSP) is an explicit set of rules that governs the configurable behavior of DSI. Each node, at secure boot time, relies on a minimal security policy that is either stored in Flash memory or downloaded along with its digital signature. As soon as the DSP becomes available on a node, it prevails.
Many of the various DSI services and subsystems benefit from configurable behavior and can rely on DSP. They include mainly access control, then authentication, confidentiality and integrity, and packet filtering. The DSI administrator (a human being) manipulates the primary copy of the DSP that resides on the security server. Thus, it must be represented in a human readable format. The basic update mechanism for DSP is to push a full copy of each new version of the policy through the SCC. However, given the mere size that the policy can take, an incremental update mechanism will be made available.
There can be several possible originating sources for the security policy rules. Manual configuration by the DSI administrator allows for the most flexibility, but it rapidly becomes cumbersome. Thus, default policy rules are inferred from the nature of the various software packages installed and running on the system. These default rules codify good security practices. The DSP should only need to be updated because of events such as the installation of new software components; it should not be updated whenever ordinary recurring events occur.
A security session manager handles this kind of event by updating the security context repository. A security context defines privileges associated with each entity. It is defined uniquely through the whole cluster, but it is the responsibility of the security manager who created it.
In this section, we go further into details for access control, authentication and auditing services.
Access control can be defined as the prevention of unauthorized use of a resource [2]. It relies on the notions of subject (or access request initiator), object (or target), environment, decision and enforcement. The Access Control Service (ACS) assumes that the subjects have been properly authenticated (see the Authentication Service). DSI allows verifying the access control privileges even when subjects and objects are located on different nodes in the cluster. In order to simplify, we handle the access control in two levels: local when subject and object are on the same node and remote when they are on different nodes. For local access control, the access rights are the functions of the security IDs of the subject (SSID) and the object (TSID).
For remote access control, we extend the local access control mechanisms by adding a new parameter: the security node ID. Therefore, the access rights are not merely the functions of the subject and target security IDs, but as well, the function of the security node ID (SNID). The SSID along with the SNID are sent to the node containing the object. The security manager for the node of the object makes the access control decision based on SSID, SNID and TSID.
The ACS that runs on the cluster's processors is comprised of two parts:
A kernel-space part: Responsible for implementing both the enforcement and the decision-making tasks of access control. These two responsibilities are separated, as advocated by [1]. The kernel-space part maintains an internal representation of the information upon which it bases its decisions. On Linux, this part is implemented as a Linux Security Module (LSM).
A user-space part: This part has many responsibilities. It takes the information from the Distributed Security Policy and from the Security Context Repository, combines them together and feeds them to the kernel space part in an easily usable form. It also takes care of propagating back alarms from the kernel space part to the security manger, which will feed them to the Auditing and Logging Service and, if necessary, propagate to the security server through SCC.
Both parts are started and monitored by the local Security Manager (SM). The SM also introduces them to other services and subsystems of the infrastructure with which they need to interact.
The ACS aims to provide fine-grained access control (at a sub-system call level). It respects the minimization principles of least privilege to limit the propagation and damage caused by eventual security breaches. As such, it provides defense in depth.
The ACS running on a processor must make as few assumptions as possible about other processors, including whether they have been compromised. For that reason, an ACS instance is always the one making access decisions about resources that are local to its processor.
For the purpose of access control, system activities are categorized in distinct phases, each having its own set of permissions. These phases include software installation, software activation, software configuration and software execution.
For the initial design of the ACS, only grant/deny decision will be considered. Other more involved decisions would involve rate limiting and total usage limiting. Actions other than access control decision, such as interposition and active reactions, are not implemented either.
The authentication standard for now is the authentication by assertion. It means that the program accessing resources on remote processors asserts that it does this on behalf of a user. Neither the user schema nor the assertion on its own can be trusted seriously in an environment exposed to external attacks.
The authentication service is based on public key mechanisms and use of the SSL/TLS protocol. The public key infrastructure is based on a root certification authority accessed through the security server and secondary certification authorities running at every node and accessed through the security managers.
The certificates are generated and signed locally on each node by the security manager. The certificates are not stored in directories but in access-controlled zones of memory. A process can access only the corresponding certificate. The process does not access its private key directly, but use an API for cryptographic instead. Processes inside the cluster are authenticated through their corresponding certificates.
We detail different steps of the authentication:
Call interception: Upon first demand for opening a connection, the local SM intercepts the request.
SM verifies, with its local copy of DSP and SID of the process, if the process has the privileges to access the network.
If yes, SM asks the security service provider, key management service to generate a pair of keys and the corresponding certificate. Then, through the secondary certification authority, SM signs the public key with its private key and add its certificate as a chain certificate to the certificate for the process
SM puts the certificate in a defined, shared memory zone, then returns the pointer to the certificate to the demanding process. Notice that the shared memory zone where the certificates are stored is checked for access control purposes. When a process dies, the corresponding certificates are cleared.
Process proceeds to normal SSL/TLS connection with its certificate.
The SM in the target node checks the certificate and verifies it through the chain of certificates. Notice that the SM has the public key for the SS through the secure boot.
The auditing service provides the system with auditing capabilities. On the security manager side, the service is responsible for gathering traces, analyzing the traces, detecting the possible attack patterns, triggering the alarms and propagating them through SCC. It must be possible to modify the level of logging generated through security management systems. This service is responsible for functionality related to the lawful intercept.
This service has increased functionality on the security server. It also monitors the internal network for the cluster and the distributed logs in order to detect attacks. This service on the security server is related to external IDS through SCC. The auditing service is connected to external loggers when needed. The connection between the auditing service and external loggers is not through SCC for performance reasons.
The work described here distinguishes itself by being focused on the design of a security infrastructure targeted for clustered servers, as compared to previous work that focused on single computers or general-purpose clusters. In addition, DSI takes into account all of the issues related to security management starting at the design level.
Some of the related work includes CorbaSec, the CORBA security service that handles the security issues regarding access control and authentication for interactions between different objects. CorbaSec does not take into account all aspects of security for example detection and reaction mechanisms like DSI. On the other hand, Security Enhanced (SE) Linux from the National Security Agency (NSA) [3] and the Linux Security Module [4] (LSM) effort run on a single computer; they do not extend to a cluster.
Finally, Grid Security Infrastructure (GSI) was subsequently developed, based on existing standards, to address the security requirements that arise in Grid environments [5]. The DSI approach is more fine-grained and is based on modifying the OS to enhance security mechanisms (as explained previously). The approach of DSI is possible because the software and hardware configuration in the cluster is under tight control. In practice, DSI supports a coherent vision of security throughout the whole cluster as GSI supports secure interoperable mechanisms between different trust domains for multiple users.
So far, a secure boot mechanism for diskless Linux servers was implemented. Using secure boot with digital signatures, a distributed trusted computing base (DTCB) will be available as of the boot of the cluster nodes. The kernel at secure boot is small enough to be thoroughly tested for vulnerabilities. Furthermore, the use of digital signatures for binaries and a local certification authority will prevent malicious modifications to the DTCB.
We also implemented a security module based on Linux Security Module (LSM) that enforces the security policy as part of the DSI access control service. This module is integrated with SCC to implement distributed access control mechanisms. DSI currently supports pre-emptive and dynamic security policy at the process level throughout the whole cluster. Currently we are implementing the distributed security policy. To ease administration and maintenance of this policy, we are completing a study to devise methods to reuse information already contained in package management systems (such as RPM for Linux) in order to generate part of the security policy or to push such information to the package (if that is where it would be best specified). This effort also aims to use the policy to provide clearly different privileges during software, installation, configuration, activation, and execution. Specification of the exact language used to express the policy and of the compilation and loading mechanisms remains to be completed.
We have partly implemented a secure communication channel based on OmniORB, an open-source implementation of CORBA. SCC logics are implemented on top of a portability layer. This makes the implementation independent of any communication middleware used. The choice of CORBA as communication middleware for SCC was motivated by many factors, such as the support for distributed real-time and embedded systems and interoperability.
The Open Systems Lab at Ericsson Research started the DSI project to provide an architecture that supports different security mechanisms for telecom applications running on carrier class Linux clusters. The development direction is to make the DSI framework open source and to get people from different organizations and as well as open source initiatives involved in the design and development of the various components.
Figure 5 presents the various components of DSI. Currently at Ericsson Research we are working towards implementing the core DSI which includes the following components: Secure Communication Channel, Security Server, Security Manager, Access Control Service (including LSM module), Security Policy Generation, Security Session Manager and a Distributed Tracing of Event (as part of the Auditing Service).

Figure 5. DSI Components
All components with a question mark are open to design and development contribution.
We presented the need for a new security approach for telecom applications running on carrier class Linux clusters. Based on our motivations to develop a coherent solution addressing the security needs of Linux carrier class clusters, we proposed a new design for a secure distributed infrastructure. We presented the main elements of this design and discussed some of the preliminary results. We believe that this design is a practical approach to enhance security for large-scale clusters with carrier-class needs.
To complete DSI, we plan to collaborate with open source initiatives and other organizations. The DSI team from Ericsson Research will be available at the Ottawa Linux Symposium for three allocated presentations on DSI. We will also be available at the IEEE Cluster Conference 2002 in Chicago. In addition, Ericsson Research will be hosting the annual Open Cluster Group meetings June 24-25 in Montreal, which will give us the opportunity to address the members of the group and get them involved with the DSI project.
We are currently preparing a web site that will be available in late June. It will provide DSI technical reports, presentations, source code and links to web sites of other contributors. We encourage people interested in DSI to contact any of the DSI team members (listed below) to receive detailed papers on the DSI architecture, strategy, source code and to discuss collaboration opportunities.
[1] ISO 10181-3: "Security Frameworks for Open Systems: Access Control Framework", ISO, 1996.
[2] ITU-U Recommendation X.800: "Security Architecture for Open Systems Interconnection for CCITT Applications", ITU-T (then CCITT), 1991.
[3] Loscocco P.: "Security-Enhanced Linux", Linux 2.5 Kernel Summit, San Jose (Ca) USA, 2001, www.nsa.gov/selinux/docs.html.
[4] "Linux Security-Module (LSM) framework", 2001, lsm.immunix.org.
[5] Foster I., Kesselman C., Tsudik G., Tuecke G., "A Security Architecture for Computational Grids", 5th ACM Conference on Computer and Communication Security.
[6] Morris, J. "Selopt: Labeled IPv4 networking for SE Linux", www.intercode.com.au/jmorris/selopt
[7] Schreiner R., Lang U.: "MicoSec User's Guide", www.objectsecurity.com/micosec.html
Ibrahim Haddad is a Researcher at the Ericsson Corporate Unit of Research in Montreal, Canada. He is involved with the system architecture of third generation wireless IP networks and responsible for the IPv6 and a Security research activity at the Open Systems Lab.
Charles Levert works at the Ericsson Open Systems Lab in Montreal, Canada. He currently focuses on the topic of security in all-IP telecom clusters. He is a long-time user of and contributor to free software.
Makan Pourzandi works at the Ericsson Research Open Systems Lab as the Technical Leader for DSI. He received his doctoral degree on parallel computing in 1995 from the University of Lyon, France.
Miroslaw Zakrzewski works at the Ericsson Research Open Systems Lab. He is involved in research activities leading to the prototyping and development of carrier-class cluster access control mechanisms.
Marc Chatel is a member of the IS/IT network team of the Montreal, Canada, site of Ericsson Research.
Michel R. Dagenais is professor in the Computer Engineering Department, Ecole Polytechnique, Montreal, Canada. His research interests include distributed systems and software development tools.
David Gordon is a computer science intern from Sherbrooke University at the Ericsson Open Systems Lab.
Bruno J.M. Hivert is a system administrator at the Ericsson Corporate Unit of Research in Montreal, Canada, where he is involved in network and system administration for research laboratories, as well as Linux deployment.
Dominic Pellerin is a computer engineering intern from Sherbrooke University at the Ericsson Open Systems Lab.
email: ibrahim.haddad@ericsson.com
