
Smart (Script-Aided) Browsing
Basically, there are two ways to surf the Net: interactively, with any text or graphical browser, or in batch mode, with a program that copies single pages or whole web sites to your hard drive for later use. Script-aided browsing is that part of client side web scripting that makes your use of the Web more efficient and powerful by merging these two techniques in one of the two following ways.
In the first case, you run, either directly or as a dæmon, a script that downloads a web page, extracts from its source code an interesting URL and terminates, thereupon opening your favourite web browser to the corresponding page. Several examples of this first method, applied to Konqueror, Galeon and Netscape (Mozilla uses the same commands as its cousin) have been already described in my article "Client Side Web Scripting", published in the March 2002 issue of Linux Journal.
The second case, also mentioned in that article, is the opposite of the first. That is, during normal interactive web browsing, you notice an hyperlink pointing to an interesting page, and, from within your browser, you launch a web script that will automatically download that page and perform some more or less complex action on it. This action can be anything you can imagine: download all the images contained in that page, list in a pop-up window all the pages it points to and so on. You are limited only by your scripting skills.
Here's an example: mirror a web page and all the pages it points to. Let's assume that you just discovered some new, interesting program. On its home page, a link points directly to the voluminous subsection of the web site containing the complete user manual, and you want to mirror all of the information on your hard disk. The standard tool for these cases is wget, so we don't need to write a new one. However, how do we launch it directly from the web browser, without opening a terminal window and typing the URL by hand? The rest of this article explains how to automate this operation in Konqueror; the example has been tested with the standard KDE, Konqueror and wget tools that come with Red Hat 7.2.
Write a simple shell script that invokes wget with the -m (mirror) option on the first argument and call it wgetscript.sh (or whatever you want, of course). The content of my script is:
#!/bin/bash
/usr/bin/wget -m -L -t 5 -w 5 $1
exit
Put the script in the proper directory (I choose $HOME/bin and make it executable, chmod 755 <filename>.
Following the guidelines in this paragraph of the KDE user guide, www.kde.org/documentation/userguide/adding-programs.html, add the script to the KDE menu. Figure 1 shows what I had to write to accomplish this. The string "mymirror" is the one that actually appears in the menu, and the comment is self-explanatory. The really interesting thing in this picture, i.e., the bit of black magic absolutely essential for the correct working of the whole procedure, is the content of the "Command" box:
/home/marco/bin/wgetscript.sh %u
Apart from using the complete path to the script, what is important is the %u part; this is what will tell Konqueror to launch the script with the complete URL that we selected as the first argument. Notice also that I checked the Run in terminal option. In this way, a Konsole window will open and run your script, and it will be possible to see what happens.
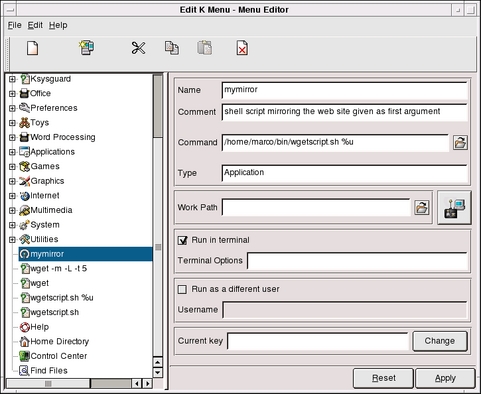
Figure 1. Adding wget to the KDE Menu
Now, to use this script from Konqueror, you have to right-click on the link that you want to mirror, (I choose the "Manuals online" link on the Free Software Foundation page for this example), and select the Open with.. option. Konqueror will open the window showed in Figure 2, which will you allow to choose "mymirror".
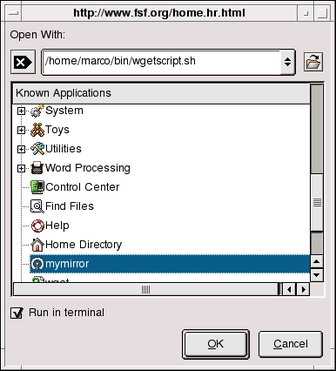
Figure 2. The Open with Option
That's it! Now Konqueror will open a Konsole and start the script with the complete URL ("wgetscript.sh http://www.fsf.org/manual/manual.html" in my example). You can browse some other page or do whatever you want, and when you're done, the pages you wanted to read will be available on your hard disk.
As shown in Figure 3, thanks to the -m (mirroring) option, wget will first download and save on disk the URL it was given, then parse it, download all the pages it points to and so on, recursively. Be very cautious with this (or any other automatic web navigation tool, for that matter), and consult the wget manual to tune it to your needs, proxy settings and bandwidth.
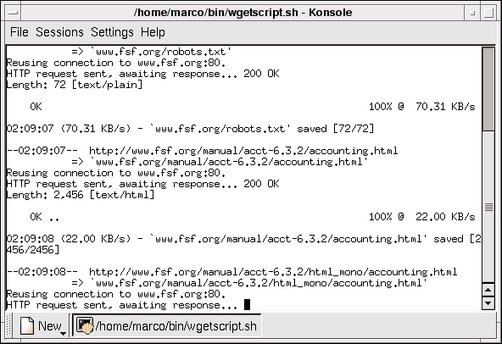
Figure 3. The wget Mirroring Option
When mirroring, wget creates a directory with the same name as the web server (www.fsf.org in this case) and puts everything in there. The last picture, Figure 4, is a listing of that directory made while wget was still working. As you can see, all the subdirectories present on the web site are preserved, and all the relative links are corrected automatically, to allow proper navigation among the mirrored pages.
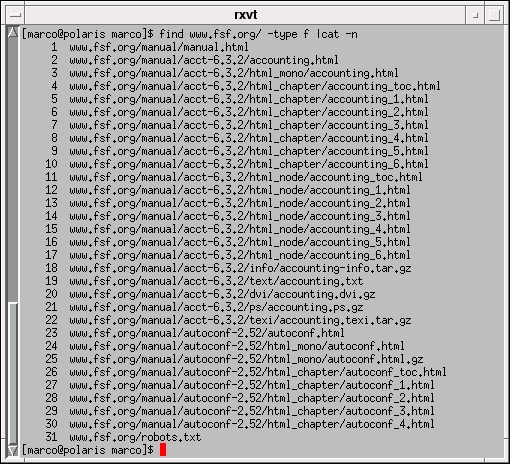
Figure 4. The Directory wget Mirrored
I have shown in detail how to launch shell scripts directly from Konqueror. How to do this is not one of the most documented features of Konqueror; at least, it's not the easiest one to find. I learned how to do this a couple of years ago, but I since lost my notes and spent half a day on the KDE and Konqueror site without success. I am really grateful to David Faure for giving me all the information I needed.
I am still trying to add this capability to other popular browsers, especially Mozilla and Galeon. I haven't had success so far, because (at least in the versions shipped with Red Hat 7.2) these browsers are missing the "Open with" menu option that made the trick on Konqueror. Any suggestions or pointers to relevant documentation is highly appreciated.
email: linuxdesk@inwind.it
