
Java Speech Development Kit: A Tutorial
The Speech for Java is a Java programming package, 100% object-oriented, that uses the speech recognition and synthesis technology known as ViaVoice, which was commercialized by IBM . This API makes it possible to build application interfaces that take advantage of speech.
The recognition and synthesis operations are not processed by the Java software. The kit is just a way to built speech-oriented interfaces. Applications "throw" speech processing to the software behind them, the IBM ViaVoice (commercial or free version).
In this way, just like any other interface programming models, the Speech for Java Development Kit (SDK) is also event-oriented. Now, however, these events are not fired by the mouse or the keyboard, they are created due to human speech via a microphone.
As mentioned the software is based upon two major features, speech synthesis and recognition. The recognition can be done through the use of grammars, which are entities providing information about how the recognition will be done. There are two kinds of grammars:
dictation: it's specially designed for continuous speech, when the software tries to determine what is being spoken using a large word database that associates a sound with each word. To increase accuracy and performance, contextual data is considered in order to establish the pronounced words. It is possible to use different dictation grammars for different domains, such as medicine, engineering or computer science.
rule: these grammars use rules, user's definitions of what might be spoken and how that will be interpreted by the application. The set of rules can take any size, but usually it is limited by the context in which the application is inserted. In this way, commands might be established in execution time to enhance responsiveness.
Voice synthesis might provide the application with simple string sentences as arguments to the method speak. An improved naturalness can be achieved via the use of a special markup language--Java Speech Markup Language (JSML). Through its use, properties like voice, frequency, rhythm and volume can be dynamically altered.
Figure 1. Simplified Architecture of the IBM SDK Java Technology
In figure 1, we can see that the sound hardware is controlled by the operating system. Right above it is the Engine.exe binary application, which is automatically initialized when the voice synthesis/recognition applications are started. The Engine is the heart of the IBM ViaVoice ( in the commercial or free versions). It is responsible for accessing all the ViaVoice's features.
Also, in figure 1, we can see the basic components of voice applications: the entities Recognizer and Synthesizer, the Central class and, especially, the Engine Interface, which is extended by the Synthesizer and Recognizer Interfaces. This interface has all the basic methods for controlling and accessing the ViaVoice processing engine.
The Engine Interface is important due to the fact that Java is a multiplatform language. For that reason, the same development kit is used on the UNIX, Linux and Windows systems, but each system has its own binary implementation of the IBM ViaVoice processing engine. The Engine interface hides the details of the platform-dependent software, offering proper access for the Recognizers and Synthesizers.
Now it is necessary to describe the Central class: it is in charge of implementing the Engine interface. The Central class is, in fact, responsible for abstracting platform details by providing the correct implementation of the Engine Interface. The recognizers and synthesizers extend the Engine Interface.
Figure 2. Full Architecture of the IBM SDK Java Technology
Below is a link to a code example that illustrates the most simple way to create an application with a recognizer and a synthesizer, with no working functionality.
The synthesizers, as their name indicates, are the entities responsible for speech synthesis. They are created through the use of the Central class, which implements the Engine interface and acts as a connection to the synthesis provided by the IBM ViaVoice technology.
Creating a voice synthesizer can happen in one of two ways, and both are use the Central class static method, createSynthesizer:
1. Accessing the default synthesizer of a determined locale is the most simple and common method. It usually establishes access to the synthesizer implementation distributed with the ViaVoice software. It might be done as shown with the code below.
Locale.setDefault("en","US");
Synthesizer sintethesizer =
Central.createSynthesizer(null);
2. Accessing a synthesizer that satisfies the conditions defined through the arguments passed on by the createSynthesizer method is the second way. This method is used in cases where more than one synthesizer is available. The parameters are:
name of the engine
name of the mode in which it will be used
a locale supported by the engine
a Boolean value, a control flag of the engine
an array of objects Voice that will be used
These parameters are defined creating an object SynthesizerModeDesc that will be passed to Central.createSynthesizer, as seen here:
public SynthesizerModeDesc(String engineName, String modeName, Locale locale, Boolean running, Voice[] voices)
Remember that any of the attributes can be null, and the Central class will be responsible for identifying the best synthesizer to fit the conditions.
Synthesizing voice: Once we have created the synthesizer, we can access its functions with the speak method. A simple String argument is enough for the basic features of synthesis, but there are other possibilities to increase naturalness of computer speech. The most powerful one of them is JSML (Java Speech Markup Language, covered in the next section), which provides various techniques to make the speech more similar to human voice.
Table 1 shows all the forms of the speak method:
Table 1. Methods Used for Voice Synthesis
Method | Function |
void speakPlainText(String text, SpeakableListener listener | Speak a plain text string. The text is not interpreted as containing the Java Speech Markup Language, so JSML elements are ignored. |
void speak(Speakable JSMLtext, SpeakableListener listener) | Speak an object that implements the Speakable interface and provides text marked with the Java Speech Markup Language. |
void speak(URL JSMLurl, SpeakableListener listener) | Speak text from a URL formatted with the Java Speech Markup Language. The text is obtained from the URL, checked for legal JSML formatting and placed at the end of the speaking queue. |
void speak(String JSMLText, SpeakableListener listener) | Speak a string containing text formatted with the Java Speech Markup Language. The JSML text is checked for formatting errors, and a JSMLException is thrown if any are found. |
The speakable objects are members of classes that implement the speakable interface. This interface has only one method, getJSMLText. This method specifies a JSML String to be returned when the object is submitted to the speak method. An example can be seen in the following sample code.
The SpeakableListener: To the methods of table 1, an extra element may be attached, a SpeakableListener. It will receive specific events for each pronounced word. Different events are generated during the synthesis process, and these events can be used to take control of the speech process, enabling a more interactive application. They indicate when a new word starts to be pronounced, if its synthesis was canceled and if it is over or was paused, among other events that allow the monitoring of the synthesis process.
The events are instances of the SpeakableEvent and are thrown by the synthesizer to be caught and treated by the listener. These entities carry information about the spoken word. More detail. The listeners are optional, and may be bypassed with a null argument to the synthesis methods.
The speakableListeners might be used in two ways:
associated with the listeners through the method speak, refer to table 1. This will define a listener for each item added to the items queue of the synthesizer. One listener might be shared by any number of queued items.
associated with the Synthesizer object through the addSpeakableListener method. This way the listener will receive the events of all the queued items in a determined synthesizer.
The listeners associated via the speak method will receive the events before the ones associated via the addSpeakable Listener.
The items queue: a synthesizer implements a queue of items provided to it through the speak and speakPlainText methods. The queue is "first-in, first-out" (FIFO)--the objects are spoken in the exactly order in which they were received. The object at the top of the queue is the object that is currently being spoken or about to be spoken. The QUEUE_EMPTY and QUEUE_NOT_EMPTY states of a Synthesizer indicate the current state of the speech output queue. The state handling methods inherited from the Engine interface (getEngineState, waitEngineState and testEngineState) can be used to test the queue state. The items on the queue can be checked with the enumerateQueue method, which returns a snapshot of the queue. The cancel methods allows an application to:
stop the output of an item currently on the top of the speaking queue.
remove an arbitrary item from the queue.
remove all items from the output queue.
The Voice: as an additional function of the synthesizers, we have the ability to choose the Voice that will be used in the synthesis. The parameters that must be provided are:
gender: GENDER_MALE, GENDER_FEMALE, GENDER_NEUTRAL and GENDER_DONT_CARE.
age: AGE_CHILD, AGE_DONT_CARE, AGE_MIDDLE_ADULT, AGE_NEUTRAL, AGE_OLDER_ADULT, AGE_TEENAGER and AGE_YOUNGER_ADULT.
To determine the association of the voice and the synthesizer, it is necessary to recover a SynthesizerProperties object through the getSynthesizerProperties method and determine the voice using setVoice. This can be more clearly understood in the following example code.
Java Speech Markup Language (JSML) is a markup language derived from XML and is used to describe an audio entrance in the synthesizers of the API. Its elements are able to supply detailed information about how to pronounce the text provided to the synthesizer. These elements describe the structure of a document (paragraphs, phrases), the words pronounced, text markers and prosodic elements that control phrasing, emphasis, pitch, speaking rate and other important characteristics. Appropriate markup of text improves the quality and naturalness of the synthesized voice.
JSML is used as arguments to the synthesizers and can be accessed through one of the forms of the method speak. It might be provided in a text file with the JSML formatted text or in small phrases as arguments for the method. Table 4 shows the JSML tags:
Table 2. JSML Tags
Element | Description | Example |
PARA | Determines that the marked text must be pronounced as a paragraph. | <PARA>This is a short paragraph.</PARA> <PARA>The subject has changed, so this is a new paragraph.</PARA> |
SENT | Determines that the marked text must be pronounced as a phrase. | <PARA><SENT>So long.</SENT><SENT>See you later.</SENT></PARA> |
SAYAS | Specifies how the marked text must be read. | <SAYAS SUB="0x0">zero draw</SAYAS> |
EMP | Determines the emphasis of the pronounce. The values might be: "strong", "moderate", "none", or "reduced". | <EMP LEVEL="reduced">Whispering is not polite.</EMP> |
BREAK | Determines a stop during synthesis. Milliseconds or size can be used: "none", "small", "medium", or "large". | <BREAK MSECS="300"/> or <BREAK SIZE="small"/> |
PROS | Determines the speech properties: volume (VOL absolute number between 0.0 and 1.0), rhythm (RATE in words per minute), frequency (PITCH in hertz), frequency interval (RANGE in hertz). | <PROS RATE= "50" VOL="+80%">Í'll repeat loud and clear, just one more time. </PROS> |
MARKER | When this tag is reached a markerReached event is triggered, this might be interpreted by a SpeakableListener. A tag MARKER can be positioned anywhere in the JSML text, making it possible to monitor the whole text being pronounced. | Answer <MARKER MARK="yes_no"/> yes or no. |
ENGINE | Provides information to the synthesizer identified by the ENGID, that will pronounce what is defined by the DATA parameter. If the synthesizer is not available, the marked text will be pronounced instead. | The frog does <ENGINE ENGID= "Frog_Sint1.0" DATA="ribbit=1"> improper synthesizer</ENGINE> |
The recognizers are the entities responsible for speech recognition. They are created through the Central class and are initialized using the allocate method. They process the audio entering in parallel to the main application.
The recognition is done with the help of a set of words that limit the universe of possibilities that can be pronounced by the user. These sets are extensible, and new words can be added, increasing the application functionality. The sets are known as grammars, and it is necessary to have at least one grammar associated with each recognizer.
When audio enters the recognizers, they try to determine an association between the spoken words and their associated grammars. The recognition process culminates on the creation of objects named results. Results have types ACCEPTED or REJECTED accordingly to the confidence level determined by the setConfidenceLevel method (the default value is 0.5).
In the same way as the synthesizers, the recognizers are created through the Central class in two possible ways:
1. Accessing the recognizer's default implementation that better fits the current locale. It is the simplest manner and the most common:
Locale.setDefault("en","US");
Recognizer recognizer =
Central.createRocognizer(null);
2. Accessing a recognizer that satisfies predetermined conditions, this method is used in cases where there are more than one recognizer implementation available. The required parameters are:
name of the engine
name of the mode in which it will be used
a locale supported by the engine
a Boolean value, a control flag of the engine
a Boolean value, indicating whether the recognizer supports dictation grammar
an array of SpeakerProfile objects
Any of the parameters might be null, and the Central class will try to make the best choice for them. These parameters are defined via a RecognizerModeDesc object, as shown here:
RecognizerModeDesc(String engine, String mode, Locale locale, Boolean running, Boolean dictationGrammarSupported, SpeakerProfile[] profiles)
The voice recognition is based upon a set of words (phonemes) named grammars. A created recognizer can have associated grammars, increasing its recognition domain according to the application needs. Having associated grammars, the recognizers generate result objects as answers to the recognition process. These results contain information about what was understood. This information is made available through ResultEvents fired by the results and caught by ResultListener, where the implementation determines what to do with the recognized data.
To implement this schema the recognizer can have two types of associated grammars, each one of them with its own word domain. They have distinct size and elements and determine a different recognition process:
Dictation grammars: these grammars are comprised of sets of words with thousands of elements. Their elements are determined by the function of their comprised domain, such as medicine, computer science or engineering. A general purpose grammar is available with the development kit.
Dictation grammars analyze the context of what is being spoken and try to limit the set of words that can be said next. Their use is specific to continuous dictating speech, such as texts and sentences. Great processing capacity is needed, therefore, and its use requires well projected applications.
The creation of a dictation grammar is done through a recognizer that supports its use. It is illustrated in here:
DictationGrammar dictationGrammar = recognizer.getDictationGrammar(null); dictationGrammar.setEnabled(true);Rule grammars: these are simpler than dictation grammars. They are comprised of rules that determine what can be said and how it will be represented inside the application. The rules are defined in a special format named JSGF (Java Speech Grammar Format) and can be loaded one at a time or many at once during execution.
Rule grammars require less processing capacity than dictation grammars and its recognition accuracy is much higher, resulting in a bigger number of accepted results. This is possible because of their limited scope of recognition. It is a grammar well suited for voice-command definitions, determining a specific set of commands for the various contexts of an application.
There are two ways to create a rule grammar:
through the loadJSGF method, when a set of rules is loaded from a text file; or
through the newRuleGrammar method, which returns an empty rule grammar that must be specified during execution.
Both methods belong to the recognizer interface, being the grammar automatically associated with the recognizer that created it.
The speech recognition systems make it possible for the computer to hear what a user says and "understand" what was spoken. Speech for Java does not yet support speech recognition without restrictions; the ability to hear any speech in any context and understand it accurately. To reach a reasonable accuracy and answer time, the recognition limits what might be said through the use of grammars, as seen in the previous section. The Java Speech Grammar Format (JSGF) language defines a way to describe what is named as a RuleGrammar. It uses a textual representation that might be read and edited by both developers and users through a simple text editor.
The rules have the following structure:
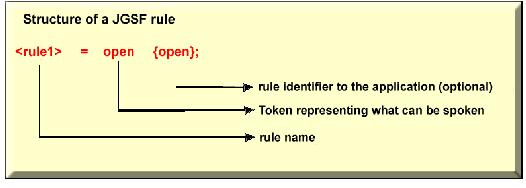
Figure 3. JSGF Rule Structure
If something is said and the recognition is not above a confidence level--defined through the use of the method setConfidenceLevel (the default is de 0.5)--a resultRejected rejection event will be triggered. Otherwise a resultAccepted event is created, and the method getTags returns the identifier(s) of the correspondent rule. Table 3 shows the main JSGF features:
Table 3. Main Uses of the JSGF Language
Use | Example | What Might Be Said | |
Simple words | <rule1> = open {open}; | "open" | |
Whole phrases | <rule2> = open the program {open}; | "open the program" | |
Multiple choices | <rule3> = open| open the program {open}; | "open" or "open the program" | |
Optional words | <rule5> = [please] open {open}; | "open" or "please open" | |
Rule referencing | <rule6> = <regra5> {open}; | The same as rule 5 | |
Enclosing operator * | <rule7> = 13579* times; | "1", "3", "5", "7", "9", "11", "13", "99", "93", or another number (including none) formed by 1, 3, 5, 7 and 9 in any order followed by times | |
Enclosing operator + | <rule8> = 13579+ times; | This time a number must be said following the pattern seen in rule7 |
The IBM ViaVoice Java technology is based on the same model used in graphic user interface (GUI) programming, that is, it depends on events generated by the user, events that are intercepted by listeners. These listeners are interfaces implemented by software developers, in this way any kind of processing can be triggered by specific speech events.
All speech events are derived from the class SpeechEvent, each one with specific information of the occurrence that fired it.
EngineListener: interface defining methods to be called when state-change events for a speech engine occur. To receive engine events an application attaches a listener by calling the addEngineListener method of an Engine. A listener is removed by a call to the removeEngineListener method.
=> Associated event: EngineEvent or one of its derived classes.
The main events treated are engineAllocated, engineAllocatingResources, engineDeallocated, engineDeallocatingResources, engineError, enginePaused and engineResumed.
They can be understood by observing Figure 4.

Figure 4. Engine States
The Engine's working cycle is shown in Figure 4: first the engine is created in DEALLOCATED state, to initially use it is necessary to call the allocate method. Then the engine passes to the temporary ALLOCATING_RESOURCES state, staying in this condition for a machine-dependent time; finally it reaches the ALLOCATED state with its substates: RESUMED (default) indicating engine activity and PAUSED indicating suspended activities, the transition between these states is possible using pause and resume methods. By the end of the engine use, it is recommended that the hardware resources be explicitly freed through the use of the deallocate method. After that the engine enters the DEALLOCATING_RESOURCES state and finally gets back to its initial DEALLOCATED state. Since recognizer and synthesizers inherit from the Engine Interface, they also follow this cycle.
For each of the five possible states a unidirectional transition causes an event to be fired, in a total of six events plus an engineError possible event. Namely, engineAllocated, engineAllocatingResources, engineDeallocated, engineDeallocatingResources, engineError, enginePaused and engineResumed.
SynthesizerListener: listener dedicated to treat the events generated during the synthesizer working cycle, more precisely during the synthesis function of the engine (see Figure 5).
=> Associated event: SynthesizerEvent or one of its derived classes.
Through this listener it is possible to take control of the synthesizer's items queue, which changes its state when:
a new item is added to the queue via the speak method.
an item is removed from the queue via the cancel method.
an item audio output is finished.
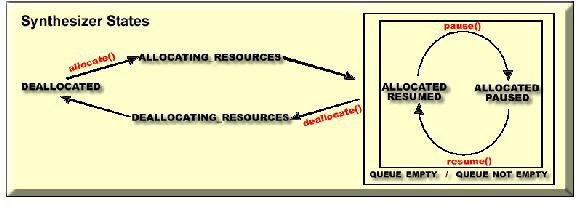
Figure 5. Synthesizer States
The differences between the synthesizer cycle and engine cycle are the substates of the ALLOCATED state: ALLOCATED RESUMED QUEUE_EMPTY, ALLOCATED RESUMED QUEUE_NOT_EMPTY, ALLOCATED PAUSED QUEUE_EMPTY and ALLOCATED PAUSED QUEUE_NOT_EMPTY. It must be observed that the queue condition is independent of the synthesizer working condition; items might be added or removed from the queue in both states RESUMED and PAUSED, so these new substates are not part of a cycle but just indicators of the queue state.
The possible events are:
queueEmptied: the speaking queue of the Synthesizer has emptied and the Synthesizer has changed to the QUEUE_EMPTY state. The queue may become empty because speech output of all items in the queue is completed or because the items have been canceled.
queueUpdated: the speech output queue has changed. This event may indicate a change in the state of the Synthesizer from QUEUE_EMPTY to QUEUE_NOT_EMPTY. The event may also occur in the QUEUE_NOT_EMPTY state without changing state. The enumerateQueue method of the Synthesizer will return a changed list. The speech output queue changes when:
a new item is placed on the queue with a call to one of the speak methods, or
when an item is removed from the queue with one of the cancel methods (without emptying the queue), or
when output of the top item of the queue is completed (again, without leaving an empty queue).
This listener inherits from the EngineListener interface and therefore the same events treated by this listener might be treated by the SynthesizerListener.
SpeakableListener: listener specially designed to treat events generated during speech synthesis. How to set it up:
Provide a SpeakableListener object when calling one of the speak or speakPlainText methods of a Synthesizer.
Attach a SpeakableListener to a Synthesizer with its addSpeakableListener method.
=> Associated event: SpeakableEvent or one of its derived classes.
The events that might be treated by the listener are:
markerReached: issued when audio output reaches a marker contained in the JSML text of a speech output queue item. The event text is the string of the MARK attribute. The markerType indicates whether the mark is at the opening or close of a JSML element or is an attribute of an empty element (no close).
speakableCanceled: issued when an item on the synthesizer's speech output queue is canceled and removed from the queue. A speech output queue item may be canceled at any time following a call to speak. An item can be canceled even if it is not at the top of the speech output queue (other SpeakableEvents are issued only to the top-of-queue item). Once canceled, the listener for the canceled object receives no further SpeakableEvents.
speakableEnded: issued with the completion of audio output of an object on the speech output queue as the object is removed from the queue. A QUEUE_UPDATED or QUEUE_EMPTIED event also is issued when the speech output queue changes because the speech output of the item at the top of the queue is completed. The SpeakableEvent is issued prior to the SynthesizerEvent.
speakablePaused: issued when audio output of the item at the top of a synthesizer's speech output queue is paused. The SPEAKABLE_PAUSED SpeakableEvent is issued prior to the ENGINE_PAUSED event that is issued to the SynthesizerListener.
speakableResumed: issued when audio output of the item at the top of a synthesizer's speech output queue is resumed after a previous pause. The SPEAKABLE_RESUMED SpeakableEvent is issued prior to the ENGINE_RESUMED event that is issued to the SynthesizerListener.
speakableStarted: issued at the start of audio output of an item on the speech output queue. This event immediately follows the TOP_OF_QUEUE unless the Synthesizer is paused when the speakable text is promoted to the top of the output queue.
topOfQueue: issued when an item on the synthesizer's speech output queue reaches the top of the queue. If the Synthesizer is not paused, the TOP_OF_QUEUE event will be followed immediately by the SPEAKABLE_STARTED event. If the Synthesizer is paused, the SPEAKABLE_STARTED event will be delayed until the Synthesizer is resumed.
wordStarted: issued when a synthesis engine starts the audio output of a word in the speech output queue item. The text, wordStart and wordEnd parameters define the segment of the speakable string which is now being spoken.
It must be observed that, SynthesizerListener extends the SDK Java API's EngineListener differently from the SpeakableListener that extends JDK API's EventListener. They have different natures; the former is related to synthesizer's working events (Engine application) and the latter is related to synthesis processing events.
RecognizerListener: listener dedicated to treat events generated during the recognizer working cycle, or more precisely, during the recognizing function of the Engine. Through its use it is possible to take control of the recognizer processing events.
=> Associated event: RecognizerEvent or one of its derived classes.
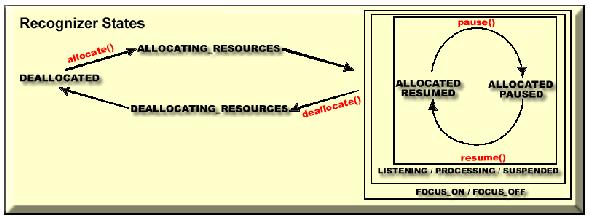
Figure 6. Recognizer States
The difference between the recognizer cycle (Figure 6) and the engine cycle are the substates of the ALLOCATED state: SUSPENDED, LISTENING and PROCESSING (Figure 7) that indicate the audio input processing state. SUSPENDED is the default state, which changes to the LISTENING state due to audio input. Then the PROCESSING state takes place.
The SUSPENDED state is also reached via the recognizer's suspend method. In this state the audio input is buffered for later processing. To leave this SUSPENDED state the commitChanges method should be called, then the LISTENING state is reached again.
Following we have the recognition cycle:

Figure 7. Recognition Cycle
The states FOCUS_ON and FOCUS_OFF are reached through requestFocus and releaseFocus methods. They indicate if the application has access to the Engine in the case where more than one application is running at the same time (just one can have access at the same moment).
Besides the Engine events, the following events can be generated:
changesCommitted: a CHANGES_COMMITTED event is issued as a Recognizer changes from the SUSPENDED state to the LISTENING state and resumes recognition. The GRAMMAR_CHANGES_COMMITTED event is issued to the GrammarListeners of all changed grammars immediately following the CHANGES_COMMITTED event.
focusGained: a FOCUS_GAINED event is issued as a Recognizer changes from the FOCUS_OFF state to the FOCUS_ON state. A FOCUS_GAINED event typically follows a call to requestFocus on a Recognizer. The GRAMMAR_ACTIVATED event is issued to the GrammarListeners of all activated grammars immediately following this RecognizerEvent.
focusLost: a FOCUS_LOST event is issued as a Recognizer changes from the FOCUS_ON state to the FOCUS_OFF state. A FOCUS_LOST event may follow a call to releaseFocus on a Recognizer or follow a request for focus by another application. The GRAMMAR_DEACTIVATED event is issued to the GrammarListeners of all deactivated grammars immediately following this RecognizerEvent.
recognizerProcessing: a RECOGNIZER_PROCESSING event is issued as a Recognizer changes from the LISTENING state to the PROCESSING state.
recognizerSuspended: a RECOGNIZER_SUSPENDED event is issued as a Recognizer changes from either the LISTENING state or the PROCESSING state to the SUSPENDED state. A result finalization event (either a RESULT_ACCEPTED or RESULT_REJECTED event) is issued immediately following the RECOGNIZER_SUSPENDED event.
The RecognizerListener extends the EngineListener interface, and therefore, the same events treated by it might be treated by the RecognizerListener.
RecognizerAudioListener: listener used to take care of operational audio events.
=> Associated event: RecognizerAudioEvent or one of its derived classes.
We have:
audioLevel: the AUDIO_LEVEL event indicates a change in the volume level of the incoming audio. This volume ranges from 0.0 to 1.0.
speechStarted: the recognizer has detected the possible start of speech in the incoming audio. Applications may use this event to display visual feedback to a user indicating that the recognizer is listening.
speechStopped: the recognizer has detected the end of speech or noise in the incoming audio that it previously indicated by a SPEECH_STARTED event. This event always follows a SPEECH_STARTED event.
GrammarListener: controls the events generated due to changes in grammar objects.
=> Associated event: GrammarEvent or one of its derived classes.
Its events:
grammarActivated: a GRAMMAR_ACTIVATED event is issued when a grammar changes state from deactivated to activated. The isActive method of the grammar will now return true. Grammar activation changes follow one of two RecognizerEvents:
The full details of the activation conditions under which a grammar is activated are described in the documentation for the grammar interface.a CHANGES_COMMITTED event in which a grammar's enabled flag is set true.
a FOCUS_GAINED event.
grammarChangesCommitted: a GRAMMAR_CHANGES_COMMITTED event is issued when a Recognizer completes committing changes to a grammar. The event is issued immediately following the CHANGES_COMMITTED event that is issued to RecognizerListeners. That event indicates that changes have been applied to all grammars of a Recognizer. The GRAMMAR_CHANGES_COMMITTED event is specific to each individual grammar. The event is issued when the definition of the grammar is changed, when its enabled property is changed or both.
grammarDeactivated: a GRAMMAR_DEACTIVATED event is issued when a grammar changes state from activated to deactivated. The isActive method of the grammar will now return false. Grammar deactivation changes follow one of two RecognizerEvents:
The full details of the activation conditions under which a grammar is deactivated are described in the documentation for the grammar interface.a CHANGES_COMMITTED event in which a grammar's enabled flag is set false.
a FOCUS_LOST event.
ResultListener: this is the main listener of all. It is responsible for listening to the events generated by the result objects that are created by the recognizers that work together with grammar objects. Implementing this interface enables the developer to determine what processing must be done to answer a specific event. It is associated with the ResultEvent objects that carry information about the recognizer, the grammar and the event.
The result objects carry information about the grammar to which it was associated, about the recognizer that created it, the strings named ResultToken representing what was said (when possible), information about the spoken sound on the form of an AudioClip and data that can be used for training the recognizer.
The possible result object states are:
FINALIZED:
ACCEPTED: the audio item was understood and an association with one of the active grammars was determined.
REJECTED: the audio item was understood, but the recognizer considers a high possibility of a mistake having been made. That means the recognizer was able to understand what was said (to associate a string, or token, meaning the heard sound), but there was not enough information to be sure of the recognition due to poor sound quality, a bad pronunciation or even due to hardware problems. These results must be carefully treated by the application.
UNFINALIZED: the audio item was understood and it's been processed, but it was not possible to determine an association with one of the active grammars.
=> Associated event: ResultEvent or one of its derived classes.
audioReleased: an AUDIO_RELEASED event is issued when the audio information associated with a FinalResult object is released. The release may have been requested by an application call to releaseAudio in the FinalResult interface or may be initiated by the recognizer to reclaim memory. The FinalResult isAudioAvailable method returns false after this event. The AUDIO_RELEASED event is only issued for results in a finalized state (getResultState returns either ACCEPTED or REJECTED).
grammarFinalized: GRAMMAR_FINALIZED is issued when the grammar matched by a result is identified and finalized. Before this event the getGrammar method of a result returns null. Following the event it is guaranteed to return non-null, and the grammar is guaranteed not to change. The GRAMMAR_FINALIZED event only occurs for a result that is in the UNFINALIZED state. A GRAMMAR_FINALIZED event does not affect finalized or unfinalized tokens.
resultAccepted: a RESULT_ACCEPTED event is issued when a result is finalized successfully and indicates a state change from UNFINALIZED to ACCEPTED. In the finalization transition, zero or more tokens may be finalized, and the unfinalized tokens are set to null. The isTokenFinalized and isUnfinalizedTokensChanged flags are set appropriately.
resultCreated: RESULT_CREATED is issued when a new result is created. The event is received by each ResultListener attached to the Recognizer. When a result is created, it is in the UNFINALIZED state. When created the result may have zero or more finalized tokens and zero or more unfinalized tokens. The presence of finalized and unfinalized tokens is indicated by the isTokenFinalized and isUnfinalizedTokensChanged flags.
resultRejected: a RESULT_REJECTED event is issued when a result is unsuccessfully finalized and indicates a change from the UNFINALIZED state to the REJECTED state. In the state transition, zero or more tokens may be finalized and the unfinalized tokens are set to null. The isTokenFinalized and isUnfinalizedTokensChanged flags are set appropriately. However, because the result is rejected, the tokens are quite likely to be incorrect. Since the result is finalized (rejected), the methods of Finalresult can be used.
resultUpdated: a RESULT_UPDATED event has occurred because a token has been finalized and/or the unfinalized text of a result has changed. The event is issued to each ResultListener attached to the Recognizer, to each ResultListener attached to the result, and if the GRAMMAR_FINALIZED event has already been released, to each ResultListener attached to the matched grammar.
trainingInfoReleased: a TRAINING_INFO_RELEASED event is issued when the training information for a finalized result is released. The release may have been requested by an application call to the releaseTrainingInfo method in the FinalResult interface or may be initiated by the recognizer to reclaim memory.
Detailed information of result objects are presented in the next section.
As mentioned, the result objects are created as answers to the recognition performed by the SDK Java. They are responsible for generating recognition result events or ResultEvents that might be intercepted by ResultListeners. These events are implemented in such a way that it is possible for the application to have access to the object that generated it (following the Java standard) through the getSource method. (The getSource method belongs to the java.util.EventObject class interface of which ResultEvent inherits.) In this context we will have a result object, or a descendent, returned.
The possible result object states are:
FINALIZED:
ACCEPTED: the audio item was understood and an association with one of the active grammars was determined.
REJECTED: the audio item was understood, but the recognizer considers a high possibility of a mistake having been made. That means, the recognizer was able to understand (to associate a string, or token, meaning the heard sound) what was said, but there was not enough information to be sure of the recognition, due to poor sound quality, a bad pronunciation or even due to hardware problems. These results must be treated carefully by the application.
UNFINALIZED: the audio item was understood and it is been processed, but it was not possible yet to determine an association with one of the active grammars.
Accept or Reject: rejection of a result indicates that the recognizer is not confident that it has accurately recognized what a user said. Rejection can be controlled through the RecognizerProperties interface with the setConfidenceLevel method. Increasing the confidence level requires the recognizer to have greater confidence to accept a result, so more results are likely to be rejected.
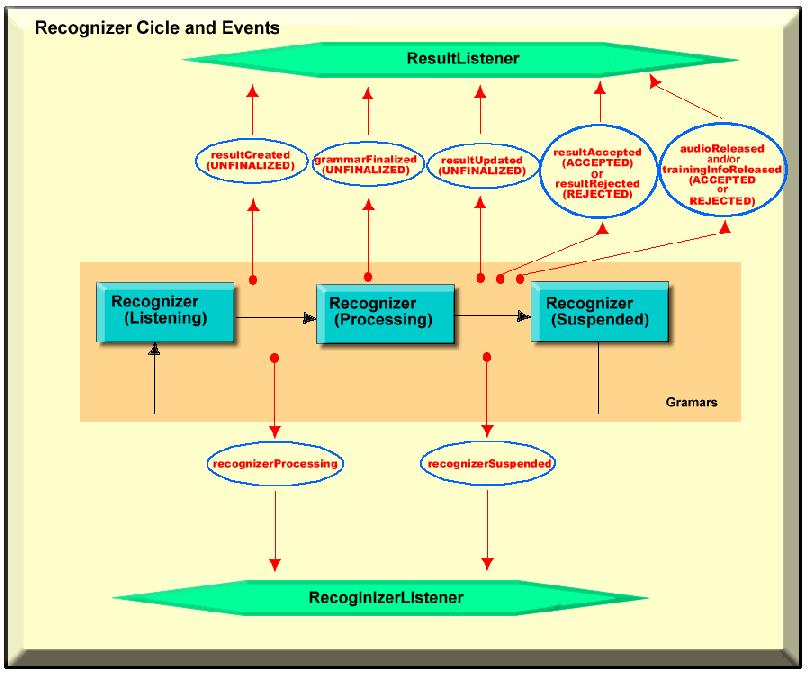
Below is an illustration of the recognition cycle and some of the fired events:
Figure 8. Recognition Cycle and Some of the Fired Events
By looking at the figure, we can establish the relationship between the result object states and the events (ResultEvent) that the listeners (ResultListeners) are able to intercept.
A RESULT_CREATED event creates a result object. A new result is started in the UNFINALIZED state.
UNFINALIZED state: RESULT_UPDATED events indicate a change in finalized and/or unfinalized tokens; a GRAMMAR_FINALIZED event indicates that the grammar matched by this result has been identified.
The RESULT_ACCEPTED event finalizes a result by indicating a change in state from UNFINALIZED to ACCEPTED.
The RESULT_REJECTED event finalizes a result by indicating a change in state from UNFINALIZED to REJECTED.
In the finalized states (ACCEPTED and REJECTED), the AUDIO_RELEASED and TRAINING_INFO_RELEASED events also may be issued.
The result objects are:
Result: the most primitive form of a created result. This form is used until the recognition cycle is finished, before all the information relating to a certain audio entrance is available. The substates might be FINALIZED or UNFINALIZED.
FinalResult: created when we have all the information relating to a certain audio entrance, that is, it is a complete result able to supply all the possible data as a consequence of a complete recognition. Its substates are ACCEPTED or REJECTED (always FINALIZED).
The information available in a result is determined by the type of grammar to which it was associated. Therefore, completing the model, the FinalResult interface is inherited by two other interfaces exclusively implemented by the recognizer for a certain finalized result, they are:
FinalRuleResult: the final result in consequence of an audio entrance associated to a RuleGrammar, with the substates ACCEPTED or REJECTED (FINALIZED).
FinalDictationResult: the final result in consequence of an audio entrance associated to a DictationGrammar, with the substates ACCEPTED or REJECTED (FINALIZED).
This schema is useful on the following situations:
Makes it possible to have access to the created results before they are finalized, for that we use simple result objects.
We can have both types of grammars associated to the same recognizer. And, in certain moments, we might need information that is not relevant either to an association with a rule or to a dictation grammar, but simply for a finalized result. For that we can use the FinalResult interface without having to test the nature of the result.
Having two types of finalized results, we can have additional data referring to the type of the grammar associated, increasing the control of applications.
The API that is being studied is composed by three packages that form the voice Speech for Java SDK:
package javax.speech: has the basic interfaces and implementations for the Engine interface. It also implements the Central class providing access to all the other functions for creating the most important entities of the technology, the synthesizers and recognizers. It is the basis for the remaining packages, remembering that the recognizer and synthesizer interfaces extend the Engine interface. This package also has resources for managing the audio received by the Engine and, as a last feature, its SpeechEvent class is inherited by all the other events of the API.
package javax.speech.synthesis: has all the classes and interfaces used for the synthesis process. It also provides the Voice class that determines how the synthesis will take place.
package javax.speech.recognition: the largest of the packages, it implements the recognizing and grammar classes, given their close relation. Also, there are the result classes that are very important in this architecture.
The packages are presented in a jar file named ibmjs.jar and the compilation is possible only after adding its full filesystem pathname to the CLASSPATH system variable, as follows:
CLASSPATH = %CLASSPATH% ; .../ibmjs.jar
After that and the proper installation of the IBM ViaVoice software, it is necessary to execute the following command:
java com.ibm.speech.util.Install
You can download the free IBM ViaVoice SDK Java at www.alphaworks.ibm.com/tech/speech.
You can download the free IBM ViaVoice SDK for Linux at www-4.ibm.com/software/speech/dev/sdk_linux.html.
Java Speech Interface from Sun is available at java.sun.com/products/java-media/speech/.
See java.icmc.usp.br for more information.
The authors acknowledge the support for this work from the The Research Foundation of the São Paulo State-FAPESP .
José Rodrigues Júnior is a graduate student at the ICMC-USP University of São Paulo. Dr. Dilvan Moreira is a lecturer at the ICMC-USP.
email: dilvan@icmc.sc.usp.br
email: dilvan@icmc.sc.usp.br


{kind=link}
{kind=link}
{kind=link}