
Lowering Latency in Linux: Introducing a Preemptible Kernel
Performance measurements come in two flavors, throughput and latency. The former is like the width of an expressway: the wider the expressway, the more cars that can travel on it. The latter is like the speed limit: the faster it is, the sooner cars get from point A to point B. Obviously, both quantities are important to any task. Many jobs, however, require more of one quality than of the other. Sticking to our roadway analogy, long-haul trucking may be more sensitive to throughput, while a courier service may be more demanding on latency. Lowering latency and increasing system response, through good old-fashioned kernel work, is the topic of this article.
Audio/video processing and playback are two common beneficiaries of lowered latency. Increasingly important to Linux, however, is its benefit to interactive performance. With high latency, user actions, such as mouse clicks, go unnoticed for too long—not the snappy responsive desktop users expect. The system cannot get to the important process fast enough.
The problem, at least as far as the kernel is concerned, is the nonpreemptibility of the kernel itself. Normally, if something sufficiently important happens, such as an interactive event, the receiving application will get a priority boost and subsequently find itself running. This is how a preemptively multitasked OS works. Applications run until they use up some default amount of time (called a timeslice) or until an important event occurs. The alternative is cooperative multitasking, where applications must explicitly say, “I'm done!”, before a new process can run. The problem, when running in the kernel, is that scheduling is effectively cooperative.
Applications operate in one of two modes: either in user space, executing their own code, or within the kernel, executing a system call or otherwise having the kernel work on their behalf. When operating in the kernel, the process continues running until it decides to stop, ignoring timeslices and important events. If a more important process becomes runnable, it cannot be run until the current process, if it is in the kernel, gets out. This process can take hundreds of milliseconds.
The first and simplest solution to latency problems is to rewrite kernel algorithms so that they take a minimal, bounded amount of time. The problem is that this is already the goal; system calls are written to return quickly to user space, yet we still have latency problems. Some algorithms simply do not scale nicely.
The second solution is to insert explicit scheduling points throughout the kernel. This approach, taken by the low-latency patches, finds problem areas in the kernel and inserts code to the effect of “Anyone need to run? If so, run!” The problem with this solution is that we cannot possibly hope to find and fix all problem areas. Nonetheless, testing shows that these patches do a good job. What we need, however, is not a quick fix but a solution to the problem itself.
A proper solution is removing the problem altogether by making the kernel preemptible. Thus, if something more important needs to run, it will run, regardless of what the current process is doing. The obstacle here, and the reason Linux did not do this from the start, is that the kernel would need to be re-entrant. Thankfully, the issues of preemption are solved by existing SMP (symmetric multiprocessing) support. By taking advantage of the SMP code, in conjunction with some other simple modifications, the kernel can be made preemptible.
The programmers at MontaVista provided the initial implementation of kernel preemption. First, the definition of a spin lock was modified to include marking a “nonpreemptible” region. Therefore, we do not preempt while holding a spin lock, just as we do not enter a locked region concurrently under SMP. Of course, on uniprocessor systems we do not actually make the spin locks anything other than the preemption markers. Second, code was modified to ensure that we do not preempt inside a bottom half or inside the scheduler itself. Finally, the return from interrupt code path was modified to reschedule the current process if needed.
On UP, spin_lock is defined as preempt_disable, and spin_unlock is defined as preempt_enable. On SMP, they also perform the normal locking. So what do these new routines do?
The nestable preemption markers preempt_disable and preempt_enable operate on preempt_count, a new integer stored in each task_struct. preempt_disable effectively is:
++current->preempt_count; barrier();
and preempt_enable is:
--current->preempt_count;
barrier();
if (unlikey(!current->preempt_count
&& current->need_resched))
preempt_schedule();
The result is we do not preempt when the count is greater than
zero. Because spin locks are already in place to protect critical
regions for SMP machines, the preemptible kernel now has its
protection too.
preempt_schedule implements the entry to schedule itself. It sets a flag in the current process to signify it was preempted, calls schedule and, upon return, unsets the flag:
asmlinkage void preempt_schedule(void)
{
do {
current->preempt_count += PREEMPT_ACTIVE;
schedule();
current->preempt_count -= PREEMPT_ACTIVE;
} while (current->need_resched);
}
The other entry to preempt_schedule is via the interrupt return path. When an interrupt handler returns, it checks the preempt_count and need_resched variables, just as preempt_enable does (although the interrupt return code in entry.S is in assembly). The ideal scenario is to cause a preemption here because it is an interrupt that typically sets need_resched due to a hardware event. It is not always possible, however, to preempt immediately off the interrupt, as a lock may be held. That is why we also check for preemption off preempt_enable.
Thus, with the preemptive kernel patch, we can reschedule tasks as soon as they need to be run, not only when they are in user space. What are the results of this?
Process-level response is improved twentyfold in some cases. (See Figure 1, a standard kernel, vs. Figure 2, a preemptible kernel.) These graphs are the output of Benno Senoner's useful latencytest tool, which simulates the buffering of an audio sample under load. The red line in the graphs represents the amount of latency beyond which audio dropouts are perceptible to humans. Notice the multiple spikes in the graph in Figure 1 compared to the smooth low graph in Figure 2.
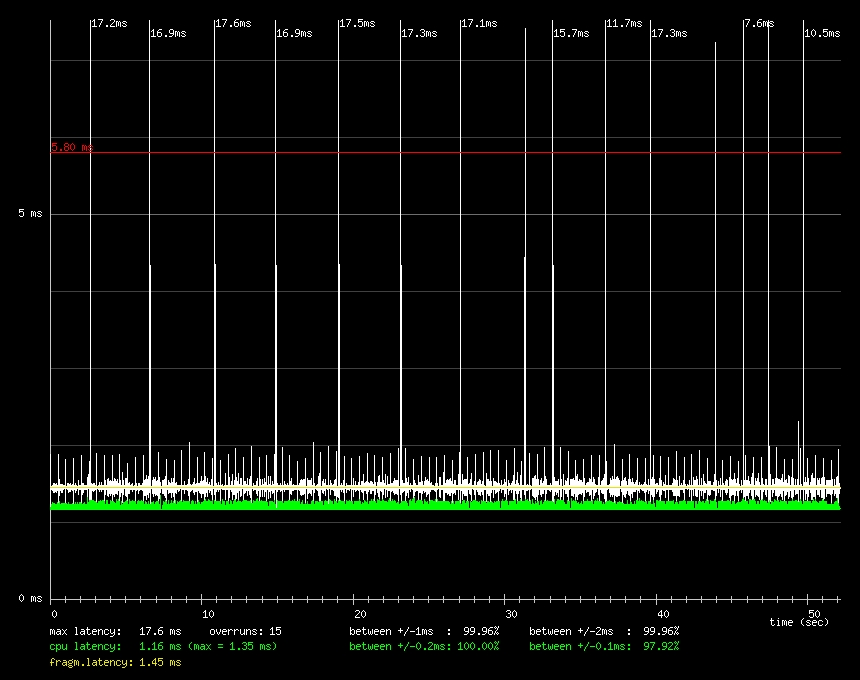
Figure 1. Result of a Latency Test Benchmark on a Standard Kernel
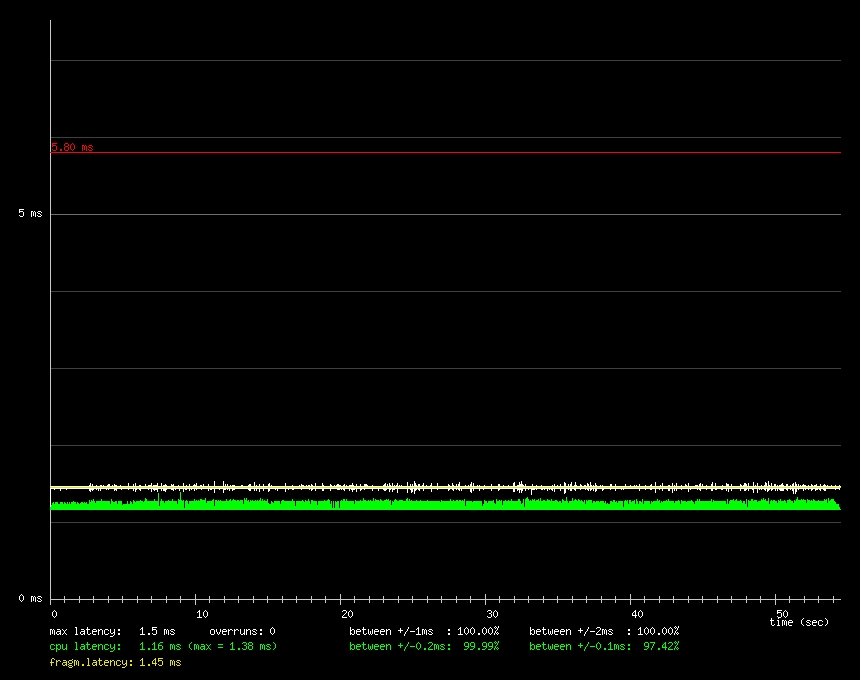
Figure 2. Result of a Latency Test Benchmark on a Preemptible Kernel
The improvement in latencytest corresponds to a reduction in both worst-case and average latency. Further tests show that the average system latency over a range of workloads is now in the 1-2ms range.
A common complaint against the preemptible kernel centers on the added complexity. Complexity, opponents argue, decreases throughput. Fortunately, the preemptive kernel patch improves throughput in many cases (see Table 1). The theory is that when I/O data becomes available, a preemptive kernel can wake an I/O-bound process more quickly. The result is higher throughput, a nice bonus. The net result is a smoother desktop, less audio dropout under load, better application response and improved fairness to high-priority tasks.
Kernel hackers are probably thinking, “How does this affect my code?” As discussed above, the preemptible kernel leverages existing SMP support. This makes the preemptible kernel patch relatively simple and the impact to coding practices relatively minor. One change, however, is required. Currently, per-CPU data (data structures unique to each CPU) do not require locking. Because they are unique to each CPU, a task on another CPU cannot mangle the first CPU's data. With preemption, however, a process on the same CPU can find itself preempted, and a second process can then trample on the data of the first. While this normally is protected by the existing SMP locks, per-CPU data does not require locks. Data that does not have a lock, because it is protected by its nature, is considered to be “implicitly locked”. Implicitly locked data and preemption do not get along. The solution, thankfully, is simple: disable preemption around access to the data. For example:
int catface[NR_CPUS];
preempt_disable();
catface[smp_processor_id()] = 1; /* index catface
by CPU number */
/* operate on catface */
preempt_enable();
The current preemption patch provides protection for the existing implicitly locked data in the kernel. Thankfully, it is relatively infrequent. New kernel code, however, will require protection if used in a preemptible kernel.
We still have work to do. Once the kernel is preemptible, work can begin on reducing the duration of long-held locks. Because the kernel is nonpreemptible when a lock is held, the duration locks are held corresponding to the system's worst-case latency. The same work that benefits SMP scalability (finer-grained locking) will lower latency. We can rewrite algorithms and locking rules to minimize lock held time. Eradicating the BKL will help too.
Identifying the long-held locks can be as difficult as rewriting them. Fortunately, there is the preempt-stats patch that measures nonpreemptibility times and reports their cause. This tool is useful for pinpointing the cause of latency for a specific workload (e.g., a game of Quake).
What is needed is a goal. Kernel developers need to consider any lock duration that extends over a certain threshold, a bug for example, 5ms on a reasonably modern system. With that goal in mind, we can pinpoint and ultimately eliminate the areas of high latency and lock contention.
The Linux community is large and diverse, and Linux is used in embedded systems all the way through large servers. Preemptive kernel technology provides benefits beyond real-time applications. Desktop users, gamers and multimedia developers alike stand to benefit from reduced latency. A solution is needed for both the 2.4 and 2.5 kernel trees; perhaps the same solution for each is not best. With 2.5 under development, however, now is the time to implement a feature that provides an immediate gain, as well as the framework for further improvement. The result will be a better kernel.


