
Highly Available LDAP
As an organization adds applications and services, centralizing authentication and password services can increase security and decrease administrative and developer headaches. However, consolidating any service on a single server creates reliability concerns. High availability is especially critical for enterprise authentication services, because in many cases the entire enterprise comes to a stop when authentication stops working.
This article describes one method of creating a reliable authentication server cluster. We use an LDAP (Lightweight Directory Access Protocol) server to provide authentication services that can be subscribed to by various applications. To provide a highly available LDAP server, we use the heartbeat package from the Linux-HA initiative (www.linux-ha.org).
We are using the OpenLDAP package (www.openldap.org), which is part of several Linux distributions, including Red Hat 7.1. Version 2.0.9 ships with Red Hat 7.1, and the current download version (as of this writing) is 2.0.11. The OpenLDAP Foundation was created as “a collaborative effort to develop a robust, commercial-grade, fully featured and open-source LDAP suite of applications and development tools” (from www.openldap.org). OpenLDAP version 1.0 was released in August 1998. The current major version is 2.0, which was released at the end of August 2000 and adds LDAPv3 support.
LDAP, like any good network service, is designed to run across multiple servers. LDAP uses two major features: replication and referral. The referral mechanism lets you split the LDAP namespace across multiple servers and arrange LDAP servers in a hierarchy. LDAP allows only one master server for a particular directory namespace (see Figure 1).
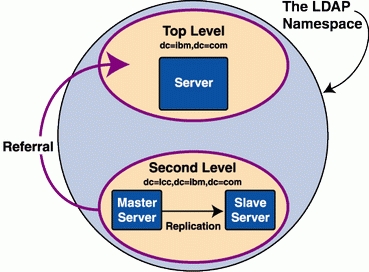
Figure 1. LDAP allows one master server per namespace.
Replication is driven by the OpenLDAP replication dæmon, slurpd, which periodically wakes up and checks a log file on the master for any updates. The updates are then pushed to the slave servers. Read requests can be answered by either server; updates can be performed only on the master. Update requests to a slave generate a referral message that gives the address of the master server. It is the client's responsibility to chase the referral and retry the update. OpenLDAP has no built-in way of distributing queries across replicated servers; you must use an IP sprayer/fanout program, such as balance.
To achieve our reliability goals we cluster together a pair of servers. We could use shared storage between these servers and maintain one copy of the data. For simplicity, however, we choose to use a shared-nothing implementation, where each server has its own storage. LDAP databases typically are small, and their update frequency is low. (Hint: if your LDAP dataset is large, consider dividing the namespace into smaller pieces with referrals.) The shared-nothing setup does require some care when restarting a failed node: any new changes must be added to the database on the failed node before restart. We'll show an example of that situation later.
To start, let's clear up a minor confusion. Most HA (high availability) clusters have a system keep-alive function called the heartbeat. A heartbeat is used to monitor the health of the nodes in the cluster. The Linux-HA (www.linux-ha.org) group provides open-source clustering software named, aptly enough, Heartbeat. This naming situation can lead to some confusion. (Well, it confuses us sometimes.) In this paper, we refer to the Linux-HA package as Heartbeat and the general concept as heartbeat. Clear, yes?
The Linux-HA Project began in 1998 as an outgrowth of the Linux-HA HOWTO, written by Harald Milz. The project is currently led by Alan Robertson and has many other contributors. Version 0.4.9 of Heartbeat was released in early 2001. Heartbeat monitors node health through communication media, usually serial and Ethernet links. It is a good idea to have multiple redundant media. Each node runs a dæmon process called heartbeat. The master dæmon forks child read and write processes to each heartbeat media, along with a status process. When a node death is detected, Heartbeat runs shell scripts to start or stop services on the secondary node. By design, these scripts use the same syntax as the system init scripts (normally found in /etc/init.d). Default scripts are furnished for filesystem, web server and virtual IP failovers.
Starting with two identical LDAP servers, several configurations can be used. First we could do a “cold standby”, where the master node would have a virtual IP and a running server. The secondary node would be sitting idle. When the master node fails, the server instance and IP would move to the cold node. This is a simple setup to implement, but data synchronization between the master and secondary servers could be a problem. To solve that, we can instead configure the cluster with live servers on both nodes. This way, the master node runs the master LDAP server, and the secondary node runs a slave instance. Updates to the master are immediately pushed to the slave via slurpd (Figure 2).
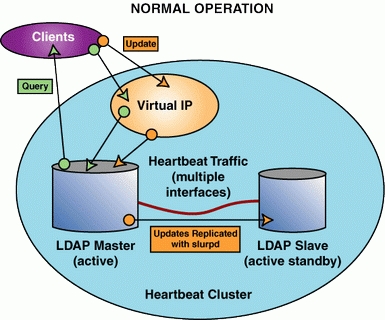
Figure 2. slurpd pushes updates from the LDAP master to the LDAP slave.
Failure of the master node leaves our secondary node available to respond to queries, but now we cannot update. To accommodate updates, on a failover we'll restart the secondary server and promote it to the master server position (Figure 3).
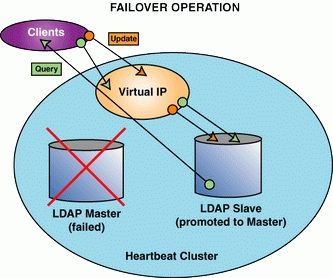
Figure 3. The LDAP slave restarts as the master.
This second configuration gives us full LDAP services, but adds one gotcha. If updates are made to the secondary server we'll have to fix the primary one before allowing it to restart. Heartbeat supports a nice failback option that bars a failed node from re-acquiring resources after a failover, an option that would be preferable. So, we'll show a restart by hand. Our sample configuration uses the Heartbeat-supplied virtual IP facility.
If heavy query loads need to be supported, the virtual IP could be replaced with an IP sprayer that distributes queries to both master and slave servers. In this case, update requests made to the slave would result in a referral. Follow-up on referrals is not automatic, so the functionality must be built into the client application. The master and slave nodes are identically configured except for the replication directives [see the Sidebar on the LJ FTP site, ftp.linuxjournal.com/pub/lj/listings/issue104/5505.tgz]. The master configuration file indicates the location of the replication log file and contains a listing of the slave servers, which are replication targets with credential information:
replica host=slave5:389 binddn="cn=Manager,dc=lcc,dc=ibm,dc=com"; bindmethod=simple credentials=secret
The slave configuration file does not indicate the master server. Rather it lists the credentials needed for replication:
updatedn "cn=Manager,dc=lcc,dc=ibm,dc=com"
Several good examples of basic Heartbeat configuration are available (see Resources). Here are the relevant bits from our configuration. Our configuration is quite simple, so there aren't many bits. By default, all configuration files are kept in /etc/ha.d/.
The ha.cf file that contains global definitions for the cluster is as follows:
# Timeout intervals keepalive 2 # keepalive could be set to 1 second here deadtime 10 initdead 120 # serial communications serial /dev/ttyS0 baud 19200 # Ethernet communications udpport 694 udp eth1 # and finally, our node ids # node nodename (must match uname -n) node slave5 node slave6
The file haresources is where the failover is configured. The interesting stuff is at the bottom of the file:
slave6 192.168.10.51 slapdWith this line, we have indicated three things. First, the primary owner of the resource is the node slave6 (this name must match the output of uname -n of the machine you intend to be the primary machine). Second, our service address, the virtual IP, is 192.168.10.51 (this example was done on a private lab network, thus the 192.168 address). Finally, we indicated that the service script is called slapd. Therefore, Hearbeat will look for scripts in /etc/ha.d/resource.d and /etc/init.d.
For the simple cold standby case, we could use the standard /etc/init.d/slapd script without modification. We'd like to do some special things, however, so we created our own slapd script, which is stored in /etc/ha.d/resource.d/. [The script itself is available from the Linux Journal FTP site at ftp.linuxjournal.com/pub/lj/listings/issue104/5505.tgz.] Heartbeat places this directory first in its search path, so we do not have to worry about the /etc/init.d/slapd script being run instead. But, you should check to be certain slapd is no longer started on boot (remove any S*slapd files from your /etc/rc.d tree).
In the startup script, we indicate two different startup configuration files for the slapd server, allowing us to start the machine as either master or slave. When the script runs, it first stops any instances of slapd currently running. Then, if both the primary and secondary nodes are up, we start slapd as master if we're running on the primary, or we start slapd as slave if we're running on the secondary. If only one node is up, no matter which node we're running on, we start slapd as master. We do this because the virtual IP is tied to the slapd master.
To accomplish this, we must know which node is executing the script. If we are the primary node, we also need to know the state of the secondary node. The important information is in the “start” branch of the script. Because we have indicated a primary node in the Heartbeat configuration, we know when the test_start() function runs, it is running on the Heartbeat primary. (Because Heartbeat uses /etc/init.d/ scripts, all scripts are called with the argument start|stop|restart.)
When calling a script, Heartbeat sets many environment variables. The one we're interested in is HA_CURHOST, which has the value slave6. We can use the HA_CURHOST value to tell us when we are executing on the primary node, slave6, and when we are in a failover (HA_CURHOST would be slave5).
Now we need to know the state of the other node, so we ask Heartbeat. We'll use the provided api_test.c file and create a simple client to ask about node status. (The api_test.c file does a lot more with the client; we simply removed the bits we didn't need and added one output statement.) After compiling, we installed it in /etc/ha.d/resource.d/ and named it other_state.
We can now start Heartbeat on both servers. The Heartbeat documentation includes some information about testing the basic setup, so we won't repeat that. With two heartbeat media, Ethernet and serial, connected, you should see six heartbeat processes running. To verify failover, we did several tests. To provide a client for testing, we created a simple KDE application that queries the servers and displays the state of the connection. A real client would query only the virtual IP in this instance, but we query all three IPs for illustration purposes. We send 10,000 queries per hour for this test (Figure 4).
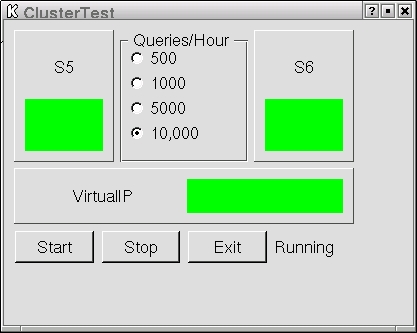
Figure 4. S6 (the master) and S5 (the standby) both running.
S6 is our master LDAP server, and Figure 4 shows that S5 is the active standby. The Virtual IP is the lower box. In the normal state, both S5 and S6 show green, indicating successful queries.
We start the test by stopping the heartbeat process on the master node. In this case the slave machine acquires the resources after the ten-second node timeout occurs, as shown in the log excerpt. The takeover includes an additional delay of two seconds inside the startup script (Figure 5).
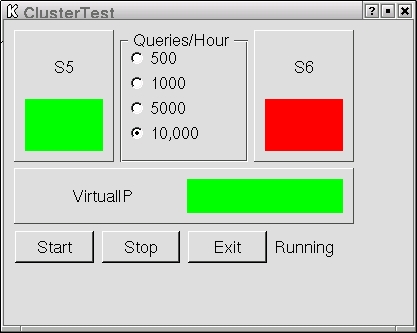
Figure 5. With the primary down, the secondary takes over the virtual IP address.
When the primary goes down, the virtual IP is serviced by the secondary, as shown in Figure 5. S5 and the virtual IP show green; server S6 is unavailable, and the indicator is red. After restarting the cluster, we created a failure by removing power from the primary node. Again the resources were acquired by the secondary node after the ten-second timeout expired.
Finally, we simulated a complete failure of the interconnects between the two nodes by unplugging both the serial and Ethernet interfaces. This loss of internode communication resulted in both machines attempting to act as the primary node. This condition is known as “split-brain”. The default behavior for Heartbeat in this case shows why it requires multiple interconnected media using separate media. In a shared-storage setup, the storage interconnect also can be used as heartbeat media, which decreases the chance of a split-brain.
This problem should be considered when choosing timeout values. If the timeout is too short, a heavily loaded system may falsely trigger a takeover, resulting in an apparent split-brain shutdown. See the Linux-HA FAQ document for more information on this.
If updates have been made to the LDAP namespace while the master LDAP server is down, the LDAP databases must be resynchronized prior to restarting the master server. There are two methods for doing this. If a service interruption is possible, the databases can be hand-copied after the LDAP server has been stopped. (Data files are kept by default in /usr/local/var.)
You also can use OpenLDAP replication to restore the database without the service interruption. First, start the LDAP server on the former master node as a slave. Then start slurpd on the current master. Changes received while the former master was out of service are pushed from the new master. Finally, stop the slave LDAP server on the former master node, and start Heartbeat. This results in a failback to the original configuration.
This article outlines a simple example of using open-source software to create some highly available basic network services. Network services including LDAP seldom require huge servers. The additional reliability provided by clustering and the duplication of servers and data files can increase overall service availability. The system worked under all tests, with a failover of less than 15 seconds in all cases. Given a good understanding of system loads and utilization, failover time could be reduced below this threshold.
Thanks to Alan Robertson, IBM Linux Technology Center, for his helpful comments and review.
The foregoing article is based on laboratory tests undertaken in a laboratory environment. Results in particular customer installations may vary based on a number of factors, including workload and configuration in each particular installation. Therefore, the above information is provided on an AS IS basis. The WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE EXPRESSLY DISCLAIMED. Use of this information is at user's sole risk.



