
Linux IPv6: Which One to Deploy?
IPv6, short for Internet Protocol Version 6, is the next-generation protocol designed by the IETF to replace the current version of Internet Protocol, Version 4 (IPv4). Most of today's Internet uses IPv4, which is now nearly 20 years old. IPv4 has been remarkably resilient in spite of its age, but it is beginning to have problems. Most importantly, there is a growing shortage of IPv4 addresses, which are needed by all new machines and devices connecting to the Internet.
IPv6 comes along to fix a number of problems in IPv4 and to add many improvements to cater to the future Internet. The improvements come in areas such as routing and network autoconfiguration, security and mobility. IPv6 represents a big package of capabilities, of which addressing is the most visible component. The addressing issue gets a lot of attention, but it is only one of many important issues that IPv6 designers have tackled. Other capabilities also have been developed in direct response to critical business requirements for scalable network architectures, improved security and data integrity, integrated quality of service, automatic configuration, mobile computing, data multicasting and more efficient network route aggregation at the global backbone level.
This article exposes part of the IPv6 work conducted within the ARIES Project (Advanced Research on Internet E-Servers) in the Open Systems Lab at Ericsson Research in Montréal, Canada. The ARIES Project started in January 2000 and aimed at finding and prototyping the necessary technology to prove the feasibility of a clustered internet server that demonstrates telecom-grade characteristics using Linux and open-source software as the base technology.
IPv6 is an essential technology to be supported on such telecom-grade systems and clusters. Ericsson's vision is that all mobile users in the near future will be “always connected, always on-line”. This new service paradigm, together with the use of IP technology, opens up tremendous opportunities for service providers and network operators to create new and diverse services. However, the rapid increase in the number of internet users combined with the expected growth in the number of wireless internet devices requires a scalable and flexible IP technology to accommodate such fast growth. Therefore, it is essential to recognize that IPv6 is a key technology to realize the vision of a large number of users being always connected, always on-line. New services, such as IP multimedia, assume globally unique addressing for reachability. IPv6, with its very large address space, will guarantee a globally unique IP address for each device.
This article explores the different open-source projects working on IPv6. The goal is to experiment with the Linux IPv6 implementations currently available and present recommendations to favor an implementation for our Linux processors on our near telecom-grade Linux clusters. The recommendations must be based on several criteria such as the implementation development speed, its compliance to the standards and its performance vs. other implementations.
The first step was to survey the Open Source community and report on the IPv6 projects that aim at providing IPv6 implementations, enhancing an existing implementation or providing testing and verification for other implementations.
The WIDE IPv6 Working Group (IPv6 WG), part of the WIDE Project, was started in 1995 in Japan for the purpose of experimenting with and deploying IPv6. In late 1995, IPv6 WG had several independent implementations and held interoperability test events. As the specification was verified and interoperability became common, it appeared that it was ineffective for IPv6 WG to implement IPv6 stacks independently. For this reason, the WIDE Project started the KAME Project as a subproject for combining the power of implementations.
Although the members of IPv6 WG and KAME overlap, IPv6 WG mainly does technical and innovative research, while KAME is in charge of implementation.
The WIDE IPv6 WG goals can be summarized as providing IPv6 implementation and software, encouraging the deployment of IPv6 in production environments and developing a transition mechanism from IPv4 to IPv6. In addition, the project aims at establishing the technologies and expertise for the administration of IPv6 networks.
The expected output of the project is a free IPv6/IPSec code conforming to the RFCs.
The KAME Project is a joint effort of seven companies in Japan to create a free, solid software stack for BSD variants (FreeBSD, OpenBSD, NetBSD and BSD/OS), targeted especially at IPv6 and IPSec. The project was formed to avoid unnecessary duplicated development and to deliver a high-quality and advanced feature-full implementation.
The project started in April 1998 and is planned to run until March 2002. The core researchers are from the following companies: Fujitsu Limited, Hitachi, Ltd., IIJ Research Laboratory, NEC Corporation, Toshiba Corporation and Yokogawa Electric Corporation. They have committed to work on the IPv6 stack on a full-time basis, making the project one of their primary tasks. Their goal is to implement the best networking code possible under BSD copyright and present their results as free software.
The expected project outcome is an excellent quality code (provided as free software) for IPv6 and IPSec (originally based on WIDE Hydrangea IPv6/IPSec stack), which will be the basis for advanced internetworking in the 21st century.
The TAHI Project started in October 1998 in Japan as a project between the University of Tokyo, YDC Corp. and Yokogawa Electric Co, with the objective of developing and providing the verification technology for IPv6 through research and development of conformance and interoperability tests. The group works in collaboration with the KAME Project on the quality side by offering the verification technology developed in the TAHI Project and improving the development efficiency. It's also important to note that the TAHI Project also receives great support from the WIDE Project.
The TAHI Project resulted in creating:
Conformance tests: the project releases its conformance test suites bimonthly. The release timing may be same as the KAME stable release.
Interoperability tests with simple network: these tests verify if your target node can work in some certain typical networks. Since this test will be conducted in limited environments, this is set as the first step of the interoperability tests.
Interoperability tests with a multi-implementation environment: these tests verify interoperability with the real world.
Test scenarios and test tools.
The results of the project are open to the public for free.
The USAGI (UniverSAl playGround for IPv6) Project works to deliver the production quality IPv6 protocol stack for Linux in collaborating with the WIDE Project, KAME Project, TAHI Project and the Linux IPv6 User's group. We will discuss the USAGI Project and its IPv6 implementation in a later section.
The IPv6-DRET Project is a public Linux implementation of IPv6, funded by the DGA/DRET (French Military Research Agency) and codeveloped by INRIA Sophia-Antipolis and LIP6 Paris. IPv6-DRET was based on the Linux kernel 2.1, and the goal of this implementation was to test certain algorithms relative to quality of service (QoS).
The objective was not to provide a full-fledged implementation, rather to build enough functionality to test certain algorithms relative to QoS. Since routing issues are among the most important research interests concerning IPv6, their network stack is intended to accommodate both host and router IPv6 machines. Besides implementing the router specification, a great deal of effort also was put into the development of RIPng into GateD.
The project is no longer in existence. The development has stopped and the code is outdated.
The Linux IPv6 RPM Project prepares RPM packages for the RPM-based Linux distributions (i.e., Red Hat Linux, Turbolinux and Caldera OpenLinux) that consist of the software and tools needed to connect to IPv6 networks. The aim of the project is to provide RPMs that make it easy to get IPv6 connectivity.
The Debian IPv6 Project is part of the Debian Project. It aims at converting some of the Debian packages to be IPv6-compliant.
As you may have noticed, among all the projects listed above, only two provided serious IPv6 implementations targeted for Linux: the Linux kernel implementation and the USAGI Project. In the following sections, we look in detail at these two projects and implementations and see which one complies more with the IPv6 specifications.
The USAGI Project aims at delivering a production-quality IPv6 stack for Linux and the experimental operation of an IPv6-compliant network using the developed software in tight collaboration with the KAME, WIDE and TAHI Projects.
The group is comprised of several organizations from private and academic sectors to promote the implementation and deployment of IPv6 for Linux. The group members are the WIDE Project, CRL, GLUON PARTNERS Co., Ltd., INTEC, Inc., Toshiba Corporation, Hitachi, Ltd., NTT Software Corporation, Yokogawa Electric Corporation, the University of Tokyo and Keio University.
The project started in October 2000 and is scheduled to end on March 31, 2002. The existing Linux kernel has its own IPv6 protocol stack; however, based on the evaluation results done by the TAHI Project, the quality of the current implemented IPv6 stack is not as good as the IPv6 stacks provided in other operating systems such as FreeBSD and Microsoft Windows 2000.
The project collaborates with other research and development projects and organizations regarding the IPv6 system development and deployment. The USAGI Project collaborates with the KAME Project (an IPv6 for the BSD UNIX system) and with the TAHI Project (an IPv6 test and evaluation specification and tools).
The USAGI implementation relies heavily on the KAME code, which is the IPv6 stack on various BSD systems, and most of their efforts are in the direction of enhancing the stack and porting it to Linux. Currently the USAGI Project has an IPv6 implementation for the Linux kernel.
The output of the project is a free IPv6 stack for the Linux kernel and much improved IPv6 APIs in the glibc library. The project released its second stable release on February 5, 2001, and snapshots of updated code are available every two weeks.
The Linux kernel has its own IPv6 implementation. However, as mentioned previously, based on the TAHI Project results, this implementation proved to be not as good as other implementations. However, this is not a big surprise given that no major development activity has happened for a while. Another factor is that the original writer of the Linux kernel IPv6 code, Pedro Roque, has left the community, and since then, Alexey Kuznetsov and others have made quite a few enhancements over the years; however, this is not a major development. The USAGI Project has submitted some small fixes, but the question of a complete integration with the kernel stack is still an open issue.
At this point, we already have two IPv6 test networks in our lab. One network had Linux nodes with the USAGI IPv6 stack and the other had Linux nodes with the kernel IPv6 stack. Much work has been put to perform the setup and solve routing and tunneling issues. However, the question was still which implementation to adopt.
To be able to answer this question objectively, Ericsson Research (Budapest) has performed conformance tests for the latest version of the official Linux kernel (at that time kernel 2.4.5) and the USAGI IPv6 implementation (based on 2.4.0). The tests were based on the University of New Hampshire InterOperability Lab IPv6 Test Description document (see Resources).
The result of each test case can be:
Pass: the implementation passes the test.
Fail: the implementation fails the test.
Inc: the verdict is inconclusive if we cannot decide whether the implementation is capable of passing the test. For example, when the test consists of three request/reply sequences and we do not get an answer for the tester's second request, then the verdict is inconclusive.
The Conformance Lab conducted four types of testing: basic specification, address autoconfiguration, redirect and neighbor discovery. Below, we explain these tests and present the results.
Basic specification: this series of tests covers the base specification for IPv6. The base specification specifies the basic IPv6 header and the initially defined IPv6 extension headers and options. It also discusses packet-size issues, the semantics of flow labels and traffic classes and the effects of IPv6 on upper-layer protocols (see Figure 1).

Figure 1. Specification Test Results
Address autoconfiguration: these tests cover address autoconfiguration for IPv6. They are designed to verify conformance with the IPv6 stateless address autoconfiguration specification (see Figure 2).

Figure 2. Address Autoconfiguration Test Results
Redirect: the redirect tests cover the redirect function of the neighbor discovery specification for IPv6. Redirect messages are sent by routers to redirect a host to a better first-hop router for a specific destination or to inform hosts that a destination is in fact a neighbor, i.e., on-link (see Figure 3).

Figure 3. Redirect Test Results
Neighbor discovery: these tests cover the neighbor discovery specification for IPv6. The neighbor discovery protocol is used by nodes (hosts and routers) to determine the link layer address for neighbors known to reside on attached links as well as to purge cached values that become invalid quickly. Hosts also use neighbor discovery to find neighboring routers that are willing to forward packets on their behalf. Finally, nodes use the protocol actively to keep track of neighbors that are reachable and those that are not. When a router or the path to a router fails, a host actively searches for functioning alternates (see Figures 4 and 5).

Figure 4. Neighbor Discovery Test Results

Figure 5. Test Result Summary
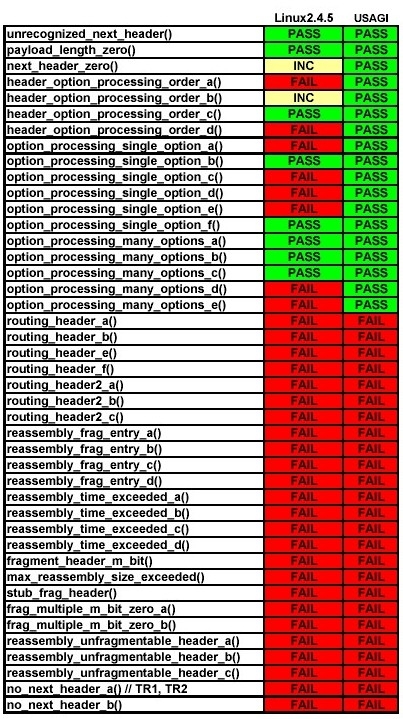

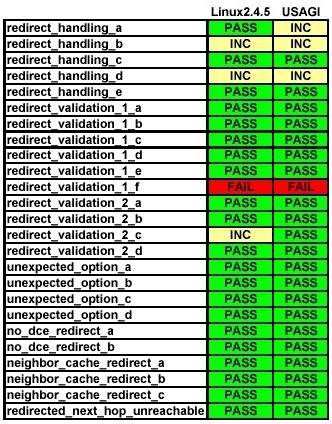
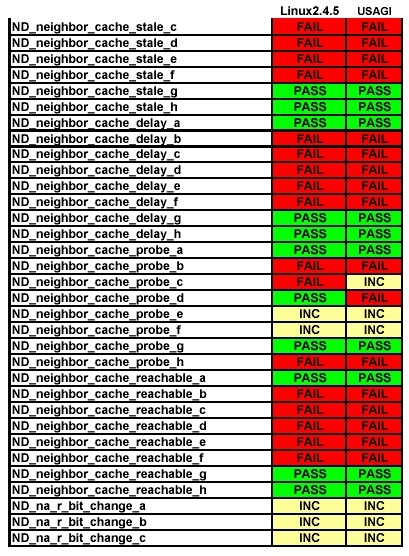
Based on these results, we can see that the USAGI implementation had better results than the Linux kernel implementation; it passed more tests, failed fewer tests and had less inconclusive cases than the Linux kernel implementation.
Typically, working on such assignments, a lot of learning and competence building takes place. However, there are always some special lessons that you learn along the way, and they are worth mentioning.
It always pays to simplify problems. For instance, it was not obvious to know why a ping6 was able to crash the Linux kernel (v. 2.4.5) while we were running three web servers (Apache, Jigsaw and Tomcat) with patched code for IPv6 support in addition to an Alpha version of Java Merlin 1.4. Things got clearer when we disabled these servers and the Java Virtual Machine.
Also, adopting a complete implementation is much easier and more flexible than deploying patches. In some cases, we were faced with some bugs, and it was not easy to tell where they came from. Was it the application's IPv6 patches, the USAGI IPv6 kernel patches or the IPv6 patched binaries? Simplifying the problem helped a lot but proved that it may be easier to adopt the complete integrated implementation rather than patches that are downloaded and applied individually.
One important issue to mention is that our experience with the Open Source community has been a very positive one. People working with open-source software do their best to help you fix bugs and answers e-mails quickly. Since most of the software we use on our Linux clusters is based on open source, sometimes we go back to the community with questions, and we had no problems getting support from the developers—an important factor to acknowledge.
The Linux kernel IPv6 implementation has not undergone any major development since 2.4.0 was released. In many cases, we were able to crash the kernel with IPv6 traffic. On the other hand, USAGI provides an IPv6 implementation for Linux that is ported from the FreeBSD IPv6 stack, which is one of the best IPv6 implementations currently available. It also has proved to be more stable and reliable, and had better conformance test results than the Linux kernel implementation. The conclusion that can be drawn is that the USAGI stack is at least more mature than the kernel implementation and provides more functionalities and compliance with the specifications.
If you want to make a decision as to which IPv6 implementation to deploy on your Linux servers based on different factors, such as the development status, the number of people working on it, the support it's getting from industry and academia and its compliance with the latest RFCs, then it is most likely that you will choose the USAGI IPv6 implementation. Nevertheless, there is an important concern related to both implementations. Unfortunately, a complete “implementation” document describing all the supported RFCs and motivations behind different design decisions does not exist.
I hope that the Linux kernel community and the USAGI Project can work together more tightly and organize their efforts to bring to pass a very stable and efficient IPv6 implementation for Linux. I believe the result would be a Linux kernel with a stable and well-written IPv6 implementation—a needed success formula for the future IPv6 servers contributing to the making of the mobile internet.
Open Systems Lab at Ericsson Research Canada for approving the publication of this article; Marc Chatel, Bruno Hivert and David Gordon at Ericsson Research Canada for their help and support in the lab; and Conformance Lab at Ericsson Research Hungary for conducting the conformance tests.


