
Using the Clone() System Call
Low-level C programming has always been seen as the arena of the "guru". In my upper level operating systems course, the professor thought this was an idea that should be wiped from our minds. To this end, we had quite a few programming assignments that pushed us into totally new territories. One of these assignments was to research and use the clone() system call provided by Linux. Finding information on the low-level system calls provided by Linux was no easy task. Hopefully, this article will save any other budding guru-wannabees some time and trouble.
C programmers in the UNIX world have long used the fork() system call. This call is the basis of multiprocessing, as this is how new processes are created. Actually, for most systems, this is the only way to create a new process. Linux has introduced a new call, clone(), which allows a new level of process context creation.
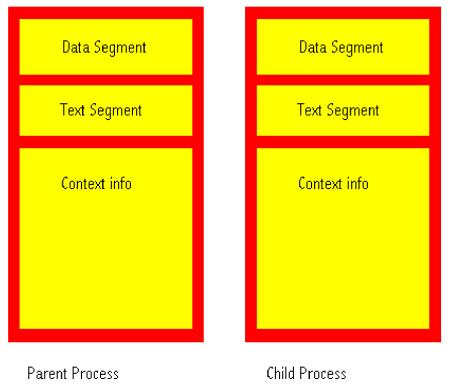
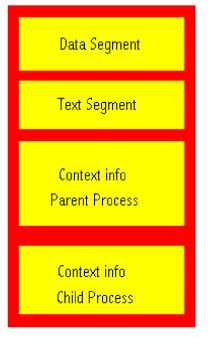
Processes come in two basic flavours, heavy-weight and light-weight. Heavy-weight processes are those that you normally think of when you run a program. They contain their own address space and program execution context (see Figure 1). Light-weight processes are normally thought of as threads. These light-weight processes share the address space of the parent, and only contain some subset of the context elements (see Figure 2).
Before looking at the clone() system call, I'll begin with a quick review of fork. This system call, along with the class of exec system calls (i.e., execl(), execlp(), execv(), execvp()) is actually the way your shell executes programs given on the command line. A simple example of using fork() is given in Listing 1. The parent opens a file, assigns a value to a variable and forks a child. The child then tries to change the variable and close the file. After exiting, the parent wakes up and checks to see what the variable is and whether the file is open.
As you can see, the child is in a totally new address space. Within this address space, the child process receives a copy of everything the parent had at the point of forking. (This isn't exactly true in Linux. The child only receives a new copy of a memory page when it tries to make a change to something in that page. Until then, it simply uses the parent's copy. This is called copy-on-write memory management.) Changes to this copy do not affect the parent. When the child tries to change the value of the variable, the parent doesn't see this change.
How would you write a similar program using the clone() system call? Listing 2 gives a very basic program that looks like it copies the behaviour of the program using fork(). The most obvious difference at this stage is the fact that the clone() system call leaves all memory management up to the programmer. The first thing to be done is allocating space for the stack of the new child thread with malloc(). Once this is done, the clone() call is issued to begin a new context of execution, starting at the beginning of the given function. The general signature of this system call is
int __clone(int (*fn) (void *arg), void *child_stack, int flags, void *args)
As you can see, there are several parameters to prepare. The first parameter is a pointer to a function which returns an integer. In C, function names are pointers to functions, so this is easily taken care of. The second parameter is a pointer to the stack space that was set up for the child. You will have to decide how much space is required for the operations the child process will perform. The last parameter is a pointer to the arguments that will pass to the function that the child process will execute. In this case, that is a null pointer, since we aren't passing any arguments to the function.
The third parameter deserves special attention. This is where you can designate the flags which will define how much of the process context will be shared between the child and the parent. As in most C functions, multiple flags are simply read together. The flags available to the clone call are:
CLONE_VM - share memoryCLONE_FILES - share file descriptorsCLONE_SIGHAND - share signal handlersCLONE_VFORK - allow child to signal parent on exitCLONE_PID - share PID (not implemented yet)CLONE_FS - share filesystem
You can see that we've set up our sample program with CLONE_VM and CLONE_FILES. Looking at the output of the program, you can see that the child process will share the address space and file descriptor table with its parent. Any changes made by one process are now visible to the other. If the exact behaviour of fork() was required, all that needs to be changed is which flags are set. This way, you get to choose the exact level of sharing your program will use.
There are a few caveats I should mention in using this system call. Several functions, such as printf(), which are not thread-safe when used with clone(). These functions assume the kind of wrapping that occurs when using thread libraries, like linuxthreads. If you are experimenting with a program and run into segfaults or coredumps, this would be a likely place to look to start your troubleshooting. A possible solution would be to use lower level system calls, such as write() instead of printf(). Also, you should compile programs using the -static switch.
I am in debt to the good folks at Red Hat for pointing out some pitfalls while I stumbled my way through this article. Any errors in this article are entirely the fault of the author, and I would appreciate any corrections that you think should be made.
email: ljeditors@ssc.com


{kind=link}
{kind=link}