
The Subversion Project: Buiding a Better CVS
If you work on any kind of open-source project, you've probably worked with CVS. You probably remember the first time you learned to do an anonymous checkout of a source tree over the Net, your first commit or learning how to look at CVS diffs. And then the fateful day came: you asked your friend how to rename a file. “You can't”, was the reply.
“What? What do you mean?” you asked.
“Well, you can delete the file from the repository and then re-add it under a new name.”
“Yes, but then nobody would know it had been renamed.”
“Let's call the CVS administrator. She can hand-edit the repository's RCS files for us and possibly make things work.”
“What?”
“And by the way, don't try to delete a directory either.”
You rolled your eyes and groaned. How could such simple tasks be so difficult?
No doubt about it, CVS has evolved into the standard software configuration management (SCM) system of the Open Source community, and rightly so. CVS is free software and has a wonderful nonlocking development model that allows hundreds of far-flung programmers to collaborate. In fact, one might argue that, without CVS, it's doubtful whether sites like Freshmeat or SourceForge ever would have flourished as they do now. CVS and its semi-chaotic development model have become an essential part of Open Source culture.
So what's wrong with CVS? Because it uses the RCS storage system under the hood, CVS can only track file contents, not tree structures. As a result, the user has no way to copy, move or rename items without losing history. Tree rearrangements are always ugly server-side tweaks.
The RCS back end cannot store binary files efficiently, and branching and tagging operations can become very slow. CVS also uses the network inefficiently; many users are annoyed by long waits, because file differences are sent in only one direction (from server to client, but not from client to server), and binary files are always transmitted in their entirety.
From a developer's standpoint, the CVS codebase is the result of layers upon layers of historical “hacks”. (Remember that CVS began life as a collection of shell scripts to drive RCS.) This makes the code difficult to understand, maintain or extend. For example, CVS's networking ability was essentially stapled on. It was never designed to be a native client/server system.
Rectifying CVS's problems is a huge task, and we've only listed a few of the many common complaints here.
In 1995, Karl Fogel and Jim Blandy founded Cyclic Software, a company for commercially supporting and improving CVS. Cyclic made the first public release of a network-enabled CVS (contributed by Cygnus software). In 1999, Karl Fogel published a book about CVS and the open-source development model it enables (cvsbook.red-bean.com). Karl and Jim had long talked about writing a replacement for CVS; Jim even had drafted a new, theoretical repository design. Finally, in February 2000, Brian Behlendorf of Collabnet (www.collab.net) offered Karl a full-time job to write a CVS replacement. Karl gathered a team and work began in May.
The team settled on a few simple goals: it was decided that Subversion would be designed as a functional replacement for CVS. It would do everything that CVS does, preserving the same development model while fixing the flaws in CVS's (lack of) design. Existing CVS users would be the target audience; any CVS user should be able to start using Subversion with little effort. Any other bonus features were decided to be of secondary importance (at least before a 1.0 release).
At the time of this writing, the original team has been coding for a little over a year, and we have a number of excellent volunteer contributors. (Subversion, like CVS, is an open-source project.)
Here's a quick rundown of some of the reasons you should be excited about Subversion:
Real copies and renames: the Subversion repository doesn't use RCS files at all; instead, it implements a virtual versioned filesystem that tracks tree structures over time (described below). Files and directories are versioned. At last there are real client-side mv and cp commands that behave just as you think.
Atomic commits: a commit either goes into the repository completely or not all.
Advanced network layer: the Subversion network server is Apache, and client and server speak WebDAV(2) to each other. (See the “Subversion Design” section below.)
Faster network access: a binary diffing algorithm is used to store and transmit deltas in both directions, regardless of whether a file is of text or binary type.
Filesystem properties: each file or directory has an invisible hash table attached. You can invent and store any arbitrary key/value pairs you wish: owner, perms, icons, app-owner, MIME type, personal notes, etc. This is a general-purpose feature for users. Properties are versioned, just like file contents. And some properties are auto-detected, like the MIME type of a file (no more remembering to use the -kb switch).
Extensible and hackable: Subversion has no historical baggage; it was designed and implemented as a collection of shared C libraries with well defined APIs. This makes Subversion extremely maintainable and usable by other applications and languages.
Easy migration: the Subversion command-line client is very similar to CVS; the development model is the same, so CVS users should have little trouble making the switch. Development of a cvs2svn repository converter is in progress.
It's free: Subversion is released under an Apache/BSD-style, open-source license.
Subversion has a modular design; it's implemented as a collection of C libraries. Each layer has a well defined purpose and interface. In general, code flow begins at the top of the diagram and flows downward—each layer provides an interface to the layer above it (see Figure 1). Let's take a short tour of these layers, starting at the bottom.
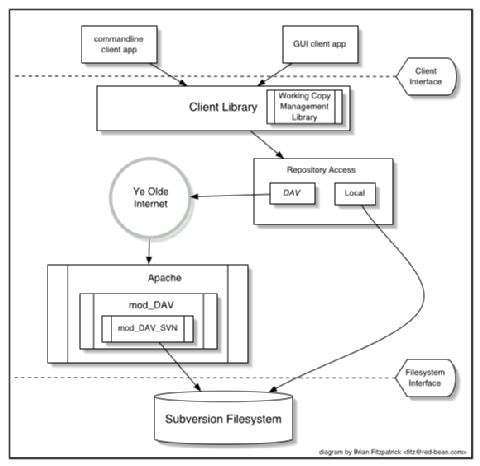
Figure 1. Design Layers of Subversion
The Subversion Filesystem is not a kernel-level filesystem that one would install in an operating system (like the Linux ext2 fs). Instead, it refers to the design of Subversion's repository. The repository is built on top of a database, currently Berkeley DB, and thus is a collection of .db files. However, a library accesses these files and exports a C API that simulates a filesystem, specifically a versioned filesystem.
This means that writing a program to access the repository is like writing against other filesystem APIs: you can open files and directories for reading and writing as usual. The main difference is that this particular filesystem never loses data when written to; old versions of files and directories always are saved as historical artifacts.
Whereas CVS's back end (RCS) stores revision numbers on a per-file basis, Subversion numbers entire trees. Each atomic commit to the repository creates a completely new filesystem tree and is individually labeled with a single, global revision number. Files and directories that have changed are rewritten (and older versions are backed up and stored as differences against the latest version), while unchanged entries are pointed to via a shared-storage mechanism. This is how the repository is able to version tree structures, not just file contents.
Finally, it should be mentioned that using a database like Berkeley DB immediately provides other nice features that Subversion needs: data integrity, atomic writes, recoverability and hot backups. See www.sleepycat.com for more information.
Subversion has the mark of Apache all over it. At its very core, the client uses the Apache Portable Runtime (APR) library. In fact, this means that a Subversion client should compile and run anywhere Apache httpd does. Right now, this list includes all flavors of UNIX, Win32, BeOS, OS/2, Mac OS X and possibly NetWare.
However, Subversion depends on more than just APR; the Subversion server is Apache httpd itself. Why was Apache chosen? Ultimately, the decision was about not re-inventing the wheel. Apache is a time-tested, open-source server process ready for serious use, yet is still extensible. It can sustain a high-network load. It runs on many platforms and can operate through firewalls. It's able to use a number of different authentication protocols. It can do network pipelining and caching. By using Apache as a server, Subversion gets all these features for free. Why start from scratch?
Subversion uses WebDAV as its network protocol. DAV (distributed authoring and versioning) is a whole discussion in itself (www.webdav.org), but in short, it's an extension to HTTP that allows reads/writes and versioning of files over the Web. The Subversion Project is hoping to ride a slowly rising tide of support for this protocol; all of the latest file browsers for Win32, Mac OS and GNOME speak this protocol already. Interoperability will (hopefully) become more and more of a bonus over time.
For users who simply wish to access Subversion repositories on local disk, the client can do this too; no network is required. The Repository Access (RA) layer is an abstract API implemented by both the DAV and local-access RA libraries. This is a specific benefit of writing a “librarized” revision control system; it's a big win over CVS, which has two very different, difficult-to-maintain code paths for local vs. network repository-access. Feel like writing a new network protocol for Subversion? Just write a new library that implements the RA API.
On the client side, the Subversion working copy library maintains administrative information within special /SVN subdirectories, similar in purpose to the /CVS administrative directories found in CVS working copies.
A glance inside the typical /SVN directory turns up a bit more than usual, however. The entries file contains XML that describes the current state of the working copy directory (and that basically serves the purposes of CVS's Entries, Root and Repository files combined). But, other items present (and not found in /CVS) include storage locations for the versioned properties (the metadata mentioned in the “Subversion Features” section above) and private caches of pristine versions of each file. This latter feature provides the ability to report local modifications and do reversions without network access. Authentication data also is stored within /SVN, rather than in a single .cvspass-like file.
The Subversion client library has the broadest responsibility. Its job is to mingle the functionality of the working-copy library with that of the repository-access library, and then to provide a highest-level API to any application that wishes to perform general revision control actions.
For example, the C routine svn_client_checkout() takes a URL as an argument. It passes this URL to the repository-access library and opens an authenticated session with a particular repository. It then asks the repository for a certain tree and sends this tree into the working-copy library, which then writes a full working copy to disk (/SVN directories and all).
The client library is designed to be used by any application. While the Subversion source code includes a standard command-line client, it should be easy to write any number of GUI clients on top of the client library. Hopefully, these GUIs should someday prove to be much better than the current crop of CVS GUI applications, which are no more than fragile wrappers around the CVS command-line client.
In addition, proper SWIG bindings (www.swig.org) should make the Subversion API available for any number of languages: Java, Perl, Python, Guile and so on. In order to Subvert CVS, it helps to be ubiquitous.
The release of Subversion 1.0 currently is planned for the beginning of 2002. After the release of 1.0, Subversion is slated for additions such as i18n support, intelligent merging, better changeset manipulation, client-side plugins and improved features for server administration. Also on the wish list is an eclectic collection of ideas such as distributed, replicating repositories.
A final thought from Subversion's FAQ: “We aren't (yet) attempting to break new ground in SCM systems, nor are we attempting to imitate all the best features of every SCM system out there. We're trying to replace CVS.”
If in three years Subversion is widely presumed to be the standard SCM system in the Open Source community, then the project will have succeeded. But the future is still hazy. Ultimately, Subversion will have to win this position on its own technical merits. Patches are welcome.
email: sussman@red-bean.com
Ben Collins-Sussman has worked for 11 years as a programmer and system administrator at various government, academic and commercial institutions. Ben currently works for Collabnet, Subversion's main sponsor, and also moonlights as a composer in the Chicago theater community. His home page is at www.red-bean.com/sussman.
