
Selecting I/O Units
In this article, I introduce the I/O unit, the hardware that allows Linux to interact with the physical world. I/O units have different characteristics that make them appropriate for virtually any monitoring or automation task, and initially, it may seem difficult to choose the right one. I introduce terms for those just starting out in this field and describe features that will help you select the right device for the application. Finally, I outline steps to follow for implementing the I/O system, whether small or large.
I/O is a commonly used term referring to data input and output devices. Disk drives, video displays, keyboards and mice are typical computer devices associated with I/O. In the automation industry, the term I/O refers to a device that permits a computer to monitor and control physical elements in the physical world. To allow Linux-based or other systems to reach into the physical world, I/O units are coupled with sensors and actuators. Sensors are electronic devices attached to inputs; they convert quantities in the physical space into quantities computers understand. Actuators, attached to outputs, are devices that translate computer commands into responses in the physical world.
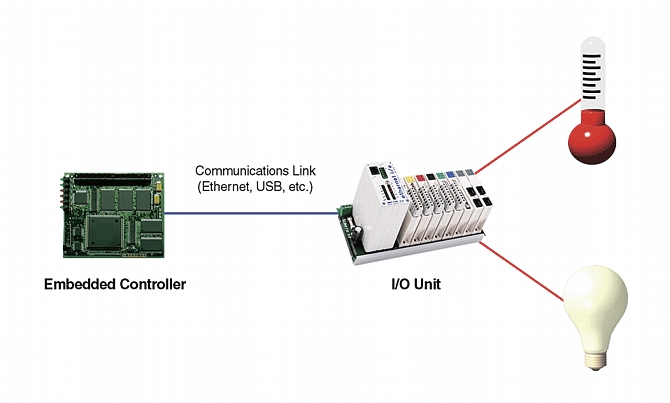
Figure 1. Automation System Portrait
As with any technical field, there is a vast ocean of terminology used with I/O units. I present some of that terminology now and refer back to it when I later discuss the design features that drive selection decisions. Look out! Here comes the tide.
When I mention the word signals, I'm referring to an I/O unit's capability to receive and send analog and digital electrical signals, not the signal programming sort of concept. Understanding the nature of signals and the differences in signal types permits proper selection and design for I/O units. These signals fall into two primary categories, analog and digital, with a smaller category for a rapidly developing group of ``smart sensors'' that report encoded digital data.
Digital or discrete signals are used by a two-state device, which is a device that has only two possible states: on or off. For example, switch sensors may provide a signal that tells us a tank level is full or the power is on. Another example of digital sensors are the so-called idiot lights on the dashboard of an automobile.
These signals are driven by an excitation source, either a power supply or a battery. Discrete loop is another name for the discrete circuit. While discrete loops are typically powered with 12 to 48 volts direct current (VDC), many applications use a convenient excitation source. In the United States, this may be 120 volts alternating current (VAC) or another voltage comparable to the regional supply ratings. In other words, don't grab any wiring until the power to the control box is turned off!
Other sensors and effectors are analog or proportional in nature, meaning that they have not just two states but a range of possible values. Examples of analog values are temperature gauges, analog clocks, speed, sound volume and pressure. These proportional quantities are converted to analog signals. The value of the signal, whether current or voltage, reflects the reading at the sensor. While the signal may be proportional to a physical value, it may not be linear--that is, if the signal doubled in value, the physical value would not necessarily double as well. There are many types of nonlinear analog sensors; thermocouples, devices that measure temperature via a voltage produced by dissimilar metals, are a popular example.
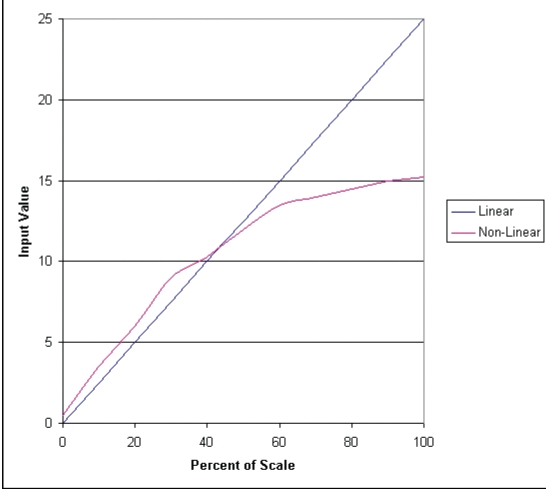
Figure 2. Linear and Nonlinear Graph
Other sensor technologies require substantial processing and generally have their own computers. While these units may send data in a proportional analog format, they also have the ability to send the sensor reading as digital data, using a digital interface in which the data is encoded and transmitted. RS-232, RS-422 and RS-485 are common interfaces used. Examples of digital data sensors include intelligent accelerometer monitors, laser extensometers, flow meters and stepper or synchronous motor controllers. With USB and ``biscuit'' Ethernet devices, these sensors can be directly connected to Ethernet networks and other high-bandwidth communication media.
With analog sensors, the signal the sensor sends may not be adequate for the I/O unit's circuitry. Conversely, a signal that emanates from an I/O unit output may not be robust enough for the effector. In these cases, an analog circuit that receives a weak or limited signal and conditions it to the appropriate range or robustness may be needed. This modification or improvement of the original signal is called signal conditioning.
If this sounds complex, it is. Fortunately, most I/O units incorporate signal conditioning internally to cover most of the common sensor requirements. For those sensors that have very difficult signal conditioning requirements, such as strain gages and accelerometers, or sensors with additional requirements such as excitation (a power source), separate signal-conditioning units are available to convert these signals. Occasionally, a custom signal-conditioning circuit may be necessary, and high-accuracy, integrated analog circuits make it possible to create one. While the detailed function of the circuit is complex, the integrated analog circuit tremendously simplifies the design. With an analog-integrated chip, a few other components and a power supply, a simple signal-conditioning circuit can be built inexpensively.
I was unable to find a tag for this.
Computers understand only numbers. They don't understand continuous analog electrical signals. So at the I/O unit, the conditioned analog input signals are digitized into a number so the computer will understand them. If the signal is an output, the I/O unit converts a number from the computer into a voltage or a current. The number that is received from an analog-to-digital conversion or sent to a digital-to-analog converter is called counts. Counts represent the proportional value of the analog signal in a digital form. Counts typically range from zero to 2n - 1 (although there are modified implementations of this), where n is the number of bits of the digital-analog converter.
Many I/O units also support engineering units (physical quantities) in floating-point formats. For example, most of us don't think of room temperature as 100 counts but as 78ºF (25ºC). The I/O unit will graciously perform the engineering unit-to-counts conversion. Temperature conversion can be very complex due to the nonlinear nature of the sensor. Other conversions may not be difficult, just tedious to calculate (I avoid tedious calculations and let the I/O unit do them).
In this age of digital multimedia, we are fairly familiar with the term bits when referring to the resolution of analog-to-digital conversion. Typically analog-to-digital converters in instrumentation systems range from 12 to 18 bits of representation (4,096 to 262,144 counts). The bits dictate how many counts or discrete levels the analog signal may be described in. The number of discrete levels implies resolution of the digitized analog signal.
Changing some number schemes, I'll refer to percents of scale instead of counts. If I think of 0% of counts as zero counts and 100% of counts as the maximum count my analog-digital converter represents, I can start talking about signal magnitudes again but in the quantified discrete digital world.
Precision is affected by resolution. I think of precision as the magnitude of accuracy per count. It turns out that mathematically, it's the inverse of the counts times 100%. In the case of a 12-bit converter, each count represents 0.024% of full scale. For the 18-bit converter, each count is 0.00038% of full scale. I think of precision as describing how small the steps are that the count value represents, which means that the higher the number of bits of resolution, the closer the count is to the physical analog value (assuming that there are no errors in this conversion).
The number of steps, or the size of the steps the converter represents, is meaningless unless we know the accuracy of the converter. Accuracy is how much error the converter may report, typically calculated as the inverse of the resolution multiplied by 100%. Sometimes this is reported as counts or as percents of full scale. Linearity, which is the error due to limitations of the data converter, also may be specified for the converter. Linearity varies over the range of input. For example, it may be 0.1% at 10% of input and 0.2% at 50% of input and 0.02% at 100% of input. Clearly, the error doesn't scale with the input. Specifications may show linearity as a tolerance specification, a graph or an algebraic constant of a mathematical equation.
With high resolution and very linear analog-integrated circuits, accuracy and linearity are very high. It's been quite some time since I've had to consider how error-prone my converter is. These days, measurement errors generally occur when the accuracy of the analog/digital circuitry exceeds the accuracy of the sensor or effector.
We've reached the end of the wire on the analog side. The last item on the wire is the sensor, or effector, which is subject to errors as well. It's important to mention these errors because they affect the value the I/O unit reports or sends. It's a ``garbage in, garbage out'' affair. I'll quickly review the possible measurement errors.
Sensors and effectors are affected by the same accuracy and linearity issues as analog-digital converters. Measurement accuracy is typically a calibration issue. Calibration is a procedure to verify that the measurement corresponds to the reported value. Drift is long-term deviation that causes errors in the measurement value. Drift may be caused by degradation of a sensor's components or life-cycle fatigue of a system. Sensor and effector performance also may be subject to environmental factors such as temperature or humidity. It's important to read the specifications for a sensor or effector and thoroughly understand them.
I also look at measurement error as the limit I need to convert or display my data. Displaying the number precisely and accurately is important. If I have a sensor reporting a value such as mathematical pi (3.14159...and onward irrationally) and the sensor's precision is only two decimal places, I should display only 3.14. Representing the rest of the number beyond two decimal places is a guesstimate or an unqualified representation.
It is also important to determine the expected accuracy. I specify my I/O hardware to be slightly more accurate than my sensors and effectors (up to the limit of the customer specification). This way the sensor and effector errors are the measurement limit and not from my signal conditioning or conversion hardware. However, these concerns are less founded with the availability of high-resolution/accuracy I/O unit hardware.
For some reason, most control system specifications list an item requiring the volume of conversions over time (samples per second) or how new the data is when reported. Because of the conversion process and buffering of the converted data, there may be a delay between the actual analog signal value and the reported value, or the analog-digital converter may have a maximum conversion rate.
Fortunately, this is an area that technology has improved dramatically. I recall delay specifications that used to describe throughput in milliseconds but now describe it in sub-microseconds. A large percentage of monitoring systems do not require very fast conversion rates. As we'll see later, however, the communication infrastructure between my I/O unit and the host computer may cause a significant delay.
A number of features affects the suitability of an I/O unit for a given application: isolation, remote vs. local placement, modularity, connectivity, and protocol and software support. I'll discuss each of these features before talking about steps to implement a system.
Because the I/O unit is the interface between the computer and the physical world, it has a two-sided nature. For the I/O unit, physical world data appears as electrical signals, either voltage or current. On the other side, the I/O unit exchanges digital data with the computer. The I/O unit's connection with the sensors and effectors is referred to as the field connection. The side of the I/O unit that connects with the computer is referred to as the computer or control side. At the interface of these two sides are electronics and isolation.

Figure 3. Isolation: No Electrons Crossing the Yellow Line!
Connected to the field side of the I/O unit are the sensors and effectors that send an electrical signal to, or receive a signal from, the I/O unit. This signal has a value in current or voltage that correlates with the phenomenon it is measuring or driving. The I/O unit's computer or control side is connected to some kind of data bus or communication technology.
What happens if a high-voltage wire shorts out with another on my I/O unit? If the wire shares a common metal connection with my control computer, simply put, the computer is history. Damaging electrical phenomena may be caused by faulty wiring, water leaks, failing devices, lightning, static discharge and ground potential. But good system design can contain possible damage from electrical phenomena, even a direct lightning strike.
Many I/O units eliminate a metal connection between the field and control sides of the I/O unit. Weird science at work? No, not really. By using optical, capacitive and magnetic technologies, an electrical circuit can be isolated yet connected. A magnetic circuit can supply power from the control side to the field side without a metal connection. An optical link can provide a data interface between the control side and the field side. Capacitive isolation uses electron charge coupling to transfer signals between two isolated plates. This elimination of the metal connection between the two sides of the unit is referred to as electrical isolation or simply isolation.
In the event of an extreme situation (a lightning strike) the field side will be destroyed. That's inevitable. The electrical barrier imposed by the isolation also may be compromised, although it takes thousands of volts to do so. Communication media may provide additional isolation, however. Copper Ethernet, for example, provides an additional layer of isolation because media transformers ensure that the patch cord is isolated from the host and the infrastructure. Optical Ethernet is even more isolated. Optical Ethernet segments can be made to contain and survive a direct lightning strike (with a little ground planning in appropriate places).
Isolation is critical to prevent general electrical phenomena from damaging the I/O unit and the computer controls. Isolation is critical to at least contain the damage an extreme event will cause. Electrical anomalies are unavoidable over the life of a system, but with planning, even the highest energy events are survivable.
I/O units typically are referred to as local or remote, a reference loosely interpreted to mean distance. I like to think of local as directly (or nearly directly) connected core processor peripherals. PCI- and ISA-enabled peripherals are good examples of local devices. A remote I/O unit usually has some kind of communication medium, such as a serial (RS-232 or RS-485) cable, wireless, infrared, Ethernet, FireWire or USB (to name a few). These remote interfaces have devices that may connect to the local core processor of the controlling computer but modify the data in such a way that it is transferred via another medium to its destination. This medium acts as an extension cord that extends the distance from the core processor bus to the device. This distance may be as short as a meter or as long as kilometers.
Remote vs. local I/O is important when considering the expense of additional cables to a control location. If I were to design a local control system using a set of PCI I/O cards, every point of I/O would have a cable installed. Consider a 1,000-point system with 1,000 cables. Just imagine the expense if an electrical contractor quoted an installation cost of $100 US per cable (the total would be $100,000 US)! In such a case, remote I/O allows a single wire such as CAT 5 (Ethernet) to be run to distributed I/O units. While 1,000 cables are still required for installation, the signal cable distance is shorter, decreasing the labor and materials cost of installation. In more unusual projects I've worked on, remote I/O implementation also provided incredible savings in cable weight. In one project, I recall estimating that we saved approximately 1,000kg of mass by just converting the system to remote I/O.
Shorter sensor and effector cables routed to a nearby I/O unit also are easier to test, debug and maintain. For example, if the cables run through a complex vehicle such as a ship or an airplane, a suspected wire failure might require physical cable tracing. If the wire length is 500 meters, each meter of wire may require inspection. If an I/O unit is located next to sensors and effectors, the communication media cable from the control computer to the I/O unit is still 500 meters, but it may be an Ethernet fiber bundle. The sensor and effector cables to the I/O unit may be only meters long. Clearly, debugging a couple of meters of wire is easier than several hundred meters.
Analog signals also may be affected by electrical noise, which places additional and undesirable signals into the analog data. Devices switching on and off may cause electrical noise. Power cables too close to sensitive signals also may create anomalies in I/O unit readings. Typically, the shorter the wire, the lower the probability of receiving electrical noise. Digital media cables such as copper Ethernet are susceptible to electrical noise too. Digital media typically employs a method of data validation that detects when data corruption occurs, but it still can be a problem.

Figure 4. Assembled I/O Unit Modularity
Nonmetal technologies such as fiber are not susceptible to noise because they use light and not electrons. When installing a system it is useful to perform a site survey to evaluate potential sources of electrical noise. Plan for cables to be a significant distance from high-energy cables (power conductors, RF transmitters and so on) and high-energy systems (such as anodizing systems, high-voltage switching equipment and high-energy control hardware).
Modularity is all about selecting channels or points of I/O. While most I/O units support either all digital points or all analog points, some support both types. Mixed systems, as we call them, allow the designer to pick a single unit and select all the points required. As most systems require both analog and digital points, mixed I/O units optimize the cost-effectiveness of the design and reduce size and weight.

Figure 5. Disassembled I/O Unit Modularity
In addition, modularity improves life-cycle maintenance. An I/O unit with removable points may require a few seconds to replace a component and restore system operation. Replacing an entire I/O unit is much more costly in labor and downtime. Modularity also allows smaller, cheaper components to be stocked as spares should a replacement be necessary, also reducing downtime.
The next topic is connectivity, or the physical medium the I/O unit uses to communicate with the host. Connectivity applies to remote I/O, as local I/O is in the form of an adaptor card. Connectivity determines the auxiliary costs in the installation of any system. Connectivity methods also determine the reliability, expanse, throughput and upgradability of the system.
One of the very first questions I ask in any application is, ``What's the distance between the I/O unit and the control computer?'' The answer to the question may be a meter, or thousands of meters, or considerably more. Ethernet provides excellent expanse up to kilometers. RS-485/RS-422 may extend to one kilometer. FireWire is short distance and so is USB. The media must simply go the distance.
The next question I ask is, ``How fast or how large is the volume of data to and from the I/O units?'' This question usually narrows the selection range of communication options to one or two choices. High-volume, large-data transactions usually fall into Ethernet. Low-transaction data sizes and slow data requirements fall into the serial RS-485/RS-422 options. If the distance requirement is very short, the PCI bus for adaptor cards may be suitable. FireWire and USB options are just emerging as connection options in the automation arena.
I'll admit, there's also the all-encompassing limit of cost: selection of the connectivity media is always limited by the budget. Ethernet in many cases is an installed infrastructure, and taking advantage of the installed network can reduce costs. A new Ethernet installation appears costly due to the addition of infrastructure.
Installing a twisted-pair wire for RS-485 is initially inexpensive because infrastructure is not required, but there's a trade-off in additional flexibility. Adding another device may overload the communication bandwidth and require installation of another twisted-pair wire, adding additional costs.
Installing a gigabit Ethernet fiber backbone is costlier initially, but other devices may share the Ethernet segment. Such a high-bandwidth connection is capable of carrying significant other traffic (such as an office network) simultaneously, providing long-term flexibility. Specific infrastructure selection also may provide communication redundancy, an additional feature most automation systems require. Ethernet hardware is standard, with parts readily available through any office network provider.
Many simple-wire technologies are cheaper than Ethernet but are limited in flexibility. While initial costs are a driving factor in the installation life cycle, modifications prove more expensive and perhaps impossible. At times it's worth investing the extra resources to know that flexibility and expansion are possible. It takes a broad perspective and insight to see this, but as specific networking technologies permeate into every aspect of the industry, it pays to surf the wave (so to speak). Higher initial costs may be absorbed into a long-term system plan.
One little point needs to be mentioned. When I talk about expanse, it's not the distance from point A to point B (the shortest path). Instead, I'm referring to the physical path: the installed cable distance. I've designed implementations where the physical path was over 20 times the shortest-length path! Make sure you know the real distance.
Every I/O unit has a data protocol, which organizes data in the messages that request or send values or commands to and from the I/O unit. Data protocols could be a string of binary data, ASCII-readable messages or a combination of both. Message protocols can be tedious, since byte manipulation or creating ASCII sequences in the protocol may take time. Learning the protocol functionality and understanding its limitations may itself prove time consuming.
PCI and ISA cards have a data protocol plus a device driver. The device driver provides a pipe between the application and the hardware. Device drivers may be difficult for those unfamiliar with register-level hardware. Device drivers also may increase project risk or costs due to additional labor. The best solution is to select a device that already has a device driver. Be careful of using locally connected hardware too, since ``bus wars'', the frequent change of the expansion bus available on your computer, may make your hardware suddenly obsolete. Remote hardware typically has greater longevity in the communications infrastructure and therefore promotes long-term support and computer architecture flexibility.
Linux supports the most diverse hardware architectures. This diversity can cause compatibility issues. However, I express concerns about data protocol support only if I'm using an older-generation mainframe or a system that deviates from a modern desktop architecture. In these cases I always make certain that the method of communicating with the hardware is very well documented and assisted with source code (even before selecting the hardware). I like understanding the methodology and features of the data protocol, but I also am concerned about long-term support of my systems. Source code assists support. I would be very disappointed to find out that I had to write additional software in a tightly budgeted project. Such setbacks are expensive and jeopardize a project. Make certain that the code supports the target Linux architecture and kernel version.
Now that I've introduced the terminology and discussed features important to selecting an I/O system, let's briefly summarize how to put it all together. The following outline describes how I approach the selection and implementation of I/O systems. I've found that these steps may occur in parallel and may be iterative in nature, with decisions being refined and becoming more accurate with each pass. Designing the system requires a significant amount of patience and persistence as well as a flair for precise detail.
Inventory the sensors and effectors the system specification requires. Include location, function and details of the devices. Spreadsheets are excellent tools for this documentation.
Determine accuracy and resolution requirements. Determine data rate and response-time requirements.
Estimate the expanse of the system. Chart the potential communication paths; require blueprints if necessary.
Evaluate I/O unit options to fulfill the points, expanse and throughput requirements.
Consider modularity not only as a flexible means of communication but also as a means of simplifying maintenance over the system's lifetime.
Select the communication infrastructure. Refine the system expanse and the communication paths.
Evaluate software support for each I/O unit considered for the system.
Start wiring!

Bryce Nakatani (linux@opto22.com) is an engineer at Opto 22, a manufacturer of automation components in Temecula, California. He specializes in real-time controls, software design, analog and digital design, network architecture and instrumentation.
email: bnakatani@opto22.com

