
Programming Silence OUT!
Is that not wonderful, François? Ever since I was a young boy, even before I thought of opening this restaurant, I have wanted something like this. I remember watching 2001: A Space Odyssey, listening to the voice of HAL 9000 and thinking, “That is what I need. A talking computer.” Years later, I suddenly realized that I still did not have my talking computer. Well, today, mon ami, we are going to change all that.
What? Our guests have arrived? Welcome, mes amis, to Chez Marcel. I am so happy you could come today. We have some wonderful items on our menu for the programmer who has programmed everything. Please, sit and François will bring you some wine. François, go to the cellar and fetch the 1996 Hill of Grace from Australia.
Get comfortable, mes amis. You are going to love this wine. Ah, merci, François. Please, pour for our guests.
I was telling François that we should have talking computers everywhere by now, but my Linux workstation spends its time in silence. For reasons that I cannot fathom, none of the software on my system seemed to be speech-enabled. So, for all of today's recipes, you will need a sound card in your system, properly configured, as well as a microphone.
The Center for Speech Technology Research (CSTR) at the University of Edinburgh in Scotland had just what I needed to start down the road to my own talking computer. By surfing over to this address, http://www.cstr.ed.ac.uk/projects/festival/, you'll find a fascinating project called Festival.
Festival is a multilingual speech synthesis system. It is capable of text-to-speech work with multiple voices. With its API design, it can be incorporated into numerous other programs and applications. You'll see what I mean as we explore this package.
Getting Festival is easy. Visit the site, click the download button and pick up the latest version of the package. While you are there, pick up the speech_tools package, as Festival relies on its presence. Consequently, it is the first thing we will build:
tar -xzvf speech_tools-1.2.1.tar.gz cd speech_tools cp config/config-dist config/config chmod +w config/config
At this point, you may want to consider whether you wish to use shared libraries since the default is not to do so. In that case, you must uncomment the following line in the config/config file by removing the hash mark before the word “SHARED”: #SHARED=1.
This is actually the recommended option now. Whether or not you choose to do so, we can now continue with the build:
make info make make install
This is an excellent time to relax, try the foie gras (it is really quite excellent, non?) and have another sip of your wine. When the speech_tools are built, it is time to create the Festival system. Unpack the source for Festival into a directory of your choosing with the command tar -xzvf festival-1.4.1.tar.gz.
All these files will expand into a directory called /festival. Before you do anything else, unpack the language lexicon and speech database. I started by grabbing the following files:
festlex_CMU.tar.gz festlex_POSLEX.tar.gz festvox_kallpc16k.tar.gz
The CMU file is a dictionary file for all English voices, while the POSLEX file contains speech parts also common for all English speakers. Finally, we have a speech database for an American-style voice, with 16k sampling. Different readers will no doubt want different voices, whether it be male, female, British or (bien sûr) French. Details on what you might need are available by looking at the README in the web site's distribution directory.
When you extract these files, they will also expand into the same /festival directory. From here, the process is identical to what we did for the speech_tools, right down to copying the config file from config-dist, except, of course, that we copy it to the /festival directory.
When this is all done, type bin/festival from the installation directory. You should see something like this:
bin/festival Festival Speech Synthesis System 1.4.1: release November 1999 Copyright (C) University of Edinburgh, 1996-1999. All rights reserved. For details type `(festival_warranty)' festival>
Are you ready to hear your computer speak? Well then, at the festival> prompt, type the following (the parenthesis and quotes are important): (SayText "Franiçois. Vite. More wine.").
If everything went well, you should have heard the words “François. Vite. More wine” come from the speakers. It is a commanding voice, non? I like to play that line because it unnerves my faithful waiter. Of course, since I am using an English voice and database, the pronunciation is what you might call interesting. Typing control-d here will let you exit the Festival command mode. You can also type (quit). Once again, the brackets are important here. Let's try something more interesting. By using the --tts flag, we can specify the pathname to a text file and have Festival read it for us. For instance, I have a cron job that changes the message-of-the-day every night by running the fortune program. So, to read the message-of-the-day, I could do this:
bin/festival --tts /etc/motd
If you leave off a filename, you can just start typing. When you are done, you then press control-d to terminate the input, and Festival will exit. Here's one other thing to try. Simply pipe the output of a command to the Festival program. Want to hear a rather interesting interpretation of the date? Try this, date | bin/festival --tts.
You might also run the Fortune program for some synthesized wisdom: /usr/games/fortune | bin/festival --tts.
Festival can also run as a server for other programs to pass text information by running the program with the --server flag. As an example, you might write an application that writes to the Festival socket (by default, this runs on port 1314). Listing 1 is a little Perl script I wrote just for this occasion. It is not exciting, but you might consider it a starting point for your own applications. Keep in mind that you may have to change the path to your Perl executable in the first line.
Listing 1. Writing to the Festival Socket
A wonderful example of this idea is a program written by Darxus called speechd. This package implements a device file called /dev/speech to which you can write any text you like. Redirect the output to this device, and the Festival system (when running in server mode) will pick it up and say it. This is also a Perl script and can be downloaded from the Speech IO site, http://www.SpeechIO.org/.
Start by unpacking the distribution into a temporary directory. Then, run the simple build that follows:
tar -xzvf speechd-0.54.tar.gz cd speechd make make install
To run the program as a dæmon, simply type the path to the command: /usr/local/bin/speechd.
Before I continue, I should tell you that I had some problems here. My Red Hat system's /etc/hosts file had a localhost entry that read:
127.0.0.1 localhost.localdomain localhost
Yours may as well.
To make things work properly, I had to change it so that the two localhost definitions were switched like this:
127.0.0.1 localhost localhost.localdomain
If, by chance, the Festival server is not running, the speechd will try to start it. Unfortunately, if you built Festival from source, you may have to modify the speechd script to use the full path to the executable. Another option is to copy the Festival binaries to /usr/local/bin.
So, what can you do with this? Well, using my original fortune program example, I could simply redirect the output to /dev/speech with the command /usr/games/fortune > /dev/speech.
Implementing this into your scripts is extremely easy. Here is another example. I could have a script that runs every few minutes to check for new mail, count the number of messages and tell me about it through the speech device. (Note that the single quotes are actually back-ticks.)
echo "You have `frm | wc -l` messages in your mailbox" /dev/speech
Now that we have our Linux systems talking to us, it seems to me only one thing is missing. We need to have our systems listen to us and do as they are told, non? We need voice recognition software. For that little bit of personalization, I went to Daniel Kiecza's home page and picked up the source for the latest cvoicecontrol, a nice little package distributed under the GPL.
With cvoicecontrol, we can start creating the fully automated system of our dreams. Of course, this now means we should be careful what we say, non?
tar -xzvf cvoicecontrol-0.9alpha.tar.gz cd cvoicecontrol-0.9alpha ./configure make make install
The resultant files will appear in your /usr/local/bin directory. There are three that you need to know about. One is the cvoicecontrol program itself. Before you can start using it, you need to calibrate your microphone and create model files. This is done with the microphone_config and model_editor programs.
Start with the microphone_config program and follow it through the question and answer session. It is all nicely menu-driven. Your default mixer and audio devices should be automatically detected, so that part should already be filled in. Mine showed up as /dev/mixer and /dev/dsp. The next step is to adjust mixer levels, set up recording thresholds and create a configuration file. Probably the toughest part of this whole step is having to talk loud enough for the time it takes the program to get its levels. I tell you right now, mes amis, it is more difficult than it sounds. The default location is $HOME/.cvoicecontrol/config.
Then comes the fun part. Start the model_editor. You will be presented with a menu where you can load, edit, save or create a new speaker model. Have a look at Figure 1 to see the program in action.
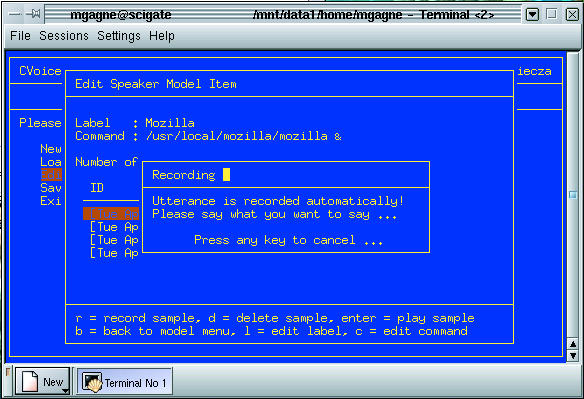
Figure 1. Adding a Command through the model_editor
The model is you, mes amis. Since there is nothing here yet, hit New Speaker Model, then choose Edit. Another menu will appear where you can record words and specify the events those sounds will generate. Everything here is a single keystroke. Press “a” to add a new item. The item will show up in the list as a generic item with no command specified. Now, press Enter to edit the item, and change the label to something that makes sense. For instance, I created one called “Start Mozilla”, and I entered /usr/local/mozilla/mozilla & for the Mozilla start command.
Notice that I put an ampersand at the end of the command to put it into the background. I did that because I want to be able to launch other voice commands after this one has started. Once you have done this, you need to enter some samples of your voice. You will need at least four samples. Speak your command clearly, wait and add another sample. When you have the four, you can back out (by pressing “b”) and save your speaker model. You may call it whatever you like, just remember where you put it.
So, now we have our microphone configured and at least one command associated with an equivalent voice command. By the way, to start Mozilla, you could just as easily say “browser” as your voice command, but it usually makes sense to use the command name, non? The only thing left to do is start cvoicecontrol: cvoicecontrol speakermodel.cvc.
Since I saved my speaker model as chefmarcel.svc (the extension is not necessary), I started the voice recognition software by typing cvoicecontrol chefmarcel.svc.
Now, if I say the word “Mozilla”, the browser starts up. I also created commands for my favorite editor, vi, and, of course, a couple of games.
Open the restaurant doors please, Tux. With tools such as the ones on today's menu, you can be well on your way to owning the computer of the future, today. You already run Linux, so you are almost there.
Well, mes amis, the clock, she is telling me time is running out and we must soon close. No sense in closing too soon, though. François, won't you please pour our guests another glass of wine? Merci, mon ami. You know, François, your built-in voice recognition software is working very well. Of course, François, I know you are a man and not a machine. Do not look so hurt. It is only a little joke, non?
Mes amis, I must thank you again for coming. Until next time, please join us here at Chez Marcel. Your table will be waiting.
A votre santé! Bon appétit!

