
Snort: Planning IDS for Your Enterprise
Snort is often referred to as a lightweight intrusion detection system. Snort is labeled lightweight because it is designed primarily for small network segments. Snort is very flexible due to its rule-based architecture. The designers of Snort have made it very easy to insert and expand upon rules as new security threats are detected. This article will detail the Snort installation, architecture, rules and how to run it.
Snort was written by Martin Roesch and can be downloaded from www.Snort.org by selecting the Downloads link on the left panel. As of this writing, the latest version of Snort is 1.7. The Snort web site will provide you with the ability to download binaries for some of the common platforms as well as source code. But before you download and try to install/compile Snort, you will need libpcap version 0.5 or higher. The latest version of libpcap is 0.6.2. It allows for system-independent packet capture and analysis. Libpcap is available on some BSD platforms. You may download the latest version of libpcap from www.tcpdump.org.
Installation of Snort is fairly straightforward. As with installing any typical UNIX tools, it involves running ./configure followed by make. I always like to view the configure options. Typing ./configure -help will display the available options. Typing make install will install all of the Snort files. However, you are still not ready to run Snort. Prior to running Snort you will have to build its rules file. But before we go on to write the rules file, let's review the Snort architecture.
The Snort architecture consists of three principal components. A simplified representation of these components is shown in Figure 1. They are described below:
Packet Decoder: the Snort packet decoder supports the Ethernet, SLIP and PPP mediums. The packet decoder performs all the work to prepare the data in an expedient manner for the detection engine.
Detection Engine: the detection engine is at the heart of Snort. It essentially is responsible for analyzing every packet based on the Snort rules that are loaded at runtime. The detection engine separates the Snort rules into what is referred to as a chain header and chain options. The common attributes such as source/destination IP address and ports identify the chain header. The chain options are defined by details such as the TCP flags, ICMP code types, specific type of content, payload size, etc. The detection engine recursively analyzes each and every packet based on the rules defined in the Snort rules file. The first rule that matches the decoded packet triggers the action specified in the rule definition. A packet that does not match any Snort rule set is simply discarded. Key components of the detection engine are the plugin modules such as the portscan module. Plugin modules enhance the functionality of Snort by adding to the analysis capability.
Logger/Alerter: logging and alerting are two separate subcomponents. Logging allows you to log the information collected by the packet decoder in human readable or tcpdump format. You can configure alerts to be sent to syslog, flat file, UNIX sockets or a database. Optionally, you may turn off alerting completely during testing or penetration studies. By default, all logs are written in the /var/log/Snort folder, and all of the alerts are written to the /var/log/Snort/alerts file.

Snort Rules
The Snort rules file is an ASCII file that can be created using your favorite editor. The contents of the rules file consist of the following sections:
Variable Definitions: these define variables that may be reused in creating Snort rules.
Snort Rules: these are the actual rules that enables intrusion detection. These should be consistent with the overall Intrusion Detection policy. Snort rules are defined later in this section.
Preprocessor: these are synonymous with plugins and are instrumental in extending the capability of Snort. For example, the portscan module allows Snort to detect port scans.
Include Files: these allow you to include other Snort rules files.
Output Modules: these allow the Snort administer to specify the output for logging and alerting. The output modules are run when the alert or logging subsystems of Snort are called.
Snort rules consist of two logical parts: the rule header and options. Snort rules must be specified on a single line. Additionally, Snort rules must contain IP addresses, as a hostname lookup is not performed. Figure 2 shows the Snort rule header and options details.
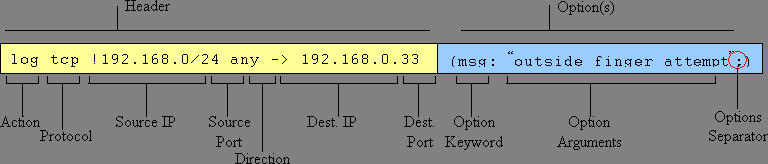
Figure 2. Rule Header and Options Details
Readers interested in the details of Snort rules are referred to the “Writing Snort Rules” link on the Snort page. In addition, the Snort distribution provides a RULES.SAMPLE file that is very well documented. This file displays the Snort rules that you can play with to build the Snort rules file for your environment. Before writing Snort rules it is recommended that you document your NIDS policy. This involves identifying the activity that you wish to log, ignore or be alerted of upon detection. A very simple policy is documented below and its corresponding rules file is displayed in Listing 1.
Listing 1. The Snort Rules File for Our Policy
Log on the following activity from any host not belonging to our network: Telnet attempts, FTP traffic, and finger attempts. Alert on the following: portscan attempts activity from any host not belonging to our network to th e /var/log/snort/pscan_alerts file, all PHF requests only and all DNS version queries. Pass (Ignore) on the following: all UDP port access above port 1024, all web browsing traffic originating from our network and all ssh traffic to the NIDS.
Snort can be run as a packet sniffer, packet logger and as an NIDS. When Snort is run as a packet sniffer, TCP/UDP/ICMP header information and application data is dumped on the standard output:
# Snort -vd
As a packet logger, Snort logs application and protocol header information to /var/log/today.log:
# Snort -dev -l /var/log/today.log
As an NIDS, Snort listens on the le0 interface and uses /etc/Snort.rules as its configuration file and runs Snort in dæmon mode:
# Snort -D -i le0 -c /etc/Snort.rules
Snort does not evaluate the rules in the order that they appear in the Snort rules file. All actions specified in the Snort rules file are evaluated in the order of Alert, Pass and Log by default. If you wish to change this order to Pass, Alert, Log, use the -o command-line flag. The -A option specifies the alert mode. There are four choices here: full, fast, none and unsock. The full, fast and none options are rather obvious. The unsock option provides Snort the ability to write to UNIX sockets where a program listening on that socket may process the alerts. Details of these options are available in the Snort man pages. With Snort alert modes, you will have the ability to specify the detail that you wish to view in your alert messages.
Be sure to validate your snort configuration. To validate, we must revisit the IDS policy. A few rules of thumb to validate your IDS are provided. Based on the IDS policy, you could launch specific tests and observe logs and alerts. For our policy listed above, we could launch Telnet, FTP and finger. You could use tools such as a scanner. Publicly available scanners, such as nmap, are good ones. Commercial scanners such as Cybercop from Network Associates and ISS scanner from Internet Security Systems can help you automate the process as well. Netcat, available from www.atstake.com/researchtools/, is another great utility. Finally, you could use several scripts written for script kiddies to launch attacks against your own infrastructure. However, tread cautiously, as running those scripts implies that you trust those scripts. Listing 2 shows a few sample alerts. It shows three common attacks: IIS Unicode attack, SYN/FIn Scan and a portscan.
First it was the sophisticated hacker, then came the script kiddy and distributed denial of service (DOS) attacks. Today's IT infrastructure and business assets are under constant threat of unauthorized access. Firewalls were the primary mechanism to shield against attacks on corporate assets during the early 1990s. Modern security architectures are increasingly including IDSes. Snort provides a very cost effective alternative to commercial IDSes.
Once compiled and installed, Snort can be run as a sniffer, packet logger and a network based IDS. Snort is easy to configure and provides multiple output modules for alerting and logging. Plugin modules developed by the Snort community further enhance Snort's ability. If you were able to get Snort up and running, watch your logs and alerts to gain insight into the type of traffic captured by Snort!
Nalneesh Gaur is a Technical Solutions Engineer with Digital Island in Dallas, Texas. He works with Fortune 500 companies to provide them with solutions in the area of content delivery and web hosting.
