
Linux-Based PLC for Industrial Control
The PuffinPLC Project is an effort to produce a Linux-based GNU Public Licensed Programmable Logic Controller (PLC). PLCs were developed in the 1960s to replace the complex electrical relay circuits widely used for machine control in industrial automation. Users program PLCs to define a series of actions that a machine will perform. The PLC works by reading input signals from devices such as sensors or switches and, depending on the value(s), turning outputs on or off.
In its simplest form, a PLC replaces relay logic. Instead of mechanical devices like interconnected relays or timers providing the logic for a machine or other device, the PLC is a single boxed device performing the same function. Because it is programmable and in essence a computer, it is more flexible, easier to change than physical relay wiring and a great deal smaller than the relay equivalent. It can also perform arithmetic and other functions, such as servo control and analog measurement.
Traditional PLC programming resembles a relay diagram, and for simple diagrams it has the same meaning. However, there are some differences. For example, the diagram works repeatedly from top to bottom rather than all at once (see Figure 1). Additionally, the external-world contacts of relays don't open or close until the bottom of the diagram, input relays change only at the top of the diagram, and there are some restrictions on the connections allowed. This heritage of relays with coils has led the internal state variables of modern PLCs to be commonly know simply as ``coils''.
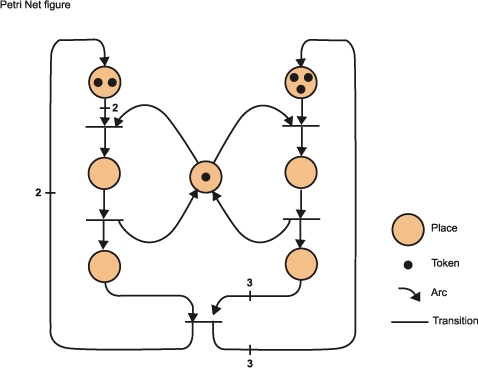
Figure 1. Relay-Like Diagram of PLC Programming
Over time, PLCs have introduced new programming methods that have become dominant in the industry. These fall into two categories: text-based programs and graphical stateflow diagrams. There are many proprietary and nonproprietary standards of varying complexity and functionality for each category. PLCs are usually programmed off-line, using tools running on DOS or Windows. The text-based programs or diagrams are compiled to an intermediate language that is downloaded to the PLC and interpreted.
Although simply replacing relays would be enough to explain the success and popularity of the PLC, a much greater advantage arises from the concept of buses: several PLCs or parts of PLCs on a single cable, communicating, cooperating and reporting to a central control room. This effectively integrates the factory floor into a seamless whole, linked by a barely visible electronic thread.
Since manufacturers have taken different approaches to PLC development, the result is a veritable Tower of Babel. Dozens of product lines provide essentially identical functionality and most are incompatible and non-interoperable. Customers have a choice of vendors but are then locked into that vendor's proprietary solutions. No good open alternatives are available. What Linux is doing for the highly proprietary embedded systems market is what we propose to do for automation with the PuffinPLC.
The PuffinPLC is an interesting study as an embedded controller. Like the PLCs it will replace, it is much more general than most embedded projects. PLCs tend to be very expensive. The PuffinPLC running on an off-the-shelf PC will be more than cost-competitive. Recently, PC-based controllers have emerged, typically running a real-time executive with Windows as a low priority task. If this sounds a lot like what RTAI or RealTime Linux does, that's where we are heading.
Providing a platform for sharing and code reuse should make it possible to raise the productivity of solution providers by at least an order of magnitude, eliminating the enormous waste of maintaining hundreds of parallel solutions. This will allow integrators, consultants and in-house teams to concentrate on their core competencies. A free, open solution will also benefit educators who teach the use of controllers and how they work.
Although the PuffinPLC is intended to emulate a standard PLC, it has a very different architecture. This is partly to take advantage of the fact that it will be running over a full-fledged operating system (in this case Linux), but mostly because we want it to be highly modular to support multiple parties developing code simultaneously.
Unlike standard PLCs, the PuffinPLC does not necessarily run in an infinite loop that reads the inputs, executes the logic and updates the outputs. The PuffinPLC is composed of autonomous modules that, by default, will execute in separate processes. Each of these modules is free to decide whether or not to execute in a standard loop. Communication among the modules is made through a common PuffinPLC library of routines (see Figure 2), written in C and with C header files available. These routines access two common memory areas that together harness the PLC's state and synchronize using semaphores.

Figure 2. Puffin PLC Routine Library
Despite this, however, the standard PLC model permeates the structure: the PuffinPLC library offers PLC-like semantics for the modules that wish to use them. For example, inputs can only change at the beginning of the logic, and outputs are only written at the end of the logic. This means a user's PLC skills can easily be transferred to the PuffinPLC.
Each module is dedicated to a specific function. Some handle physical I/O, reading inputs from I/O boards and copying their states to the PuffinPLC internal coils, or writing the state of other PuffinPLC internal coils to physical outputs. Some modules are dedicated to executing the program logic, and others may be dedicated to communicating with other PLCs. All modules run asynchronously by default but may be synchronized using the PuffinPLC library.
With a modular architecture, contributors can write modules that implement a specific communication protocol, interface to a specific vendor's I/O card or support a specific PLC programming language. End users will be able to pick and choose the modules they use.
A specific module can also have multiple instances running in a working environment. For example, a user wanting to run two digital filters at different sampling frequencies can create two processes of the same digital signal processing (DSP) module with different configurations. Each process will run under a different name, which is configured when the module is launched by a command-line parameter.
This architecture does not differentiate between modules executing logic and modules doing physical I/O. For this reason all the coils of the PuffinPLC are internal coils called plc points, and no output and input coils exist.
The mapping between plc points and physical I/O is left to the configuration of the I/O modules. Therefore, it is possible to have the same plc point mapped to more than one output. The opposite is not supported, however; it would not make sense to have the same plc point reflect two different inputs. For every plc point there is at most one module instance that can change that point (set/reset or set to a value).
For modules to run, the shared memory areas and the semaphore sets need to be set up. This is done by a utility called puffinplc, using the data stored in a configuration file (puffinplc.conf by default). This utility also launches the modules the configuration requires.
The common PuffinPLC library is divided into several sections (see Figure 2):
Configuration memory manager (cmm)--manages the shared memory that stores configuration data.
Global memory manager (gmm)--anages the global memory used to store the state of the plc points.
Synch library--andles the synchronization between modules.
Configuration library--sed for parsing of the configuration files.
Log module-- group of functions that lets every module produce logs in a consistent manner.
A module starts by calling the plc_init() function to initialize access to the common resources that have been set up by the puffinplc utility. The argv and argc variables of the module are forwarded to the plc_init() function call. This allows the PuffinPLC library to be configured at runtime by the end user simply by passing the parameters interpreted by the PLC library (--PLCxxx). This allows the end user to identify the module instance being launched (--PLCmodule=xxx), but also allows the PuffinPLC library to be tailored for a specific purpose.
When a module finishes, it calls the plc_close() function. Both these functions call the relevant init() or close() functions of each section of the PuffinPLC library. Apart from the previous functions, the plc_setup() and plc_shutdown() functions do the actual initialization of the common resources and are called by the puffinplc utility.
The configuration memory area is where the current configuration of the PLC is stored. This guarantees every module uses the same configuration data. Every access to the configuration memory area is made through the cmm. At present, the cmm does not have a public interface, so the modules themselves never access the cmm directly but always through other sections of the PuffinPLC library.
Several PuffinPLCs can run simultaneously on the same system. Each is distinguished by the configuration memory area it uses, identified by a unique number. When a module is launched, the identity of the PuffinPLC to which it should attach is specified as a command-line parameter (--PLCplc_id=xxx).
The cmm views the configuration memory as a simple, linked list of memory blocks that have been allocated and another list of empty memory blocks. The memory blocks are allocated by the cmm when requested by other sections of the PuffinPLC library. This currently occurs only during resource setup. Each block has a type identifier (1 byte) and a name (31 character string). During each module initialization, the PuffinPLC library requests the relevant block of memory using these identifiers. The type identifier is used to identify the structure of the data stored within that memory block; the name allows several data structures of the same type to be stored.
The gmm manages the global shared memory, which stores the state of the plc points (i.e., plc internal coils). Plc points, with a size between zero and 32 bits, are configured in the configuration file with a unique name. At setup, this configuration is copied into the configuration memory. Modules access these points solely by using handles through the gmm library. A handle to a point is obtained by calling a gmm function to which the name of the point is passed.
Each module has its own private memory map and a private map mask, both created upon module initialization and both independent from the global memory map. When a module accesses a plc point, it is actually accessing its private memory map. Private and global memory maps are synchronized by calling the plc_update() function of the gmm. Synchronization is controlled by a semaphore that provides atomic updates. During synchronization, only the plc points that the module has write access for are copied into the global memory map. All other plc points are copied from the global memory map into the private memory map. The map mask is used to determine whether a module has write access to a plc point. All three maps are exactly the same size and use the same locations to store the plc points, allowing the update to be made as a simple, bit-for-bit logical function. The update must be made quickly because it requires access to a common shared resource (the global memory map) and may therefore become a bottleneck. Because of the use of a common shared resource controlled by a semaphore, using the PuffinPLC in a hard real-time environment will require the use of a scheduling mechanism that bounds priority inversion.
The use of private memory maps allows modules to run asynchronously without interfering with one another. Although it is not mandatory, it is expected that modules will run in an infinite loop, synchronizing their private memory maps at the beginning and end of each loop iteration. This guarantees that while the module is running its logic, the state of the plc points will not be changed by other modules executing their own logic or doing I/O. Nevertheless, the PuffinPLC architecture is sufficiently flexible to support modules that do not execute in an infinite loop; these may synchronize their private maps (in whole or in part) when they see fit.
Currently the gmm provides two alternative strategies to achieve the described functionality. Either of these strategies may be chosen when a module is launched by including one of two command-line options, --PLClocal or --PLCisolate.
The default strategy (--PLClocal) places the private memory map and the memory map mask in the module's heap and accesses the global memory as shared memory mapped onto the module's virtual memory address space. This has the drawback that if the module is badly written, a stray pointer may access the PLC's global memory map without going through the global memory, potentially creating havoc.
In the second strategy (--PLCisolate), the module forks a second process. The first process executes the module logic and accesses the private memory map, but it never actually maps the gmm into its virtual address space. The second process uses the shared memory mechanism to access both the gmm and the private map of the first process. Whenever the first process requests a memory map synchronization, it sends the request through a socket to the second process. The second process actually performs the memory map synchronization. This strategy involves large delays for each memory synchronization, but it does allow a developer to isolate a module that has not been thoroughly tested, making debugging easier.
The mechanism employed by the gmm enforces semantics very similar to those in existing standard PLCs, but the two are not exactly the same. Situations arise where the exact same semantics are required, and this is resolved by the synchronization library. This library simplifies the task of the module programmer but leaves a lot of flexibility for the end user.
The synchronization library uses standard semaphores to synchronize the modules but does not make this apparent at its higher level interface. Module synchronization revolves around the concept of synchronization points. The end user can configure a PuffinPLC with a certain number of synchronization points (or synch points). The configuration data of synch points is loaded into the configuration memory upon PLC setup. Modules obtain handles to these points and then call a synchronization primitive to wait at a specified synch point. Having the module obtain the name of the synch point from the configuration file allows the end user complete flexibility in specifying the synchronization sequence for the application.
The end user must also define a petri net model (see Sidebar) of the sequence of events they wish to enforce. Synchronization points may be associated with the complete firing of a transition, the removal of tokens of a firing transition or the insertion of tokens of a firing transition. We also plan to support the association of synchronization points to the existence of a certain number of tokens in a place, the arrival of tokens in a place or the removal of tokens from a place, but some of these require more support from the operating system than is currently offered.
Modules waiting on a synchronization point associated with the firing of a transition will block until the transition is fired. Synchronization points associated with the insertion of places of a firing transition will never block, but they will insert the appropriate number of tokens into the places where a module synchronizes with this point. This, and the fact that the PuffinPLC will not fire a transition unless there is a module waiting on a synchronization point associated with that transition, implies that the semantics the PuffinPLC supports for the synchronization petri net are not exactly those of standard petri nets. But a modified petri net provides a base from which to work.
Using a petri net model allows very complex synchronization semantics. Nevertheless, due to the complexity of configuring this model, a simplified configuration syntax is also supported; it consists of a simple execution sequence for modules. This sequence is automatically transformed into its equivalent petri net model upon setup.
Every module is required to call plc_scan_beg() and plc_scan_end() before commencing and upon completion of its scan loop. These functions synchronize with two default synch points that, if not configured, will map to the null synch point that continues execution without delay. These two functions provide the hooks for the synch library to provide module synchronization in a standard form. Modules that wish to synchronize at other locations of execution can use additional synch points as desired.
The configuration library is a collection of functions that help parse the configuration file. The file is completely parsed upon module initialization and loaded into the module's heap memory. To obtain specific configuration data, the module calls functions that scan the parsed file from the heap memory. The configuration file may include other files using the *include directive. Circular includes are detected and supported.
The configuration file may contain name = value pairs or data organized in a table, for example:
table_name value_1_1 value_1_2 table_name value_2_1 table_name value_3_1 value_3_2 value_3_3
These values may be grouped into sections under the [section_name] syntax. Generally, the data required for PLC setup, such as plc points, synchronization points and model, are all placed under the [PLC] section. Other sections should contain the name of the module instance and the configuration data for that module.
The log library is a group of functions that provide common logging facilities for all PuffinPLC-related processes. Currently, nine logging levels are supported for error, warning and trace messages. These messages, with an additional timestamp, are placed into a logging file. We plan to offer the option of forwarding these messages to the syslog subsystem, taking advantage of the forwarding capabilities of TCP/IP to a remote message concentrator.
The PuffinPLC makes liberal use of memory, inconsistent with a program that will be run in embedded applications. Two main areas need to be augmented to fulfill this requirement: the configuration file parsing library and the gmm.
Currently, in a running PuffinPLC with five modules, all five modules will parse the configuration file and load it into memory. Once there, the relevant data for the module will be copied into its internal data structures. This, and the existence of the configuration file, leads to very poor use of memory.
This situation will be rectified by requiring the modules to store their internal state in the configuration memory. This will allow the modules to be broken into two independent processes. The first will parse the configuration file, allocate enough memory from the cmm for its internal state variables and initialize this memory. The second process asks the cmm for the location of its initialized state variables and then executes the module logic. The first process may be run on the developing platform and is not required to run in the target platform. We have to make a copy of the already-initialized configuration memory for the target platform. This removes the requirement for the configuration file and the multiple copies of its parsed form in the target platform's memory.
The second area that needs to be augmented is the gmm. The current architecture makes sense if we want to take full advantage of the capabilities of the underlying OS. Unfortunately, this requires multiple copies of the memory map (i.e., a global memory and a private memory map for each module). In many situations, end users will not require these capabilities and will have the modules synchronized to run in lockstep, one after another. In this case, a single process may suffice. We are planning on expanding the methods of accessing the global memory map, such as dispensing with private memory maps and accessing the global memory map directly. Eliminating the need to synchronize the memory maps will save memory and increase speed. On the other hand, it will mean the modules must be run in lockstep, one after another, to preserve the PLC semantics.
We are well on our way toward completing several basic modules that will provide the standard capabilities of PLCs. While some will be running user-defined logic, others will be communicating with the real world. Logic-based modules will provide support for specific PLC programming languages (e.g., IEC compiler) and commonly executed functions (e.g., dsp). I/O modules all take PuffinPLC points and either transmit them over a network using a specific protocol (e.g., modbus) or turn them into real, electrical signals that move cylinders and motors (e.g., DIO48). They may also take electrical signals from devices such as buttons and proximity switches and turn them into PuffinPLC points.
The IEC 61131-3 language compiler is not yet fully functional. This compiler will compile IEC ST (structured text) and IL (instruction logic) programs into C++ modules. Each compiled program will be an independent PuffinPLC module. Debugging support will probably be provided by an IEC language interpreter.
The IL compiler is a Perl-written compiler of a nonstandard, simple instruction logic language. This language provides only basic logic operations (e.g., LOAD, AND, OR, OUT) and is intended as a stop-gap until the IEC compiler is working, allowing for easier testing of other PuffinPLC components.
The digital signal processing (dsp) module provides signal-handling capabilities. The dsp module itself is composed of submodules or blocks that implement basic signal-processing algorithms. The user can string these submodules together to implement the desired functionality.
Currently we have adder, PID, filter, alarm, ramp, nonlinear and type conversion blocks. In the future, we expect to have multiplier, hysteresis, FFT, delay and signal source blocks. The dsp module executes the blocks in the same order in which they are configured.
All blocks except the type converter expect inputs to be in 32-bit, floating-point format and provide output in the same format. The type converter can convert data to/from (unsigned) integers of several sizes, from/to 32-bit, floating-point format. The adder adds a variable number of inputs, each scaled by a configurable constant, to provide a single output. The PID block provides an open-loop PID (proportional, integral, derivative) controller. Closed-loop controllers can be implemented by closing the loop with an adder block. The PID block does not assume fixed period scans of the dsp module, as it takes into account the elapsed time between every two successive scans.
The filter block implements infinite impulse response (IIR) and finite impulse response (FIR) filters using canonical, second order sections. These filters can be configured directly or by giving the desired frequency and attenuation response, along with the desired analog transfer function type (butterworth, chebyshev, elliptic, bessel). This block, unlike the PID, assumes fixed period scans of the dsp module.
The alarm block allows Boolean alarms to be set depending on the input value. This block supports alarm activation when the input value is larger than, less than, equal to or different from a specified constant.
The ramp block provides an output that follows the input but whose maximum first and second derivatives may be limited. Maximum positive and negative derivatives may be set independently.
The nonlinear block implements dead-band and limiting functions.
This simple, curses-based display can show the status of PuffinPLC points as they change. The data in the plc point may be in any of several integer formats or a 32-bit float. Support for basic graph drawing, based on the values of plc points, is currently being added. While in some ways the vitrine may be considered a stop-gap, many applications will not need the full power of a graphical interface and will appreciate the lower CPU demands of plain text.
This is an I/O module or, more precisely, an input-only module. It maps the states of keyboard keys to PuffinPLC points. It is intended primarily for debugging and demonstration purposes.
The parallel port module was written to provide support for cheap, physical I/O. It will allow users with low budgets to evaluate the potential of the PuffinPLC or use it in simple settings. The parallel port provides eight LS TTL level inputs/outputs, five LS TTL level inputs and four TTL open collector outputs. These last four outputs can sometimes also work as inputs when placed in their high impedance state.
Two modules support the modbus protocols, one for modbus_tcp and another for modbus_rtu. These modules allow the PuffinPLC to communicate with the real world by Ethernet (modbus_tcp) or a serial port (modbus_rtu).
Physical I/O is also possible using extra I/O boards. Currently the CIO-DIO(48, 96, 192) digital I/O boards are supported by the DIO48 module. These cards are based on the 8255 integrated circuit. The 8255 chip is used in most industrial PC I/O boards, so this module covers a great range of relatively high-speed I/O.
We will soon start work on supporting fieldbus network cards made by Hilscher (http://www.hilscher.com/), as they have kindly made some of their cards available to the project. These cards will allow the PuffinPLC to communicate with practically any networked device on the factory floor. They support ASI, CANopen, ControlNet, DeviceNet, InterBus, ModConnect, ProfiBus and SDS communication protocols.
With the help of its original author, Hugh Jack, we will be porting an AB PLC5 emulator as a PuffinPLC module. This will allow the PuffinPLC to execute existing AB PLC5 programs, easing the transition to a PuffinPLC.
Code for the PuffinPLC can be obtained from the project's CVS server at our web site, http://www.puffinplc.org/. A first full release is expected shortly. In the meantime, the project is evolving in many directions, including support for other hardware and communication protocols.
Although the project is still in its infancy, it is already possible to identify some of the hurdles we face. It has not been easy to get people from the automation industry involved in writing code, mainly because of time limitations and sometimes due to a lack of Linux-based programming knowledge. Nevertheless, we have a large, silent following that will prove very useful when the time comes for debugging the beta releases. Another obstacle is obtaining copies of communication protocol standards. Some are very expensive; some standards bodies require an official organization to represent the PuffinPLC as a member; and some standards require expensive conformance testing to use their protocol name. This is why we do not expect to directly support, in the near future, many of the communication protocols used in factory automation. For now, we will support commercial add-on cards that implement these protocols.
Despite these obstacles, the industry has already begun to provide support for this project. Help has come from integrators interested in the success of the project and PC hardware vendors that want their hardware to work with the PuffinPLC.
I would like to finish by thanking Jiri Baum for coming up with the basic PuffinPLC architecture and for having written many modules besides the initial version of the library. He is still actively contributing to the project. I would also like to thank David Campbell (IEC compiler) and Philip Costigan (Modbus modules) for their continuing contributions. I also appreciate the help of Curt Wuollet, the project's founder, Jiri, for having written the article's introduction and the staff at Control.com for helping out with the drawings.

Mario de Sousa, an electrical engineer, is currently a lecturer on industrial automation systems in Porto University's engineering faculty. He is the proud father of two-month-old Catarina, who seems to be taking up most of his spare (and non-spare) time. He can be reached by e-mail at msousa@fe.up.pt.
email: msousa@fe.up.pt

