
Linux on Carrier Grade Web Servers
ARIES (Advanced Research on Internet E-Servers) is a project that started at Ericsson Research Canada in January 2000. It aimed at finding and prototyping the necessary technology to prove the feasibility of a clustered internet server that demonstrates telecom-grade characteristics using Linux and open-source software as the base technology. These characteristics feature guaranteed continuous availability, guaranteed response time, high scalability and high performance.
Traffic distribution was one of the main research topics because we needed a software-based solution that was very reliable, high performance and yet very scalable to distribute web traffic among multiple CPUs within the cluster. The first activity we conducted was to survey the Open Source community and see what solutions were already implemented, try them out on our experimental Linux cluster and see which solution best met our requirements (or part of them).
This article covers our experience with the Linux Virtual Server (LVS), a software package that provides traffic distribution on top of Linux. We will explain the architecture, operation and algorithms of LVS and describe our test system and benchmarking environment as well as the experiments we conducted to test LVS's robustness and scalability.
The traffic on the Internet is growing at over 100% every six months. Thus, the workload on the servers is increasing rapidly, and these servers are easily overloaded.
To overcome this problem there are several solutions. The most interesting one is the multiserver solution that consists of building a scalable server on a cluster of servers. When the load increases, more servers can be added into the cluster to meet the increasing requests. The multiserver architecture provides good flexibility (adding and removing nodes) and availability since there is no downtime associated with it. A second advantage is that the real servers do not need to be homogeneous, which allows for the recycling of some old workstations. A third advantage is transparency: the cluster is presented to the users as a single IP that maps requests to multiple servers at the back end.
The Linux Virtual Server follows the multiserver model and provides a software-based solution for traffic distribution as opposed to hardware-based solutions.
Our research in the ARIES Project was directed toward a multiserver architecture that is able to achieve linear scalability reflected through a continuous growth to meet increasing demands, continuous service availability achieved through building redundancy at all levels of the architecture and ease and completeness of management without affecting the uptime of the system.
We were naturally interested in LVS as an HTTP traffic distribution solution because the architecture of the cluster will be transparent to end users, and thus the whole system would appear with a single IP address. Furthermore, LVS claims to be highly available by detecting node or dæmon failures and reconfiguring the system appropriately so that the workload can be taken over by the remaining nodes in the cluster. This is a very important feature for systems geared toward high availability.
The LVS Project is an open-source project to cluster many servers together into a highly available and high-performance virtual server that provides good scalability, reliability and serviceability. The LVS director provides IP-level load balancing to make parallel services of the cluster appear as a virtual service on a single IP address.
The LVS Project is currently cooperating with the High Availability Linux Project that aims at providing a high-availability (clustering) solution for Linux, which promotes reliability, availability and serviceability (RAS) through a community-development effort.
In an LVS setup, the real servers may be interconnected by a high-speed LAN or by geographically dispersed WAN. On the other hand, the front end of the real servers, called director, is a load balancer that distributes requests to the different servers. All requests are sent to the front-end director with the virtual IP address, and the cluster appears as a virtual service on a single IP address.
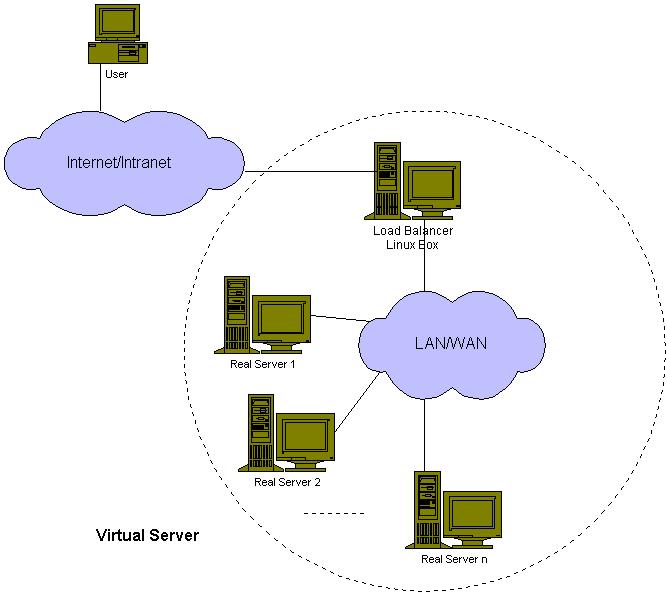
Figure 1. LVS Architecture
This architecture is flexible because it allows transparently adding or removing real server nodes, and it is geared toward high availability by automatically detecting nodes or dæmons failures and reconfiguring the system appropriately. For added availability, we can setup a second director as a hot swap for the primary director, thus eliminating a possible single point of failure.
LVS is implemented in three IP load-balancing techniques. One is virtual server via network address translation (NAT), the second is virtual server via IP tunneling and the third is virtual server via direct routing. When we conducted this activity, the NAT implementation was very stable compared to the others. Therefore, we decided to setup LVS using NAT.
The LVS-NAT implementation was necessary due to the large usage of private addresses. For many reasons, including the shortage of IP addresses in IPv4 for security reasons, more networks are using private IP addresses that cannot be used outside the network.
Network address translation relies on the fact that the headers for internet protocols can be adjusted appropriately so that clients believe they are contacting one IP address, but servers at different IP addresses believe they are contacted directly by the clients. This feature can be used to build a virtual server, i.e., parallel services at the different IP addresses can appear as a virtual service on a single IP address via NAT.
The architecture of a virtual server via NAT is illustrated in Figure 2. The load balancer and real servers are interconnected by a switch or a hub. The real servers usually run the same service, and they have the same set of contents. The contents are replicated on each server's local disk, shared on a network filesystem or served by a distributed filesystem. The load balancer dispatches requests to different real servers via NAT.
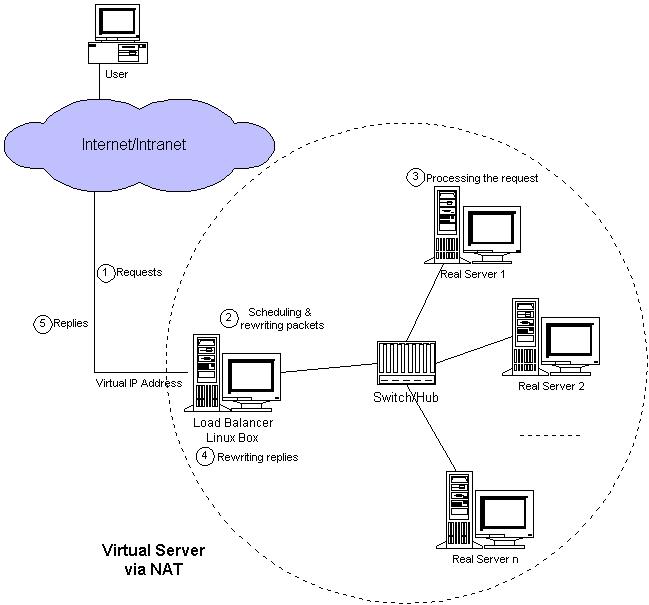
Figure 2. Virtual Server via NAT
The process of address translation is divided into several steps:
The user accesses the service provided by the server cluster.
The request packet arrives at the load balancer through the external IP address of the load balancer.
The load balancer examines the packet's destination address and port number. If they match a virtual server service (according to the virtual server rule table), then a real server is chosen from the cluster by a scheduling algorithm, and the connection is added into the hash table, which records all established connections.
The destination address and the port of the packet are rewritten to those of the chosen server, and the packet is forwarded to the real server.
When the incoming packet belongs to this connection, and the established connection can be found in the hash table, the packet will be rewritten and forwarded to the chosen server.
When the reply packets come back from the real server to the load balancer, the load balancer rewrites the source address and port of the packets to those of the virtual service.
When the connection terminates or timeouts, the connection record will be removed from the hash table.
LVS supports four scheduling algorithms: round-robin, weighted round-robin, least-connection scheduling and weighted-least-connection scheduling. The round-robin algorithm directs the network connections to the different server in a round-robin manner. It treats all real servers as equals regardless of number of connections or response time. The weighted round-robin scheduling is able to treat the real servers of different processing capacities. Each server can be assigned a weight and integer value, indicating its processing capacity, and the director schedules requests depending on the server's weight in a round-robin fashion.
The least-connection scheduling algorithm directs network connections to the server with the least number of established connections. This is a dynamic scheduling algorithm because it needs to count live connections for each server dynamically. At a virtual server where there is a collection of servers with similar performance, the least-connection scheduling is good for smoothing distribution when the load of requests varies a lot because all long requests won't have a chance to be directed to a server.
The weighted least-connection scheduling is a superset of the least-connection scheduling in which you can assign a performance weight to each real server. The servers with a higher weight value will receive a larger percentage of live connections at any one time. The virtual server administrator can assign a weight to each real server, and network connections are scheduled to each server in which the percentage of the current number of live connections is a ratio to its weight. The default weight is one.
For the purpose of testing and evaluating LVS's performance, we setup a powerful testing environment at the Ericsson Research Lab in Montréal that consisted of eight CompactPCI diskless Pentium III CPU cards running at 500MHz with 512MB of RAM. The CPUs have two on-board Ethernet ports, and each CPU is paired with a four-port ZNYX Ethernet card. Our setup also included a CPU with the same configuration as the others except that it has three SCSI disks: 18GB each configured with a RAID-1 and RAID-5 setup. This CPU acts as the NFS, DHCP, Bpbatch and TFTP server for the other CPUs.
The CPUs use the Linux kernel 2.2.14-5.0 that comes with the Red Hat 6.2 distribution. When we start the CPUs, they boot from LAN and broadcast a DHCP request to all addresses on the network. The DHCP server (the CPU with disk) will reply with a DHCP offer and will send the CPUs the information they need to configure network settings such as IP-addresses (one for each interface, eth0 and eth1), gateway, netmask, domain name, the IP address of the boot server and the name of the boot file. Using bpbatch, a freeware preboot software, the diskless CPUs will then download and boot the specified boot file in the bpbatch configuration file. The boot file is a kernel image located under the /tftpboot directory on the bpbatch server. Finally, the CPUs will download a RAM disk and start the Apache web server.
The Apache web server is part of the RAM disk that is downloaded by the CPUs. Because we have a homogeneous environment, all the CPUs share the same configuration files and serve the same content, which is available via NFS.
To conduct benchmarking activities, we setup a hardware and a software benchmarking environment. At the hardware level, we used 18 Intel Celeron 500MHz 1U rackmount units with 512MB of RAM each. These machines were used to generate web traffic using WebBench, a freeware tool available from zdnet.com.

Figure 3. WebBench Architecture
WebBench is a software tool for measuring the performance of web servers. It consists of one controller and many clients (Figure 3). The controller provides means to setup, start, stop and monitor the WebBench tests. It is also responsible for gathering and analyzing the data reported from the clients (Figure 4). On the other hand, the clients execute the WebBench tests and send requests to the server.
Figure 4. WebBench Control Window with 379 Connected Clients Ready to Generate Traffic
To build the setup, we decided to use the CPU with disk as the Linux Virtual Server and the eight diskless CPUs, running the Apache server, as traffic processors.
As mentioned previously, we were using the Linux kernel supplied with Red Hat 6.2. This kernel comes with LVS support, and thus there was no need to do any work at the kernel level. We only needed to perform the configuration. For those who like GUI configuration tools, they will find the LVS GUI-configuring tool a definite advantage. It is a complete tool to setup and manage an LVS environment, and it is easy to use. However, we performed our configuration manually—a matter of personal preference.
If you are not using a kernel provided with Red Hat (6.1 or later), then you need to build a new kernel and setup IP masquerading and IP chain rules manually. The kernel you build must have support for the following options: network firewalls, IP forwarding/gatewaying, IP firewaling, IP masquerading, IP: ipportfw masq and the Virtual Server support.
At the same time, you need to choose a scheduling algorithm from among the following: weighted round-robin, least-connection or the weighted-least connection.
Once this is done, you compile the kernel, update your system and reboot. After rebooting with the new kernel, you need to setup the IP configuration for the NAT director, which includes setting an alias IP address to be used for access from outside the cluster and setting an alias for the NAT router for access from inside the cluster and enabling ip_forward and ip_always_defrag on NAT director.
When we completed these steps, we configured LVS by editing the lvs.conf file and started the lvs binary that came with Red Hat. It performed the necessary ipvsadm commands for the LVS server and the real servers.
Please note that if you are not using the Red Hat distribution, then you need to start the ipvsadm commands manually. After that, you need to start ipchains with the forward and MASQ options.
If you plan to deploy LVS in a LAN environment, you have to be careful when isolating the real servers from the rest of the LAN and from the outside world. There must be no direct route from any real server to the web clients. This is very important because if the HTTP answer packets go to the client through a way other than the NAT director, they will be discarded by the client. One easy way to achieve this is to build your own private subnet and use the NAT director as your gateway to the rest of the LAN.
The goal of the benchmarking tests was to test the scalability of the LVS-NAT implementation. For this purpose, we carried two kinds of tests: the first one was a direct approach that consisted of sending traffic directly to the CPUs; the second approach was to direct the traffic to the NAT director that is the front-end server for the CPUs.
For the tests conducted without LVS, we sent HTTP requests directly to the real servers. WebBench supports this configuration by generating web traffic and sending them to multiple servers (Figure 5). As for the tests with LVS (Figure 6), we configured WebBench to send the HTTP requests to the LVS server (the NAT director), which in turn directed the traffic to the real servers.

Figure 5. The Benchmarking Setup without LVS

Figure 6. The Benchmarking Setup with LVS-NAT
Figure 7 shows the number of requests per second our LVS setup was able to achieve versus a direct setup without LVS. It clearly shows that the LVS-NAT implementation suffers from a bottleneck at the director level once it reaches 2,000 requests per second.

Figure 7. LVS vs. Non-LVS Results
We decided to conduct a third test using only one machine to generate traffic with WebBench. We measured a latency of 0.3 milliseconds for answering HTTP requests. LVS handled the load successfully answering more than 178 requests per second.
After analyzing the results, we concluded that the bottleneck problem is due to the number of simultaneous TCP connections per second that the LVS director can handle. The results show that the maximum number of connections handled simultaneously by LVS is not more than 1,790 valid TCP connections per second. Without using LVS, by sending requests directly to servers, we have been able to achieve more than 7,116 valid TCP connections per second. We plan to investigate this issue in more detail in the coming weeks.
The NAT implementation of LVS has several advantages. First, the real servers can run any operating system that supports the TCP/IP protocol and they can use private internet addresses. As a result, the whole setup would only require one IP address for the load balancer.
However, the drawback of using the NAT implementation is the scalability of the virtual server. As we have seen in the benchmarking tests, the load balancer presents a bottleneck for the whole system.
LVS via NAT can meet the performance request of many small to mid-size servers. When the load balancer becomes a bottleneck, then you need to consider the other two methods offered by LVS: IP tunneling or direct routing.
We tested LVS in an industrial environment with one LVS Server and eight traffic CPUs. We found some restrictions when using LVS under heavy load. However, we also found LVS to be easy to install and manage and very useful.
We believe that LVS is a potential solution for small to mid-size web farms that need a software-based solution for traffic distribution. However, for the kind of servers we are building, the requirements necessitate a higher number of transactions per second than the NAT implementation of LVS can handle.
LVS's future is promising with the determination to add more load-balancing algorithms and geographic-based scheduling for the virtual server via IP tunneling. Another promising future feature is the integration of the heartbeat code and the CODA distributed fault-tolerant filesystem into the virtual server. LVS's developers are also planning to explore higher degrees of fault-tolerance and how to implement the virtual server in IPv6.
Compared to other packages, LVS provides many unique features such as the support for multiple-scheduling algorithms and for various methods of requests forwarding (NAT, direct routing, tunneling). Our next step regarding LVS is to try out the other two implementations (direct routing and IP tunneling) and compare the performance with the NAT implementation on the same setup.
The Systems Research Department at Ericsson Research Canada for approving the publication of this article.
Evangeline Paquin, Ericsson Research Canada, for her contributions to the overall LVS-related activities.
Marc Chatel, Ericsson Research Canada, for his considerable help in the ECUR Lab.
Wensong Zhang, the LVS Project, for the permission to use Figures 1 and 2 from the LVS web site.



