
Enterprise-Level Health-Care Applications
Today most health-care companies are struggling to find ways to improve patient care, reduce costs and provide more and better service. They increasingly see technology as a solution to these requirements. Our company is no different. We have approximately 1,300 employees in 13 states and 40 offices. Our existing patient care system and financial accounting system were developed over ten years ago and were not designed to handle the requirements of a large, distributed organization.
Many members of our executive team have backgrounds in high-volume claims processing, where millions of claims have to be processed daily on high availability systems. Our CEO and the executive team defined the following requirements for our new IT applications:
It must be scalable, portable, reliable and secure.
It must address the requirements of the Health Insurance Portability and Accountability Act (HIPAA).
It must integrate all our applications and provide business-to-business (B2B) capability.
It must meet the “four As” of availability: accessible, anytime, anywhere and on any device.
It must be cost effective.
Scalability is a matter of survival. Many vendors have said, “hardware is so cheap, just throw more hardware at it.” This is a good solution until you are responsible for a budget and getting it past a CFO. In our situation we must not sacrifice one byte of memory, one processor cycle nor one block of disk to bloated, inefficient applications and systems.
Portability and scalability are related. If our application is written on an Intel platform, but must run on a mainframe to perform as needed, that application must be portable to different operating systems running on different hardware. Our hardware selection today may change a year from now based on speed, cost, support, reliability and available talent to run the system. We can't replace our applications whenever we change our hardware.
HIPAA, passed by the US Congress and signed into law in 2000, has tremendous implications for health-care companies. These laws take effect in 2002. HIPAA's authors intended to standardize how claims are processed, how data is exchanged between companies and how patient information is accessed and stored. The applications and systems we run must conform to HIPAA requirements and must change with the regulatory environment. Health-care companies will spend two to three times the cost of Y2K on HIPAA conformance, according to industry analysts.
Industry analysts also claim that health care is one of the last industries to take significant advantage of advances in information technology. Many health-care companies' information systems run on old, sometimes very old, technology, and our systems must communicate with them. When we enroll a patient in our medical information system, we must automatically enroll that patient in our pharmacy provider's system so the patient can fill their prescriptions anywhere in the US the same day. We must also send information to our medical supply company to allow the patient to get medical supplies without excessive delay.
Our company evaluated over 50 health-care applications. None could address our needs. Some companies had just invested millions of dollars to go from DOS application to client/server, 32-bit Windows applications. Some had DOS applications and just looked at us funny when we tried to explain what we wanted. In the end we found nothing that fit our needs. Our solution was to put together a team of highly experienced developers with backgrounds in high-volume transaction processing and build a transaction backbone and the applications to run on top of it.
Our first task was to define the broad outlines of the architecture. We wanted an N-tier architecture, but beyond that we wanted one that placed no limits on possible solutions. We evaluated several transaction engines and application servers. All failed to satisfy our requirements. Commercial transaction engines were either extremely expensive to purchase, maintain and develop on or they were too inflexible or unreliable for us.
How much reliability do we require? If an e-tailer goes down .1% of the time, about nine hours per year, the worst likely outcome is the loss of some orders. However, when a nurse needs to access patient records to learn a patient's medication and dosage, downtime is a different issue. It's simply not acceptable.
The build or buy decision was easy, there was nothing to buy. We chose to build a transaction engine on steroids—eTransMan. eTransMan, eCommerce Transaction Manager, is the result (see Figure 1).
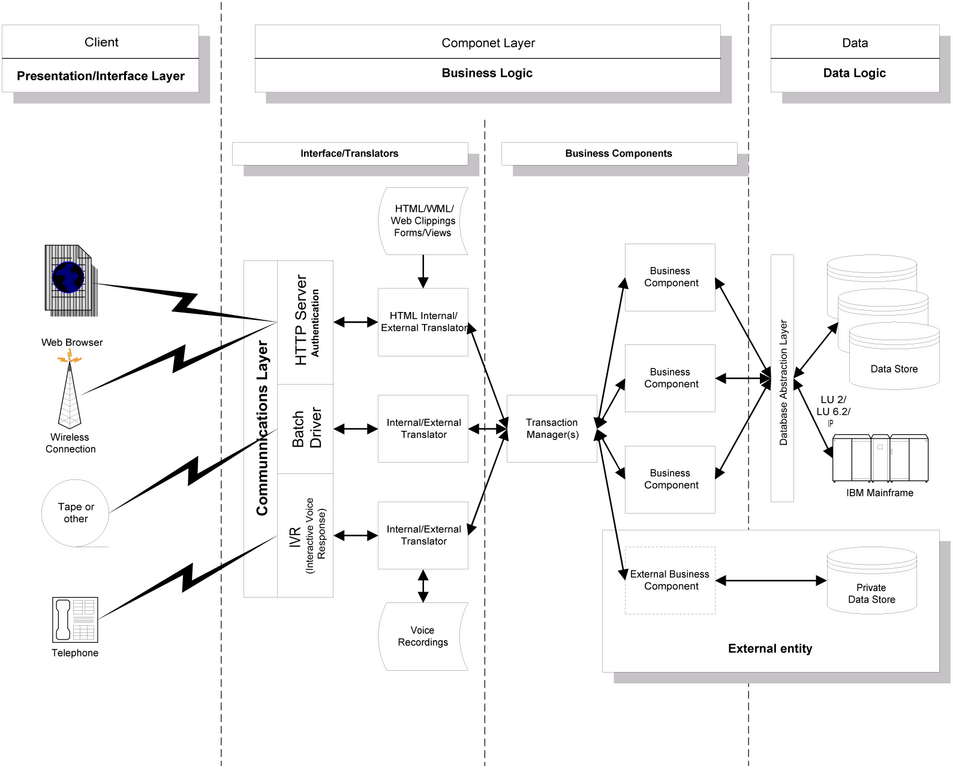
Figure 1. Architectural Overview
eTransMan is the heart of an easy-to-use architecture that provides an environment where developers easily build and manage N-tier applications for health care's pervasive computing environment. Developers write their business processes as modular components using any computer language—C, C++, Java, COBOL, Perl, Visual Basic and even assembler. eTransMan runs these components in a highly scalable, portable, high-performance, secure transaction environment.
Developing components for eTransMan is simple by design. Our company's developers write business components in C++ and Java. Other companies may not have developers with these skills. They may only have COBOL, Visual Basic or PowerBuilder developers. With eTransMan, companies avoid the time and expense of a weeklong class just to learn how to the transaction engine followed by another week of Java or C++ training.
The Transaction Manager is the architectural hub of eTransMan. The Transaction Manager provides fault tolerance, load balancing, scheduling, security and business component location (routing).
eTransMan's architecture is based upon the classic N-tier model with some enhancements. This model separates the presentation, business logic and data access layers. The main goals of this architecture were to:
create a transaction manager capable of very high transaction throughput on modest hardware;
create a component-based architecture that is robust, reliable and easy to manage and control in a production environment; and
enable component developers to design and add business components to the infrastructure as simply and as quickly as possible, with a minimum understanding of the architecture.
The Transaction Manager is written in C/C++ on Linux and compiled with the open-source gcc compiler. We can thus easily port to any system that supports gcc, from embedded platforms to an IBM 390 mainframe. eTransMan has exceeded performance expectation due to the efficient engineering provided on this platform. We are currently running eTransMan on two dual PIII 700 servers. The total production hardware cost was under $30,000 for 40 sites serving 450 on-line users (see Figure 2). Resources are only allocated when needed, enabling rapid responses on our modest hardware. Load average is never more than 2%. eTransMan is a compiled application, so it runs without an interpreter.

Figure 2. Attached File Servers
eTransMan includes many features that support high-application availability: processing of availability checks, timeout checks, automatic component restart and recovery procedures and user-definable recovery procedures. Business components run as dæmons for extremely fast response from the Apache web server. eTransMan not only controls the flow of activity in the application but also ensures smooth, efficient operations of all components (see Figure 3).
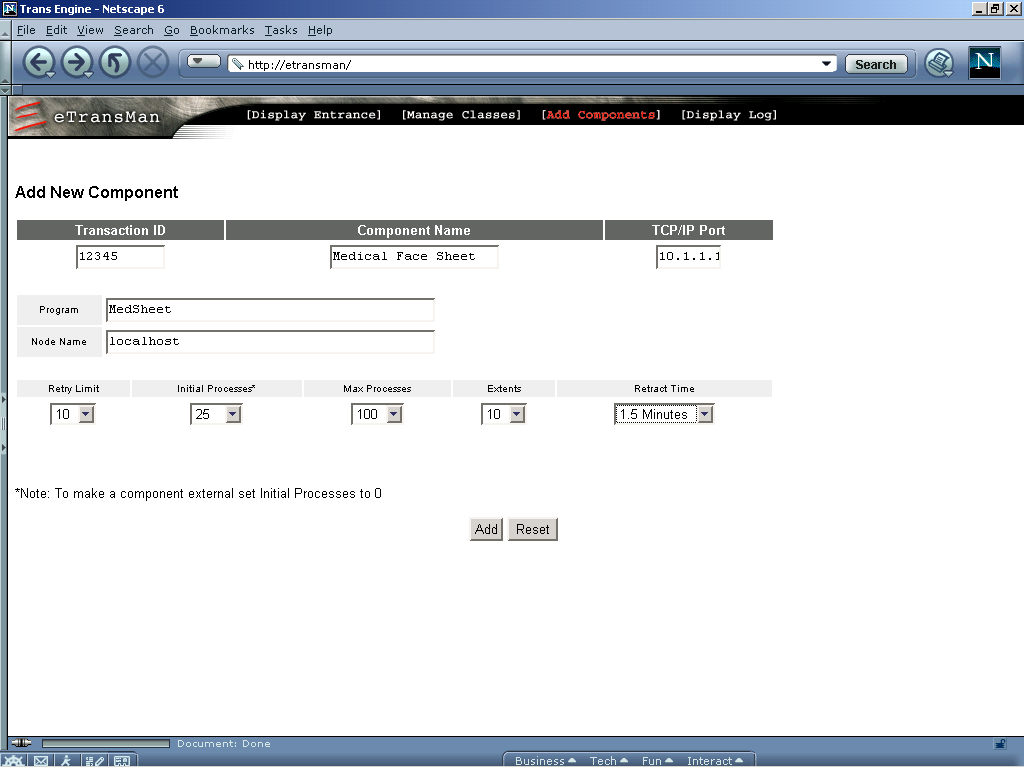
Figure 3. Managing the Flow of Activity
eTransMan balances the load between multiple identical components to ensure maximum application throughput. eTransMan tracks which components are available for a specific transaction. It dynamically creates additional component instances to handle increased transactional demands, destroying them when they are no longer needed. This feature allows eTransMan to allocate resources optimally to satisfy current demands. Using Linux's open architecture, eTransMan can dynamically map requests to components, exercising broad control over the flow of processing for the applications.
By multiplexing and managing the relationships between clients and applications, eTransMan provides all the capabilities needed for mission- and business-critical applications, including the capacity for large volumes of centralized or distributed data, high-message throughput, high data integrity and security and high-application availability, including 24/7 processing.
Resources are used as specified by configuration files but are only used as necessary, enabling rapid responses on modest hardware. We built a web interface to manage our configuration files. The eTransMan architecture follows the N-tier model. The workflow progresses as follows:
Intelligent data clients, such as Linux workstations, Windows 2000/98/95 workstations, Mac workstations, Wireless Devices, Interactive Voice Response Systems (IVR), virtually all commercial versions of UNIX, batch inputs, point-of-sale terminals, video data stream and other devices optimized for specific data and presentation functions gather information for subsequent processing and display information.
Client-specific interpreters prepare data for eTransMan. Interpreters package the incoming data stream in a format that the business components expect. The interpreters then forward the data client's request to eTransMan. Adding a new user client is as easy as creating a translator that can convert client-specific data formats to and from the simple eTransMan data exchange format. The business logic never changes.
eTransMan validates the transaction request and then forwards the request and data to the business component.
Components can access databases with several methods. To minimize cost and increase efficiency we developed our own pooled database component to access our Oracle 8i database running on Linux. We can connect to other databases via native libraries, ODBC, JDBC or via an HLLAPI component on a mainframe. Our business component returns the response and associated data back to eTransMan, which sends the response back to the interpreter. The interpreter formats the data according to its own rules.
One type of data interpreter supplied with the eTransMan architecture matches the response and associated data with a template. The interpreter merges the data with the template in the client's native format and returns the result. Templates can handle singleton or tabular data in the same response.
When the Transaction Manager receives a response from the component, it forwards the response to the communication layer that sent the request. The communication layer then translates the result into a format that is recognizable by the data client. The data is then sent back to the client in its native format.
We needed to make changing the user interface as easy as possible. The first test came when we wanted to adapt an existing PC-based browser interface to a wireless Palm Pilot and cell phone. We wanted to allow our field personnel to use a very simple tool—cell phones—to access the database. Our first challenge was to deliver driving directions to a patient's home on a browser-enabled cell phone or wireless Palm Pilot. By using our translator technology, we were able to take an existing web-based application (in this case a report with 150 columns of data) and adapt it using a new template to the wireless world. We ported to a WML interface in less than four hours, with no recoding of the business or database components (see Figure 4). We reproduced this feat using web clipping technology to the Palm VIIX. It took four hours because we were not familiar with WML or web clipping. The Yankee Group says there are up to 12 million potential users in the medical industry of wireless technology. The Web is our tool today, but we will soon witness an explosion of wireless interfaces. We would be shortsighted to have an architecture that would require any recoding of business components (see Figure 5).

Figure 4. Wireless Driving Directions
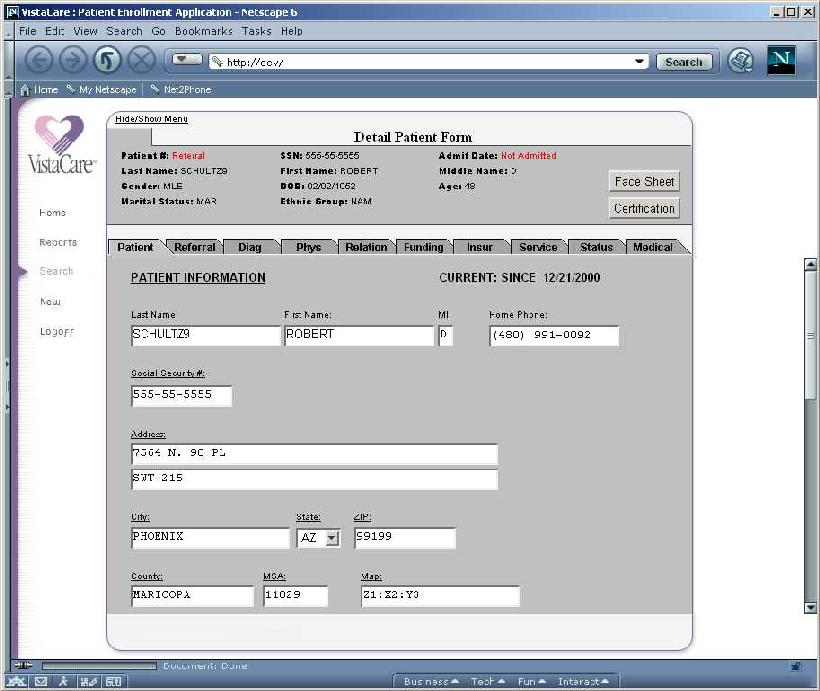
Figure 5. Patient Form
Interfaces and translators, which are part of the Communication Layer, package data for the business components. Interfaces and translators also format data that is sent back to the original client source. As one technique to format the data, the interpreter can use a template; for example, an HTML template could represent a classic master detail report.
Interfaces and translators enable developers to focus on the business logic without the distractions of how the data is formatted or presented. These translators can use a common stream of data coming from the business component and move it to virtually any front end: Web, IVR, wireless or even print streams.
More importantly, this allows reuse of components if the data client changes. Having the presentation and communication logic separate from the business logic speeds software development and allows for faster application deployment and updates. It also enables developers, particularly web and graphics programmers, to focus on the presentation without having to worry about the business logic or database I/O.
eTransMan uses a component software model. Data clients and other requesters invoke managed business components and developers design business components or modify their components by focusing on the business processes. This development strategy enables developers to build components quickly with their existing knowledge and skills.
We needed the ability to alter the availability of individual business components without affecting any other components. We found that this feature was missing from many of the commercial and open-source transaction platforms that we surveyed.
Health care's computing environments require administrative vigilance. Performance and security monitoring, failure and alert management, and a host of other operational tasks are more difficult in a distributed environment. We also designed web-based administration capabilities to bring eCommerce applications on-line and off-line. The easiest way to address this was to use the interface and translation layer to manage it through the Web. We use eTransMan to manage eTransMan (see Figure 6).
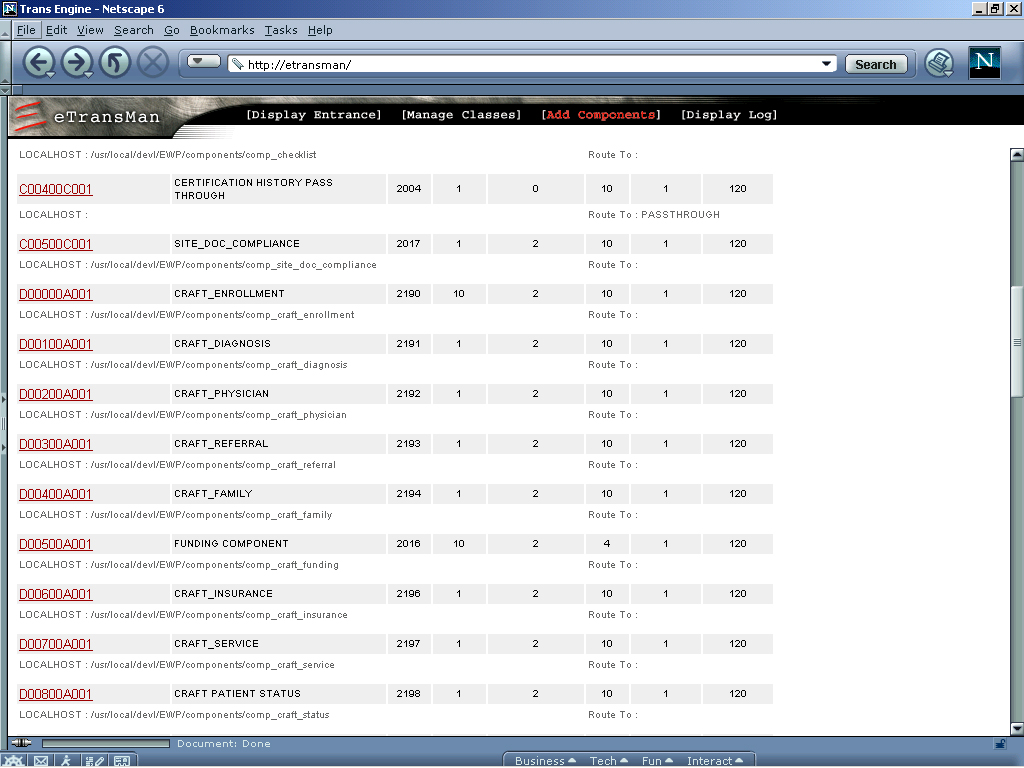
Figure 6. etransman_manage
eTransMan's Database Abstraction Layer provides a common interface for database interaction. This layer enables developers to interact with any database without modifying business component code.
The advantage of the Data Abstraction Layer is that a business component need not notice if the underlying data source changes, say from DB2 running on an IBM mainframe to Oracle running on Linux. Component programmers need not have their logic depend upon the specifics of a particular database. There are no SQL or HLLAPI manipulation routines in a component, for example. All of the data source access is through a specific component that translates generic requests into a format for a particular data source.
Unlike some transaction platforms that interact with a database using JDBC or ODBC, eTransMan can take advantage of the database's native libraries for database interaction. This engineering achieves fast database access with minimal overhead.
A metadata layer, stored and read by the component at instantiation, controls calling from the component to data access procedures for the database. This lets each software layer do what it does best: the database to read and write data, the application program to run business logic. This layered abstraction has already allowed us to move an application developed in one RDBMS to a different data layer.
Database Connection Pooling is a technique that minimizes the number of connections to a database. Database connections require intensive use of database and system resources. Frequent connection and disconnection leads to overall performance degradation. In high-transaction environments, connection pooling ensures that resources are used efficiently to optimize response times and data throughput.
Today, many database vendors license their products by the number of concurrent users, connections and/or number of power units based on MHz per processor on which the database is running. eTransMan helps maintain a low cost of ownership for their transaction platform by using only those system resources that are absolutely necessary to do the job.
If we were to connect our typical daily load of 200 on-line, we would need quite a fast machine full of RAM. However, we can support those 200 users with five pooled database connections, allowing eTransMan to predictively start more connections if required.
Our system provides high uptime. By building everything in redundant, restartable small components we can provide multiple paths for the application. Business components can be run on several servers if software redundancy is inadequate, providing reliability from even total server failure. eTransMan marks those components as unavailable and routes the business to another available server. Web servers already run this way, now the applications can, too.
Application requirements come and go. Businesses change, merge, get bought, get sold—nothing stays the same. We know we'll be running different business and database components in the future than the ones we're using today. With the right architecture we also know that we can make moves such as from Web to wireless without impacting the business components. The main lesson of this process is not to get locked in to a vendor, a technology, a predefined interface, a web server or to a database.
Gary Bennett (linuxrules@vista-care.com) is the director of IT for VistaCare, a hospice health-care company. He has over 17 years experience developing software in the medical, utility industry and military fields. When he is not looking over project Gantt charts he is looking over topo maps and planning backpacking trips in and around Arizona.

