
Saucy Administration Tools
Mais oui, François, a system administrator is very much like a restaurant owner and chef. There is far more to successful administration than simply making sure people can log on, just as there is more to the restaurant business than bringing plates of food to tables. We must constantly be on the lookout for exciting new recipes to tantalize our guests' palates. Our wine list must remain the finest in the land. And we must continue to provide impeccable service. This does not even take into consideration the dreadful dealings with la banque, non?
When we cook with Linux, we draw on as varied a skill set as when we prepare a new and exciting crèpe. The customer, mon ami, drives both the restaurateur and the system administrator.
Speaking of customers, our guests are here, François. Bonjour, mes ami. Come in. Sit down. François! Du vin! I think the 1982 Pauillac would be an excellent choice, n'est-ce pas? Today, mes amis, François and I were chatting about system administration in honour of our current issue. As you are well aware, part of the system administrator's job is keeping several different things on the go at all times. This includes system issues, software, hardware and people as well. Ah, people...the calls, the hustle, the bustle, your raison-d'ètre.
How can we make sense of all this? How can even the most highly trained system administrator keep up with the furious pace of calls that never stop coming? These are wonderful questions for which I hope to provide some answers.
For those of you using the K Desktop Environment, you may have already noticed a nice little tool called the Personal Time Tracker. You'll find it under the Utilities menu but can also execute it from the command line by simply typing karm. What the program allows you to do is create tasks that you can start, pause and restart at will. For system administrators who are working on multiple things at once (that would be all of us, non?) this is a way of keeping the clock ticking on various projects. Some of you will need to bill for services while others may just need to know where the time is going. Have a look at Figure 1 for a snapshot of KArm in action.
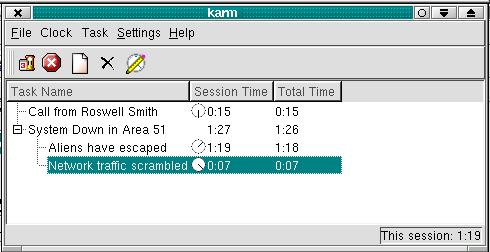
Figure 1. KArm Tracks the Seconds
Incidentally, the KDE time tracker is available in both the 1.X release and 2.X. However, for those of you using the new KDE 2.X release, the program does add some refinements like sub-tasks that track individually and cumulatively based on the master task. It is simple and easy to use.
Many times, I find that my thoughts seem altogether too random. There are a million things to do and finding some way to organize this mental traffic jam sometimes calls for a different approach.
ThoughtTracker is an interesting little program in that it lets you create seemingly random lists and cross-link them to other ideas so that you start to create some kind of organization out of those ideas. In some ways, it's a strange little program, but it may be worth a look. Think of it as a kind of brainstorming tool. The author is Marco Götze and, while I am at it, I would like to point out one other little program I found on his web site. Now, I did talk about little yellow stickies as a means of organization in the past, but Marco's take on it is interesting and maybe just a bit more fun.
Marco has also created a cool little WindowMaker applet (which I've run from both KDE and WindowMaker) called wmpinboard (see Figure 2). This is essentially a very small dock applet that looks like a corkboard. When you click on the ToDo label on the applet, you get colorful little notes that you can fill out and pin to the board. It's cute; it works. It takes up next to nothing in terms of space on your desktop. I must warn you, though, that your notes and reminders must be small as well.

Figure 2. The World's Smallest Corkboard?
The real heart of any system administration organization is the support desk, where young IT hopefuls sharpen their skills alongside the older, tougher, I-have-seen-it-all techies. Not only do the system administrators invariably and irrevocably find themselves involved in support, but in smaller organizations, they often are the support desk. Handling problems and dealing with a nonstop barrage of calls is probably more than can be efficiently handled by a few yellow stickies. The ideal is more along the lines of a system where calls are recorded through a user interface of some sort (a browser perhaps), problems are described, priorities are assigned, and the appropriate person is either dispatched or takes the call. Mes amis, your calls have been queued and answered. Please, sit, be comfortable. While François pours you another glass of wine, allow yourselves to savour these selections from tonight's menu.
The first recipe is something called IRM, which stands for Information Resource Manager. Written by Yann Ramin and Keith Schoenefeld, this package uses MySQL as its database. (You will need to be running an Apache web server with PHP4 extensions compiled in.) IRM is many things. First, it allows you to build a database of all the computers in your company or organization, organized in any way you see fit. This can include OS type, memory configuration, network card, IP addresses and more. There is also a separate list for network devices, hubs, cards and switches. Mais oui, you can add others as well. A similar function exists to record the software in your inventory (serial numbers, versions, etc.). You can then update the computer's profile by “adding” software so that when you click on that computer, it displays installed programs as well (useful when tracking licenses for that other OS).
What makes this listing of devices and software even more useful is that you can then enter trouble tickets (by clicking on Request Help) based on the devices or computers you have entered in your database. Then, using the Tracking function, you can assign the call to specific support representatives, and add follow-up information until such a time as the problem is resolved (marked “old”).
The reporting is fairly light as distributed, but IRM comes with information on creating your own custom reports. Keep in mind that since the package uses MySQL, you can also write your own queries ad hoc even without building it into the interface. For instance, you may want to have cron run a report of open calls each morning at 8:30.
Installing IRM is not difficult. You will, of course, need an Apache web server with the appropriate modules (PHP, MySQL). Then, you will need the IRM source which you can get from the web site (all addresses are in the Resources section at the end of this article). Here are the basic steps for installing IRM. Start by changing to your web server's document root:
cd /your_webserver_document_directory
(The above might be /usr/local/apache/htdocs or /home/httpd/html depending on your install)
tar -xzvf irm-1.0.2.tar.gzcd irm-1.0.2Notice that the application doesn't install itself into any other directory, so if you want to change the name (for your web access) then this is the time to do it. For example, rather than having users type the version number in their browser, I changed the name of the directory from irm-1.0.2 to irm with the mv command. Of course, if you are offering the URL from an intranet menu, it probably doesn't matter.
The next step is to edit the irm.inc file in your distribution directory. The only thing to change here is one line near the top of the file. In this example, I have already changed it using the path to my web server's document directory:
$root_path="/usr/local/apache/htdocs/irm";
Now, we need to create the database using the template provided with the IRM distribution. This is done by feeding the database.txt (in the docs directory) into the mysql command. Before you do this, use your favorite editor and add this single line to the top of the database.txt file:
use irm;We are almost finished. One last thing to do:
cd docsmysql -u root -p < database.txtYou will be asked for a password after which IRM's data structure will be created for you. You can now access the IRM system by using your web browser, http://yoursystem/irm/. At the login screen, enter your username and password. Figure 3 shows a screenshot of IRM's tracking system.
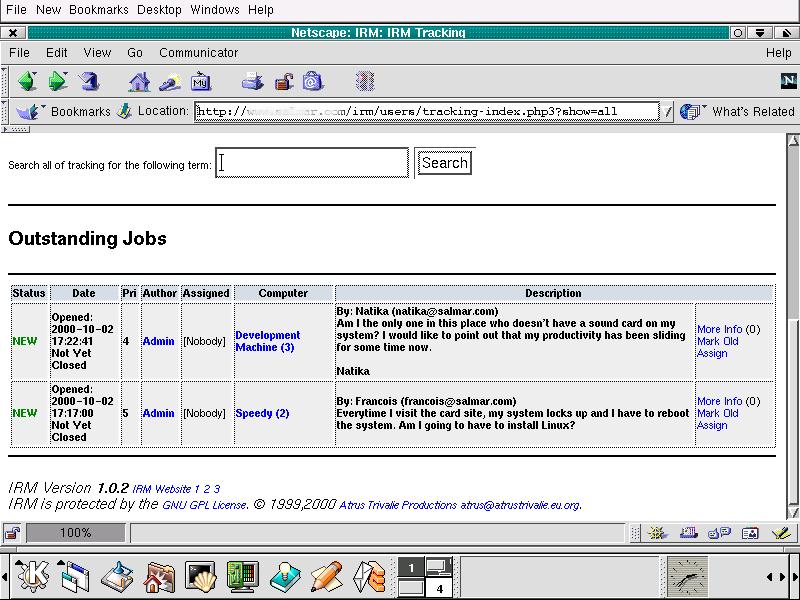
Figure 3. Trouble Tracking with IRM
The next package I would like you to sample is called Request Tracker. Request Tracker is the brainchild of Jesse Vincent, who, along with his faithful helpers, Deborah Kaplan and Mary Alderdice, has created a great support desk system. Unlike IRM, Request Tracker steers away from the complete inventory management model and concentrates on the support queue. Essentially, it focuses on the life cycle of a problem as submitted to any support desk. Calls come in, get assigned, worked on, then resolved and closed.
There are two browser-based interfaces to Request Tracker; an administrative screen and, the one in which you will be spending most of your time, the support queue. Using the administrative access, you can add new message queues. For instance, I created a separate queue for generic requests, one for hardware problems and one for application specific requests. You can also assign additional users and define their roles (administrative, post-only, etc.).
The main interface is the support queue itself. From there, it is possible to view requests, sort them according to personal or job preference, update, follow-up or close them. You can even set the queue to refresh on a regular basis so that you will always be aware of new calls coming in. Figure 4 provides a sample of the queue display's presentation.
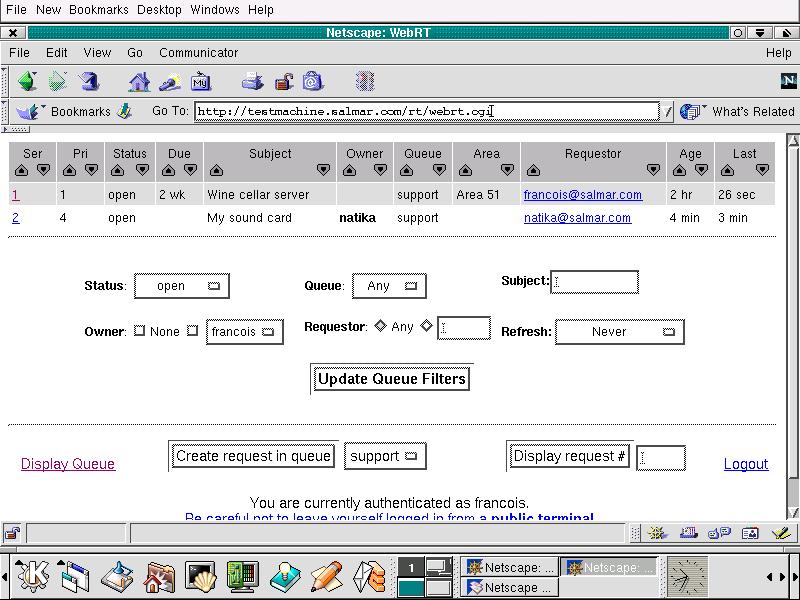
Figure 4. Request Tracker's Support Queue View
Request Tracker also uses MySQL to store its information, so that is a prerequisite. The program's access to the database is all Perl CGI rather than PHP, so you will need to get and install a couple of Perl modules. These are the MySQL/mSQL DBD module (available from www.mysql.org/downloads/api-dbi.html), the Digest::MD5 module and the CGI.pm module (both available from cpan.perl.org). It is best to get the latest version of these modules even if you have already installed them with an earlier release. I had some trouble due to the fact that my CGI.pm module was a bit, shall we say, aged. Good for wine, but not for software, non?
The format for installing any Perl modules is simple. The following dialog is pretty much the same no matter what package you are installing or what version you are using. From your downloaded source, extract and build your modules like this:
cd /usr/local/temp_dirtar -xzvf Perl-module-X.XX.tar.gz cd Perl-module perl Makefile.PL make make test make install
C'est simple. Now, you will need to install Request Tracker. First, you must download and extract the latest distribution from their web site. The current version was 1.0.4 when I did my install:
tar -xzvf rt.tar.gzcd rt-1.0.4You will need to create a user with id “rt” and group “rt”:
adduser rtUsing your favorite editor, open the Makefile and modify your local parameters. The Makefile is well documented, so read through it and make changes where necessary. In particular, you need to put in the host name of your system, what e-mail address support updates will be mailed to, and the MySQL admin login and passwords so that the install can create the Request Tracker database for you:
make installBefore you can use the package through the web interface, you will need to add a couple of lines to your httpd.conf file and restart Apache. Those lines are as follows:
Alias /webrt/ "/path/to/rt/lib/images/" ScriptAlias /rt/"/path/to/rt/bin/cgi/"To access Request Tracker's admin web interface, use this URL: http://rthost.yoursystem.com/rt/admin-webrt.cgi/.
The one user you have access to at this point is “root” and the password is “webpass”. You should change that immediately before creating additional users. For the support queue screen, simply change admin-webrt.cgi to webrt.cgi.
As I mentioned, both these help desk packages currently use MySQL as their database. For your humble chef, this meant spending a little time installing and configuring MySQL since PostgreSQL is the restaurant's database of choice. Databases often tend to be a matter of choice, a choice that may be based on familiarity, perceived ease of use, support, licensing or many other issues (such as inclusion on your Linux distribution disks). Recently, MySQL became fully GPLed so the licensing issues are no longer a factor, and Red Hat will be distributing it with release 7.0. Still, I am pleased that the authors of both these packages are working on developing their products so that future releases will support other databases, including my old friend, PostgreSQL.
The clock is saying that it is closing time yet again. I will have François refill your wine glasses a final time before you leave us. There will be taxis waiting in the back for the sysadmins. Seriously though, the support help desk can be a complicated, stressful and challenging environment. In some ways, I think it is an ideal place for future system administrators to hone their skills. The opportunity for learning is as enormous as the pace is dizzying. Today's features may be just what you need to slow that pace and allow you to organize your thoughts and tasks.
Until next time, your table will be waiting here at Chez Marcel.
A votre santé! Bon appétit!


